 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end pipeline for simultaneous temperature estimation and super resolution of low-cost uncooled infrared camera frames for precision agriculture applications
Feb 18, 2025Radiometric infrared (IR) imaging is a valuable technique for remote-sensing applications in precision agriculture, such as irrigation monitoring, crop health assessment, and yield estimation. Low-cost uncooled non-radiometric IR cameras offer new implementations in agricultural monitoring. However, these cameras have inherent drawbacks that limit their usability, such as low spatial resolution, spatially variant nonuniformity, and lack of radiometric calibration. In this article, we present an end-to-end pipeline for temperature estimation and super resolution of frames captured by a low-cost uncooled IR camera. The pipeline consists of two main components: a deep-learning-based temperature-estimation module, and a deep-learning-based super-resolution module. The temperature-estimation module learns to map the raw gray level IR images to the corresponding temperature maps while also correcting for nonuniformity. The super-resolution module uses a deep-learning network to enhance the spatial resolution of the IR images by scale factors of x2 and x4. We evaluated the performance of the pipeline on both simulated and real-world agricultural datasets composing of roughly 20,000 frames of various crops. For the simulated data, the results were on par with the real-world data with sub-degree accuracy. For the real data, the proposed pipeline was compared to a high-end radiometric thermal camera, and achieved sub-degree accuracy. The results of the real data are on par with the simulated data. The proposed pipeline can enable various applications in precision agriculture that require high quality thermal information from low-cost IR cameras.
Person Recognition using Facial Micro-Expressions with Deep Learning
Jun 24, 2023This study investigates the efficacy of facial micro-expressions as a soft biometric for enhancing person recognition, aiming to broaden the understanding of the subject and its potential applications. We propose a deep learning approach designed to capture spatial semantics and motion at a fine temporal resolution. Experiments on three widely-used micro-expression databases demonstrate a notable increase in identification accuracy compared to existing benchmarks, highlighting the potential of integrating facial micro-expressions for improved person recognition across various fields.
Temporal Super-Resolution using Multi-Channel Illumination Source
Nov 25, 2022



While sensing in high temporal resolution is necessary for wide range of application, it is still limited nowadays due to cameras sampling rate. In this work we try to increase the temporal resolution beyond the Nyquist frequency, which is limited by the sampling rate of the sensor. This work establishes a novel approach for Temporal-Super-Resolution that uses the object reflecting properties from an active illumination source to go beyond this limit. Following theoretical derivation, we demonstrate how we can increase the temporal spectral detected range by a factor of 6 and possibly even more. Our method is supported by simulations and experiments and we demonstrate as an application, how we use our method to improve in about factor two the accuracy of object motion estimation.
Illumination-Based Color Reconstruction for the Dynamic Vision Sensor
Nov 12, 2022



This work demonstrates a novel, state of the art method to reconstruct colored images via the Dynamic Vision Sensor (DVS). The DVS is an image sensor that indicates only a binary change in brightness, with no information about the captured wavelength (color), or intensity level. We present a novel method to reconstruct a full spatial resolution colored image with the DVS and an active colored light source. We analyze the DVS response and present two reconstruction algorithms: Linear based and Convolutional Neural Network Based. In addition, we demonstrate our algorithm robustness to changes in environmental conditions such as illumination and distance. Finally, comparing with previous works, we show how we reach the state of the art results.
Skeleon-Based Typing Style Learning For Person Identification
Dec 06, 2020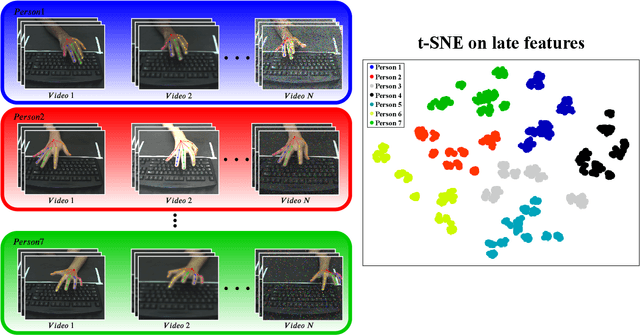



