 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL-SR1: Learned Symmetric-Rank-One Preconditioning
Aug 17, 2025End-to-end deep learning has achieved impressive results but remains limited by its reliance on large labeled datasets, poor generalization to unseen scenarios, and growing computational demands. In contrast, classical optimization methods are data-efficient and lightweight but often suffer from slow convergence. While learned optimizers offer a promising fusion of both worlds, most focus on first-order methods, leaving learned second-order approaches largely unexplored. We propose a novel learned second-order optimizer that introduces a trainable preconditioning unit to enhance the classical Symmetric-Rank-One (SR1) algorithm. This unit generates data-driven vectors used to construct positive semi-definite rank-one matrices, aligned with the secant constraint via a learned projection. Our method is evaluated through analytic experiments and on the real-world task of Monocular Human Mesh Recovery (HMR), where it outperforms existing learned optimization-based approaches. Featuring a lightweight model and requiring no annotated data or fine-tuning, our approach offers strong generalization and is well-suited for integration into broader optimization-based frameworks.
CardioSpectrum: Comprehensive Myocardium Motion Analysis with 3D Deep Learning and Geometric Insights
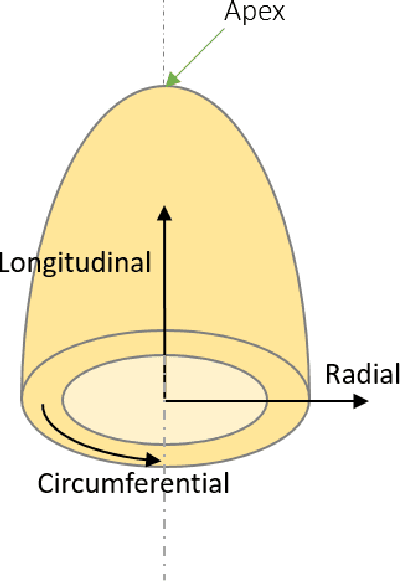
Jul 04, 2024The ability to map left ventricle (LV) myocardial motion using computed tomography angiography (CTA) is essential to diagnosing cardiovascular conditions and guiding interventional procedures. Due to their inherent locality, conventional neural networks typically have difficulty predicting subtle tangential movements, which considerably lessens the level of precision at which myocardium three-dimensional (3D) mapping can be performed. Using 3D optical flow techniques and Functional Maps (FMs), we present a comprehensive approach to address this problem. FMs are known for their capacity to capture global geometric features, thus providing a fuller understanding of 3D geometry. As an alternative to traditional segmentation-based priors, we employ surface-based two-dimensional (2D) constraints derived from spectral correspondence methods. Our 3D deep learning architecture, based on the ARFlow model, is optimized to handle complex 3D motion analysis tasks. By incorporating FMs, we can capture the subtle tangential movements of the myocardium surface precisely, hence significantly improving the accuracy of 3D mapping of the myocardium. The experimental results confirm the effectiveness of this method in enhancing myocardium motion analysis. This approach can contribute to improving cardiovascular diagnosis and treatment. Our code and additional resources are available at: https://shaharzuler.github.io/CardioSpectrumPage
