 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting BERT-based Text Similarity via Activation and Saliency Maps
Aug 13, 2022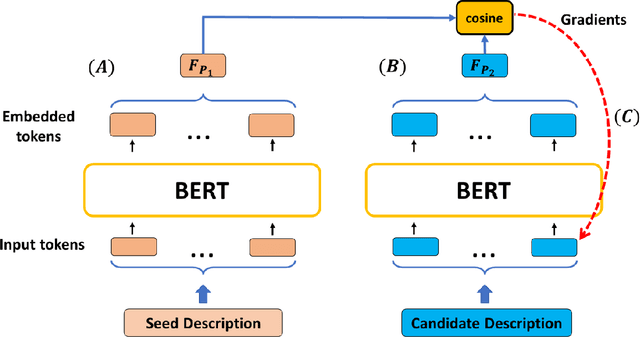
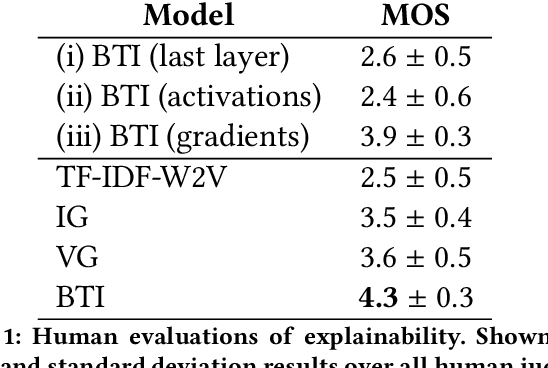
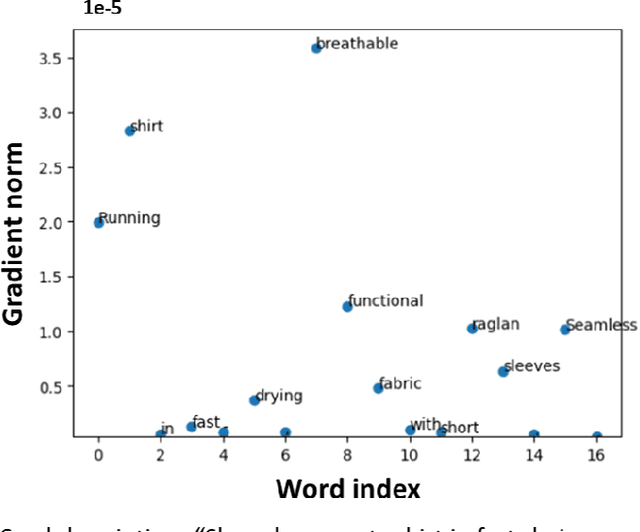
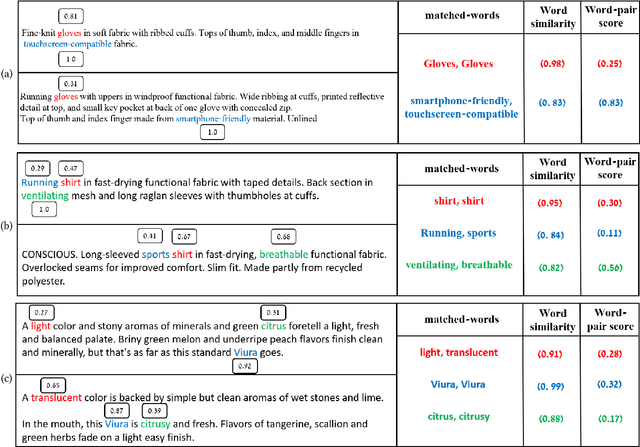
Recently, there has been growing interest in the ability of Transformer-based models to produce meaningful embeddings of text with several applications, such as text similarity. Despite significant progress in the field, the explanations for similarity predictions remain challenging, especially in unsupervised settings. In this work, we present an unsupervised technique for explaining paragraph similarities inferred by pre-trained BERT models. By looking at a pair of paragraphs, our technique identifies important words that dictate each paragraph's semantics, matches between the words in both paragraphs, and retrieves the most important pairs that explain the similarity between the two. The method, which has been assessed by extensive human evaluations and demonstrated on datasets comprising long and complex paragraphs, has shown great promise, providing accurate interpretations that correlate better with human perceptions.