We present a novel architecture for person identification based on typing-style, constructed of adaptive non-local spatio-temporal graph convolutional network. Since type style dynamics convey meaningful information that can be useful for person identification, we extract the joints positions and then learn their movements' dynamics. Our non-local approach increases our model's robustness to noisy input data while analyzing joints locations instead of RGB data provides remarkable robustness to alternating environmental conditions, e.g., lighting, noise, etc. We further present two new datasets for typing style based person identification task and extensive evaluation that displays our model's superior discriminative and generalization abilities, when compared with state-of-the-art skeleton-based models.
Deep Sparse Light Field Refocusing
Sep 05, 2020
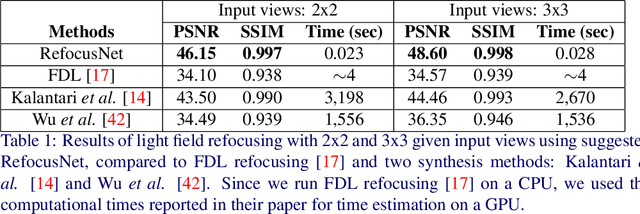
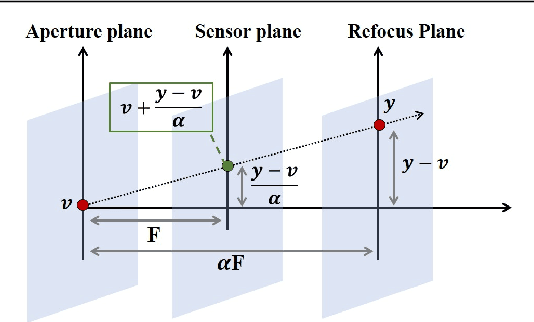
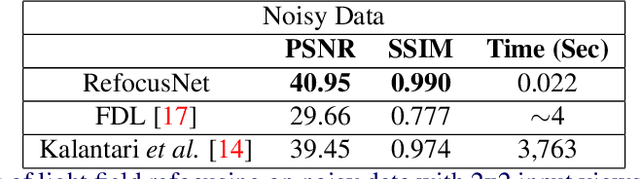
Light field photography enables to record 4D images, containing angular information alongside spatial information of the scene. One of the important applications of light field imaging is post-capture refocusing. Current methods require for this purpose a dense field of angle views; those can be acquired with a micro-lens system or with a compressive system. Both techniques have major drawbacks to consider, including bulky structures and angular-spatial resolution trade-off. We present a novel implementation of digital refocusing based on sparse angular information using neural networks. This allows recording high spatial resolution in favor of the angular resolution, thus, enabling to design compact and simple devices with improved hardware as well as better performance of compressive systems. We use a novel convolutional neural network whose relatively small structure enables fast reconstruction with low memory consumption. Moreover, it allows handling without re-training various refocusing ranges and noise levels. Results show major improvement compared to existing methods.
Face Authentication from Grayscale Coded Light Field
May 31, 2020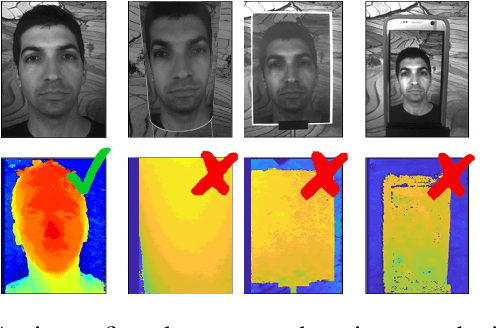