Synthetic Data Generation for 3D Myocardium Deformation Analysis
Jun 03, 2024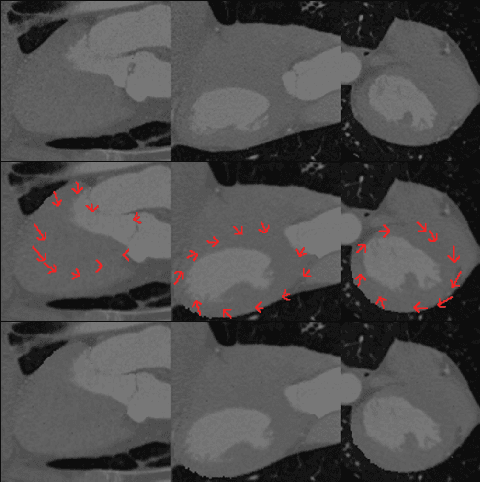

Accurate analysis of 3D myocardium deformation using high-resolution computerized tomography (CT) datasets with ground truth (GT) annotations is crucial for advancing cardiovascular imaging research. However, the scarcity of such datasets poses a significant challenge for developing robust myocardium deformation analysis models. To address this, we propose a novel approach to synthetic data generation for enriching cardiovascular imaging datasets. We introduce a synthetic data generation method, enriched with crucial GT 3D optical flow annotations. We outline the data preparation from a cardiac four-dimensional (4D) CT scan, selection of parameters, and the subsequent creation of synthetic data from the same or other sources of 3D cardiac CT data for training. Our work contributes to overcoming the limitations imposed by the scarcity of high-resolution CT datasets with precise annotations, thereby facilitating the development of accurate and reliable myocardium deformation analysis algorithms for clinical applications and diagnostics. Our code is available at: http://www.github.com/shaharzuler/cardio_volume_skewer
Temporal Super-Resolution using Multi-Channel Illumination Source
Nov 25, 2022



While sensing in high temporal resolution is necessary for wide range of application, it is still limited nowadays due to cameras sampling rate. In this work we try to increase the temporal resolution beyond the Nyquist frequency, which is limited by the sampling rate of the sensor. This work establishes a novel approach for Temporal-Super-Resolution that uses the object reflecting properties from an active illumination source to go beyond this limit. Following theoretical derivation, we demonstrate how we can increase the temporal spectral detected range by a factor of 6 and possibly even more. Our method is supported by simulations and experiments and we demonstrate as an application, how we use our method to improve in about factor two the accuracy of object motion estimation.
Illumination-Based Color Reconstruction for the Dynamic Vision Sensor
Nov 12, 2022



