 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetailed comparison of communication efficiency of split learning and federated learning
Paper and Code
Sep 18, 2019
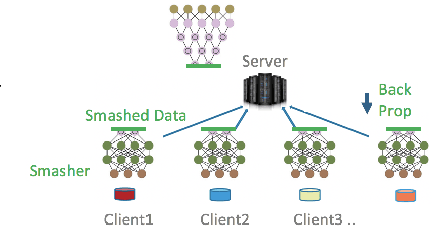
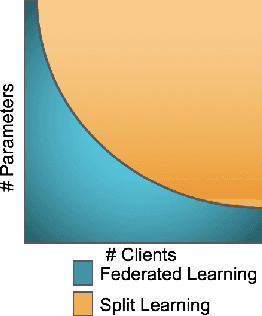
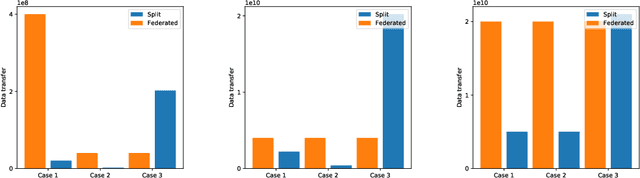
We compare communication efficiencies of two compelling distributed machine learning approaches of split learning and federated learning. We show useful settings under which each method outperforms the other in terms of communication efficiency. We consider various practical scenarios of distributed learning setup and juxtapose the two methods under various real-life scenarios. We consider settings of small and large number of clients as well as small models (1M - 6M parameters), large models (10M - 200M parameters) and very large models (1 Billion-100 Billion parameters). We show that increasing number of clients or increasing model size favors split learning setup over the federated while increasing the number of data samples while keeping the number of clients or model size low makes federated learning more communication efficient.