MetricBERT: Text Representation Learning via Self-Supervised Triplet Training
Aug 13, 2022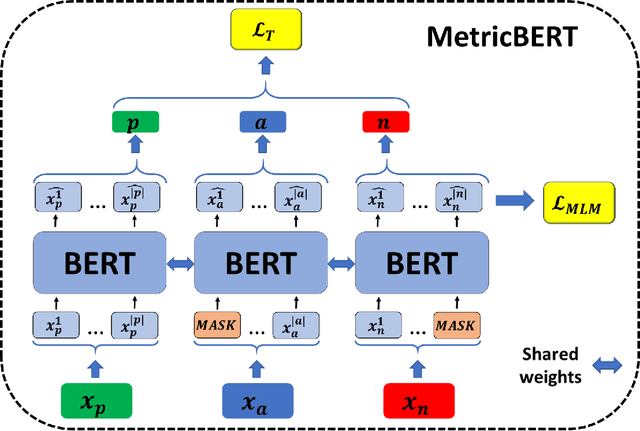

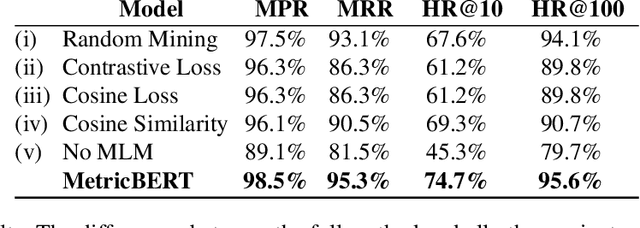
We present MetricBERT, a BERT-based model that learns to embed text under a well-defined similarity metric while simultaneously adhering to the ``traditional'' masked-language task. We focus on downstream tasks of learning similarities for recommendations where we show that MetricBERT outperforms state-of-the-art alternatives, sometimes by a substantial margin. We conduct extensive evaluations of our method and its different variants, showing that our training objective is highly beneficial over a traditional contrastive loss, a standard cosine similarity objective, and six other baselines. As an additional contribution, we publish a dataset of video games descriptions along with a test set of similarity annotations crafted by a domain expert.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022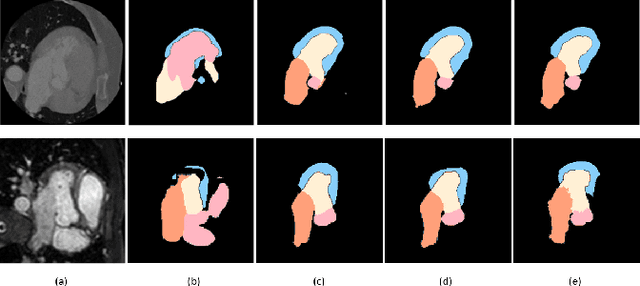
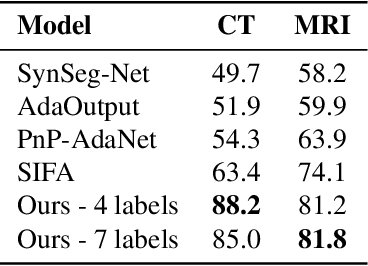


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
Deep Confidence Guided Distance for 3D Partial Shape Registration
Jan 27, 2022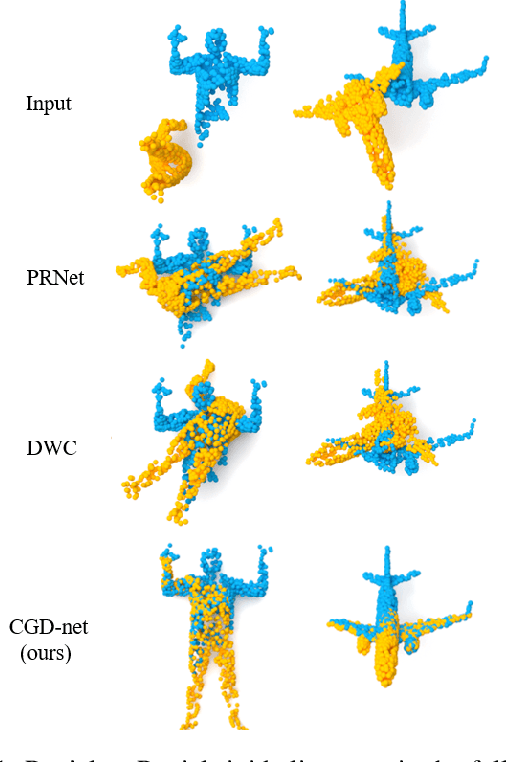
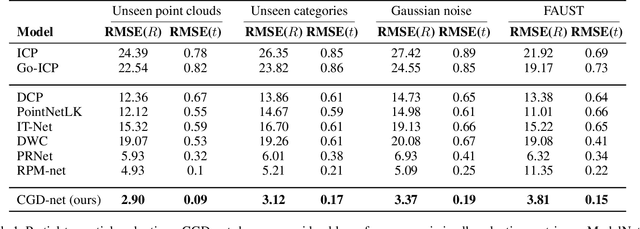
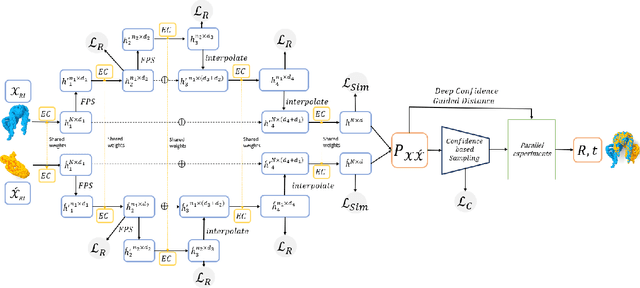
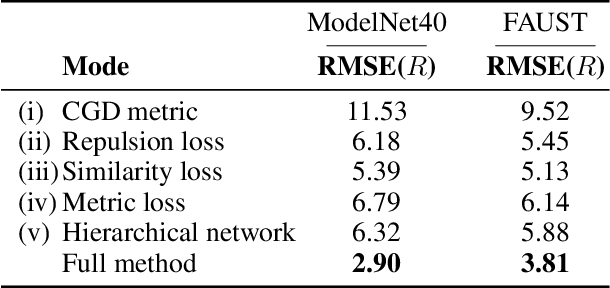
We present a novel non-iterative learnable method for partial-to-partial 3D shape registration. The partial alignment task is extremely complex, as it jointly tries to match between points and identify which points do not appear in the corresponding shape, causing the solution to be non-unique and ill-posed in most cases. Until now, two principal methodologies have been suggested to solve this problem: sample a subset of points that are likely to have correspondences or perform soft alignment between the point clouds and try to avoid a match to an occluded part. These heuristics work when the partiality is mild or when the transformation is small but fails for severe occlusions or when outliers are present. We present a unique approach named Confidence Guided Distance Network (CGD-net), where we fuse learnable similarity between point embeddings and spatial distance between point clouds, inducing an optimized solution for the overlapping points while ignoring parts that only appear in one of the shapes. The point feature generation is done by a self-supervised architecture that repels far points to have different embeddings, therefore succeeds to align partial views of shapes, even with excessive internal symmetries or acute rotations. We compare our network to recently presented learning-based and axiomatic methods and report a fundamental boost in performance.
DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction
Oct 16, 2021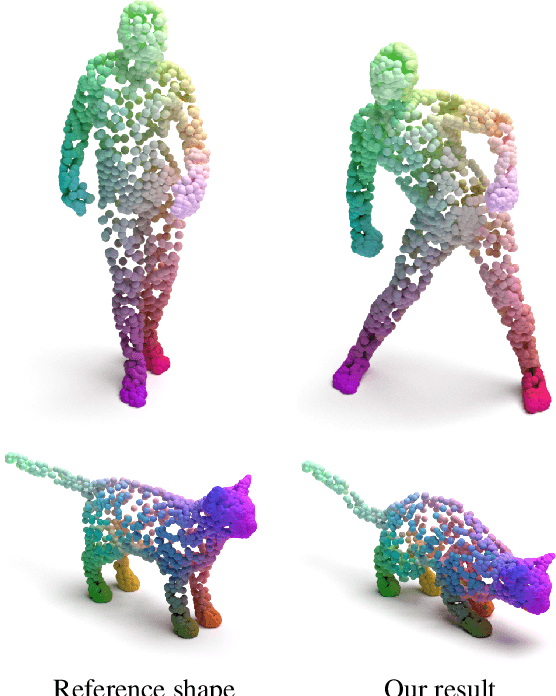
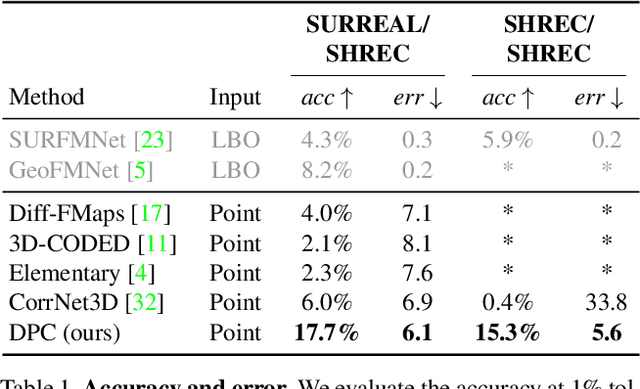
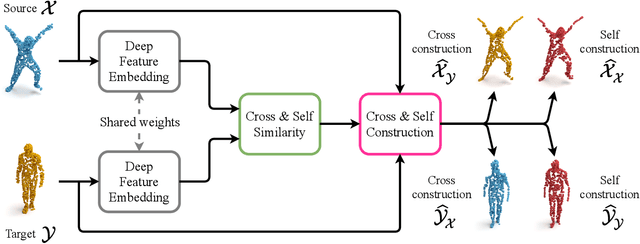
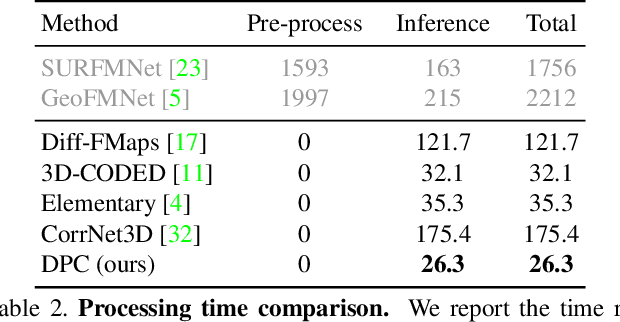
We present a new method for real-time non-rigid dense correspondence between point clouds based on structured shape construction. Our method, termed Deep Point Correspondence (DPC), requires a fraction of the training data compared to previous techniques and presents better generalization capabilities. Until now, two main approaches have been suggested for the dense correspondence problem. The first is a spectral-based approach that obtains great results on synthetic datasets but requires mesh connectivity of the shapes and long inference processing time while being unstable in real-world scenarios. The second is a spatial approach that uses an encoder-decoder framework to regress an ordered point cloud for the matching alignment from an irregular input. Unfortunately, the decoder brings considerable disadvantages, as it requires a large amount of training data and struggles to generalize well in cross-dataset evaluations. DPC's novelty lies in its lack of a decoder component. Instead, we use latent similarity and the input coordinates themselves to construct the point cloud and determine correspondence, replacing the coordinate regression done by the decoder. Extensive experiments show that our construction scheme leads to a performance boost in comparison to recent state-of-the-art correspondence methods. Our code is publicly available at https://github.com/dvirginz/DPC.