This work demonstrates a novel, state of the art method to reconstruct colored images via the Dynamic Vision Sensor (DVS). The DVS is an image sensor that indicates only a binary change in brightness, with no information about the captured wavelength (color), or intensity level. We present a novel method to reconstruct a full spatial resolution colored image with the DVS and an active colored light source. We analyze the DVS response and present two reconstruction algorithms: Linear based and Convolutional Neural Network Based. In addition, we demonstrate our algorithm robustness to changes in environmental conditions such as illumination and distance. Finally, comparing with previous works, we show how we reach the state of the art results.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022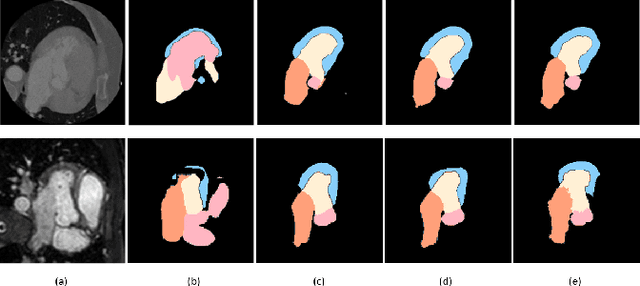
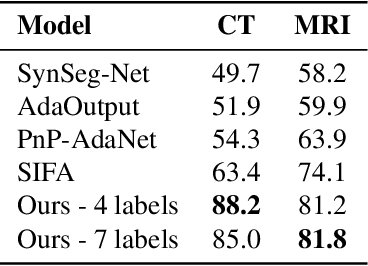


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
Deep Confidence Guided Distance for 3D Partial Shape Registration
Jan 27, 2022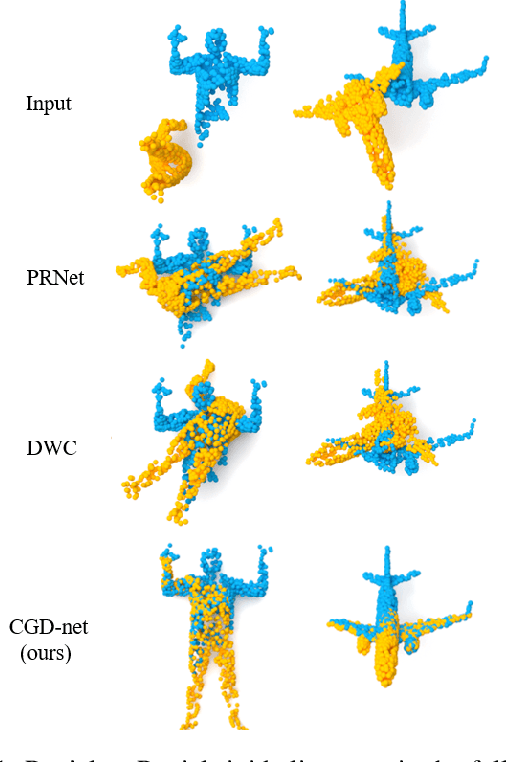
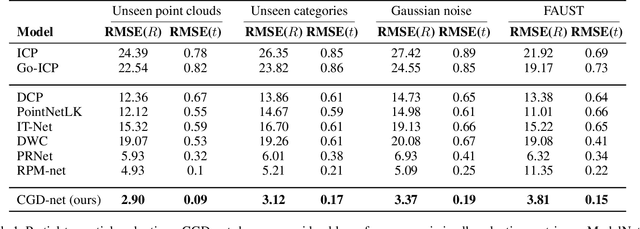
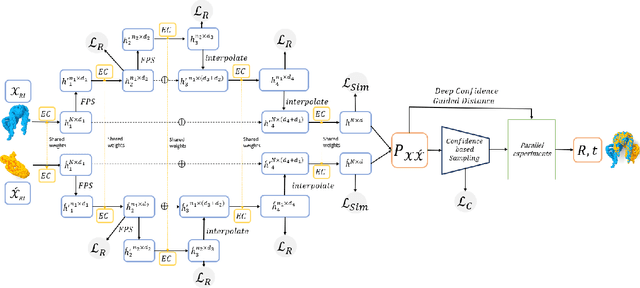
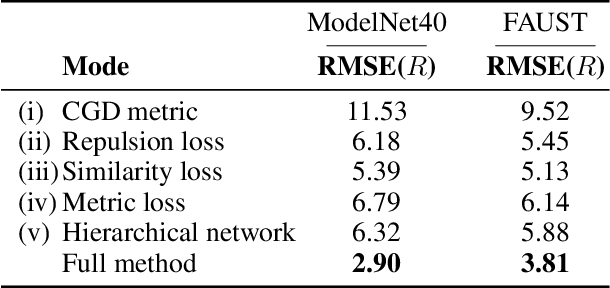
We present a novel non-iterative learnable method for partial-to-partial 3D shape registration. The partial alignment task is extremely complex, as it jointly tries to match between points and identify which points do not appear in the corresponding shape, causing the solution to be non-unique and ill-posed in most cases. Until now, two principal methodologies have been suggested to solve this problem: sample a subset of points that are likely to have correspondences or perform soft alignment between the point clouds and try to avoid a match to an occluded part. These heuristics work when the partiality is mild or when the transformation is small but fails for severe occlusions or when outliers are present. We present a unique approach named Confidence Guided Distance Network (CGD-net), where we fuse learnable similarity between point embeddings and spatial distance between point clouds, inducing an optimized solution for the overlapping points while ignoring parts that only appear in one of the shapes. The point feature generation is done by a self-supervised architecture that repels far points to have different embeddings, therefore succeeds to align partial views of shapes, even with excessive internal symmetries or acute rotations. We compare our network to recently presented learning-based and axiomatic methods and report a fundamental boost in performance.