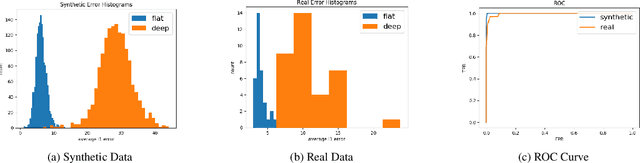

Face verification is a fast-growing authentication tool for everyday systems, such as smartphones. While current 2D face recognition methods are very accurate, it has been suggested recently that one may wish to add a 3D sensor to such solutions to make them more reliable and robust to spoofing, e.g., using a 2D print of a person's face. Yet, this requires an additional relatively expensive depth sensor. To mitigate this, we propose a novel authentication system, based on slim grayscale coded light field imaging. We provide a reconstruction free fast anti-spoofing mechanism, working directly on the coded image. It is followed by a multi-view, multi-modal face verification network that given grayscale data together with a low-res depth map achieves competitive results to the RGB case. We demonstrate the effectiveness of our solution on a simulated 3D (RGBD) version of LFW, which will be made public, and a set of real faces acquired by a light field computational camera.
Fast and Accurate Reconstruction of Compressed Color Light Field
Mar 28, 2018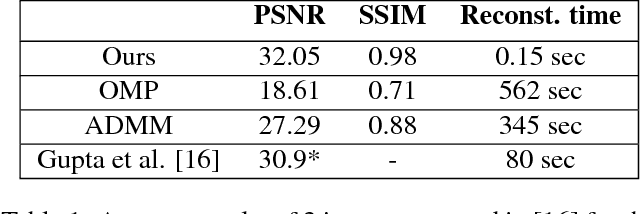
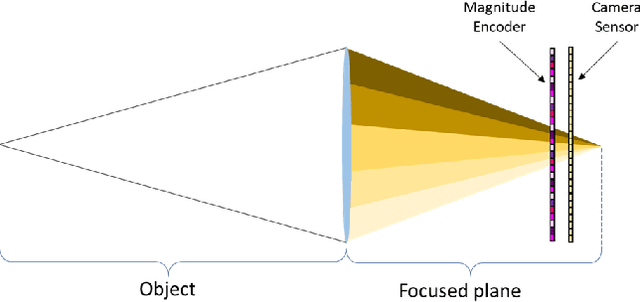
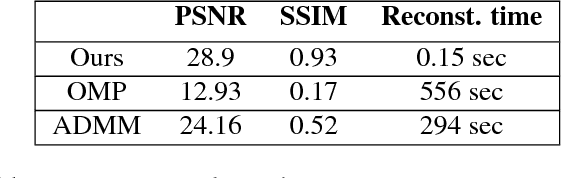
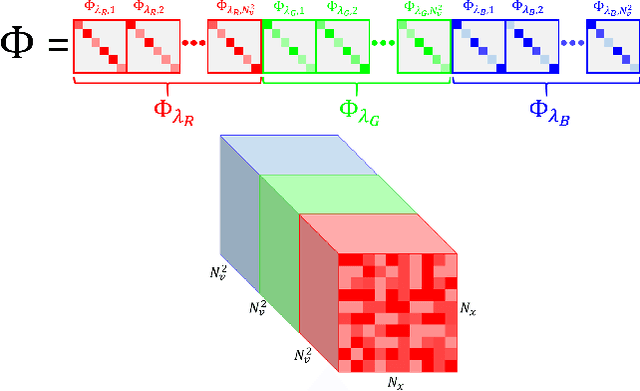
Light field photography has been studied thoroughly in recent years. One of its drawbacks is the need for multi-lens in the imaging. To compensate that, compressed light field photography has been proposed to tackle the trade-offs between the spatial and angular resolutions. It obtains by only one lens, a compressed version of the regular multi-lens system. The acquisition system consists of a dedicated hardware followed by a decompression algorithm, which usually suffers from high computational time. In this work, we propose a computationally efficient neural network that recovers a high-quality color light field from a single coded image. Unlike previous works, we compress the color channels as well, removing the need for a CFA in the imaging system. Our approach outperforms existing solutions in terms of recovery quality and computational complexity. We propose also a neural network for depth map extraction based on the decompressed light field, which is trained in an unsupervised manner without the ground truth depth map.