Learn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021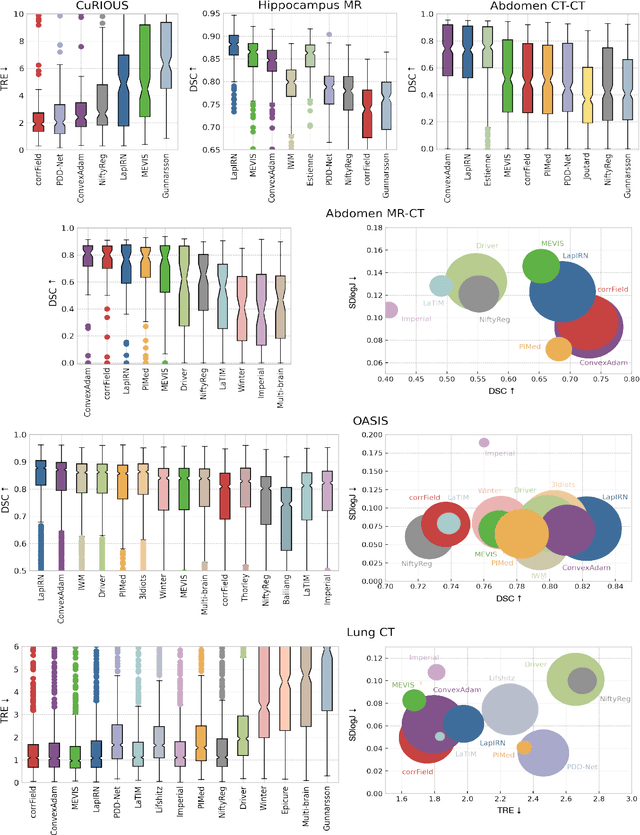
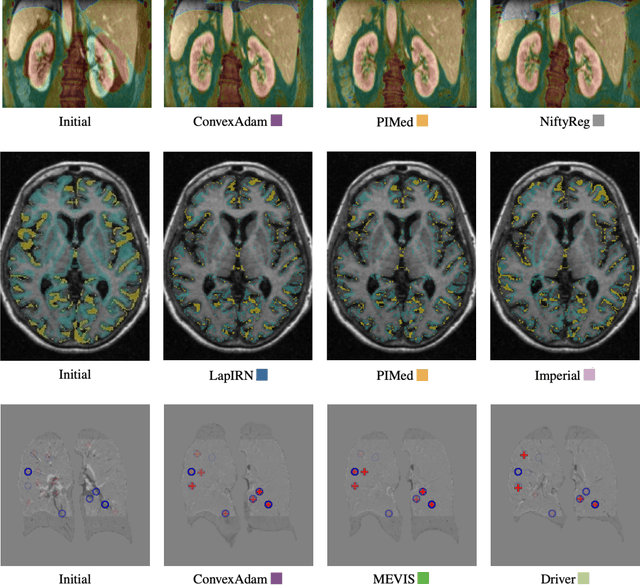
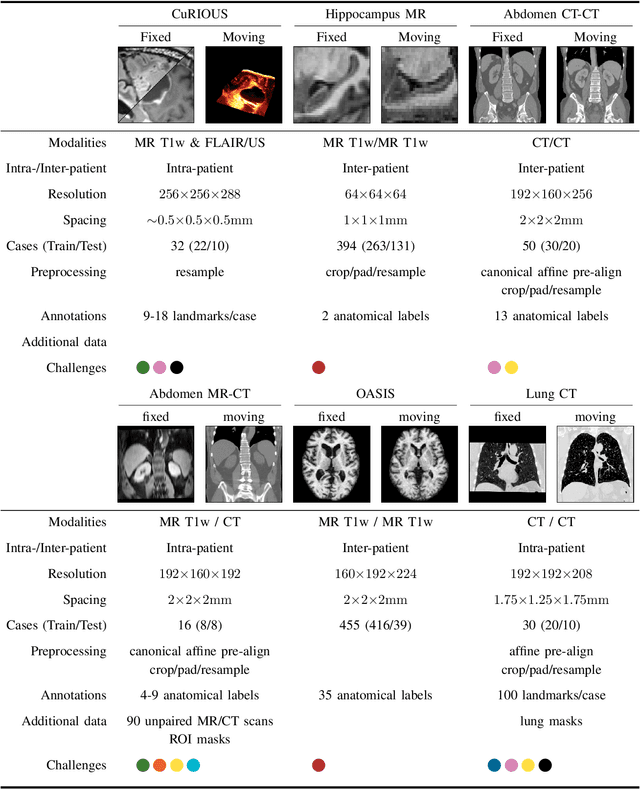
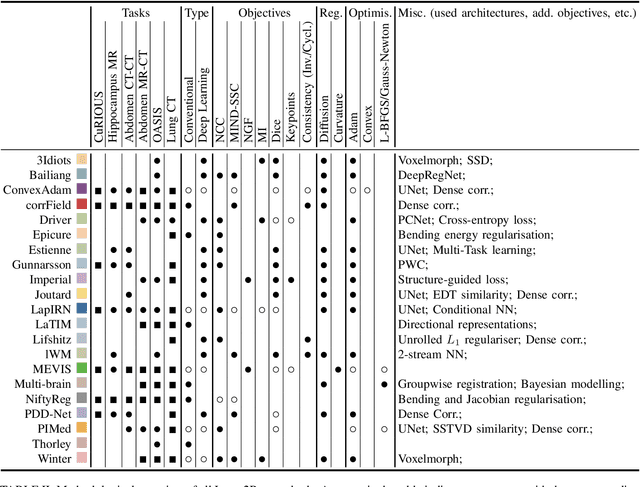
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.
DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction
Oct 16, 2021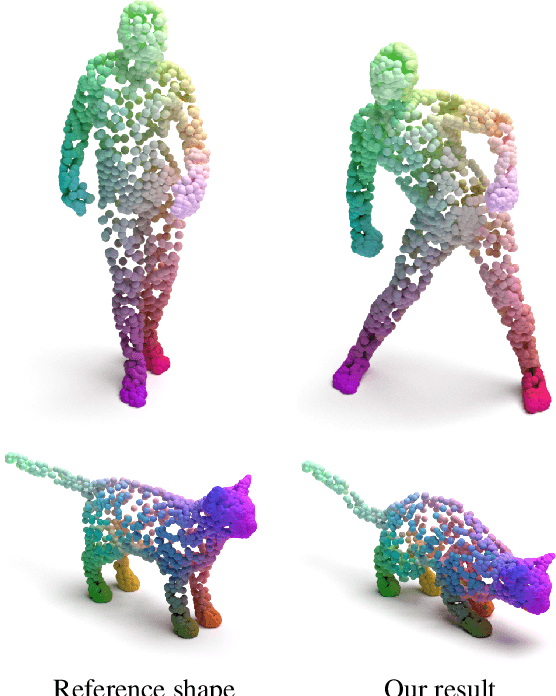
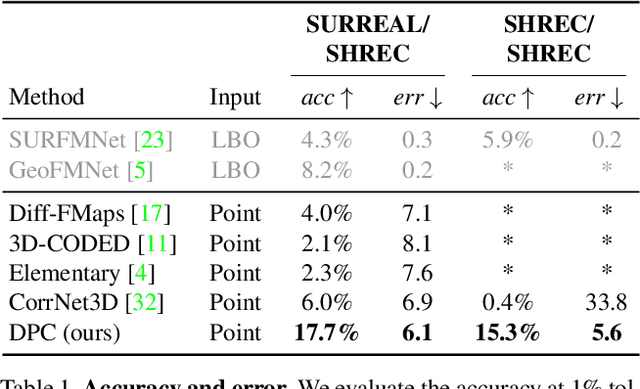
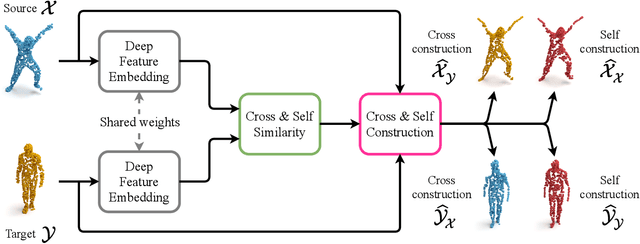
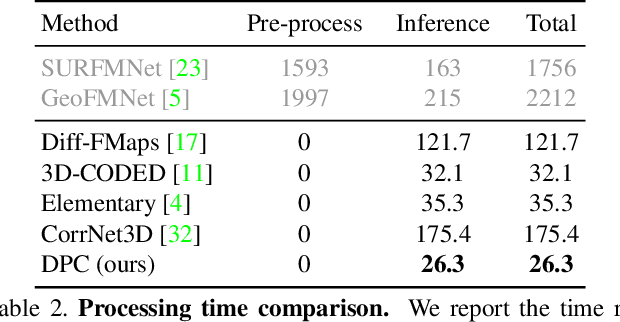
We present a new method for real-time non-rigid dense correspondence between point clouds based on structured shape construction. Our method, termed Deep Point Correspondence (DPC), requires a fraction of the training data compared to previous techniques and presents better generalization capabilities. Until now, two main approaches have been suggested for the dense correspondence problem. The first is a spectral-based approach that obtains great results on synthetic datasets but requires mesh connectivity of the shapes and long inference processing time while being unstable in real-world scenarios. The second is a spatial approach that uses an encoder-decoder framework to regress an ordered point cloud for the matching alignment from an irregular input. Unfortunately, the decoder brings considerable disadvantages, as it requires a large amount of training data and struggles to generalize well in cross-dataset evaluations. DPC's novelty lies in its lack of a decoder component. Instead, we use latent similarity and the input coordinates themselves to construct the point cloud and determine correspondence, replacing the coordinate regression done by the decoder. Extensive experiments show that our construction scheme leads to a performance boost in comparison to recent state-of-the-art correspondence methods. Our code is publicly available at https://github.com/dvirginz/DPC.
Deep Weighted Consensus: Dense correspondence confidence maps for 3D shape registration
May 06, 2021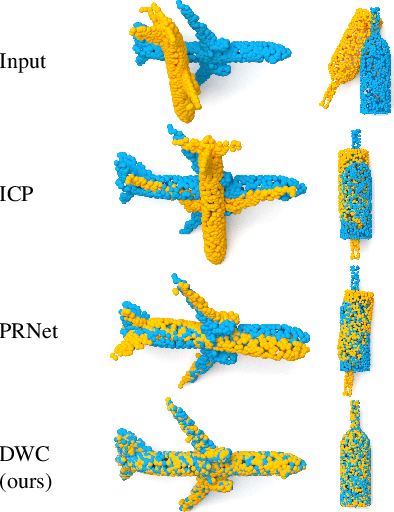
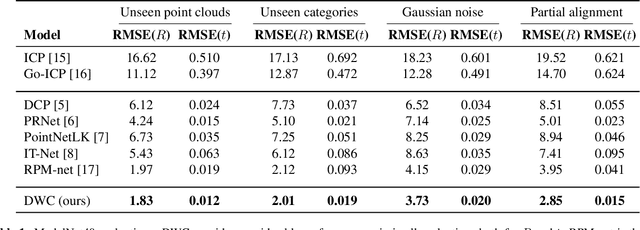
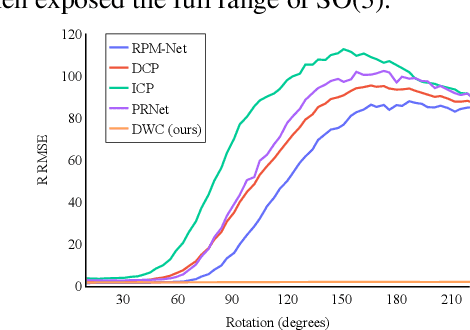
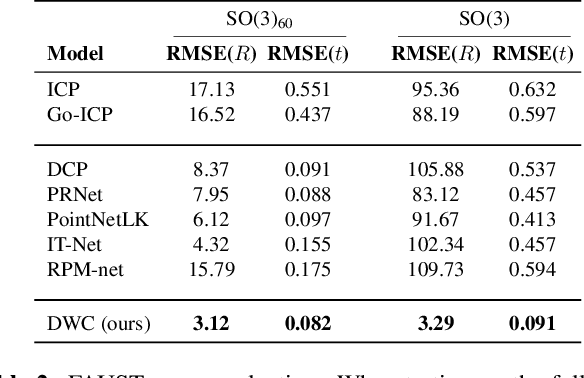
We present a new paradigm for rigid alignment between point clouds based on learnable weighted consensus which is robust to noise as well as the full spectrum of the rotation group. Current models, learnable or axiomatic, work well for constrained orientations and limited noise levels, usually by an end-to-end learner or an iterative scheme. However, real-world tasks require us to deal with large rotations as well as outliers and all known models fail to deliver. Here we present a different direction. We claim that we can align point clouds out of sampled matched points according to confidence level derived from a dense, soft alignment map. The pipeline is differentiable, and converges under large rotations in the full spectrum of SO(3), even with high noise levels. We compared the network to recently presented methods such as DCP, PointNetLK, RPM-Net, PRnet, and axiomatic methods such as ICP and Go-ICP. We report here a fundamental boost in performance.