Self-Supervised Document Similarity Ranking via Contextualized Language Models and Hierarchical Inference
Jun 02, 2021
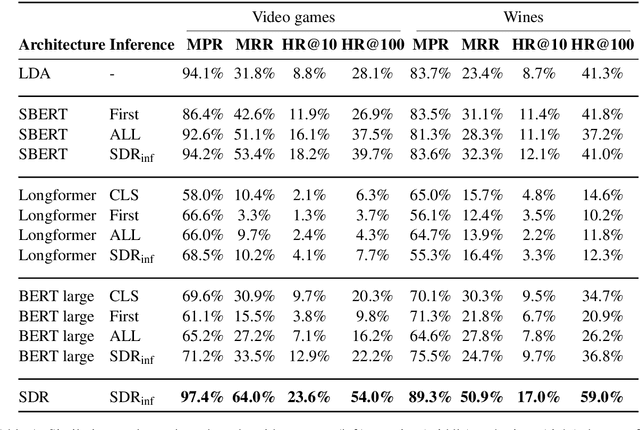
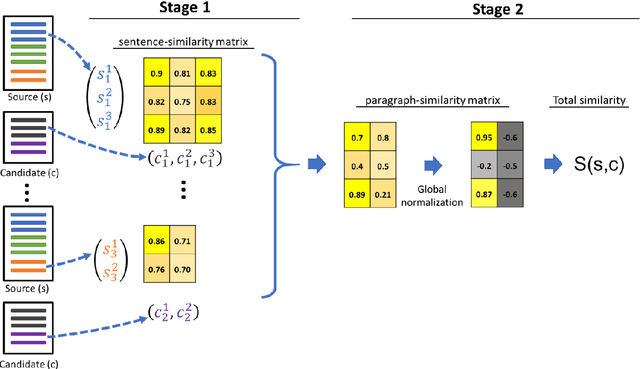
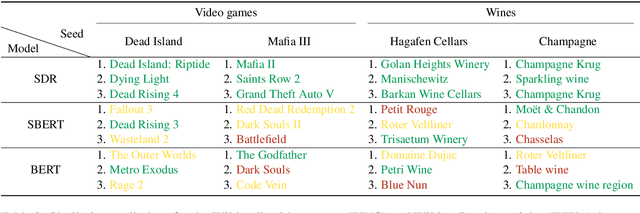
We present a novel model for the problem of ranking a collection of documents according to their semantic similarity to a source (query) document. While the problem of document-to-document similarity ranking has been studied, most modern methods are limited to relatively short documents or rely on the existence of "ground-truth" similarity labels. Yet, in most common real-world cases, similarity ranking is an unsupervised problem as similarity labels are unavailable. Moreover, an ideal model should not be restricted by documents' length. Hence, we introduce SDR, a self-supervised method for document similarity that can be applied to documents of arbitrary length. Importantly, SDR can be effectively applied to extremely long documents, exceeding the 4,096 maximal token limits of Longformer. Extensive evaluations on large document datasets show that SDR significantly outperforms its alternatives across all metrics. To accelerate future research on unlabeled long document similarity ranking, and as an additional contribution to the community, we herein publish two human-annotated test sets of long documents similarity evaluation. The SDR code and datasets are publicly available.
Deep Weighted Consensus: Dense correspondence confidence maps for 3D shape registration
May 06, 2021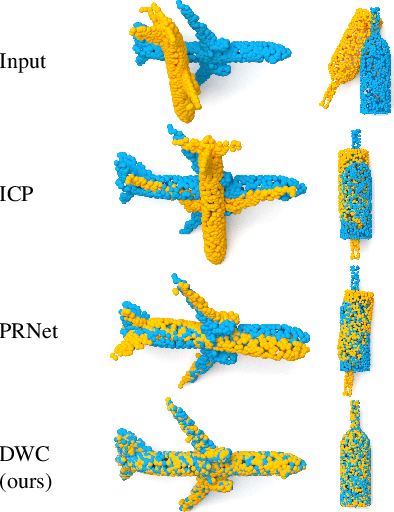
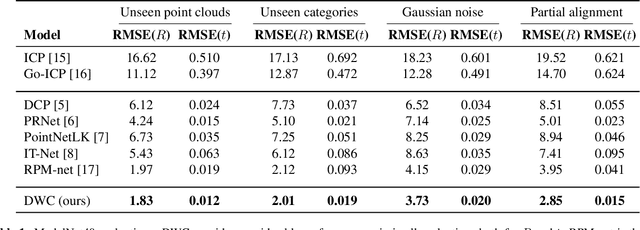
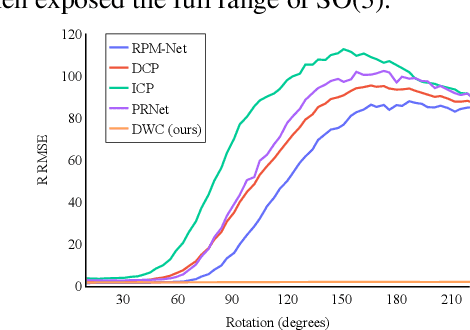
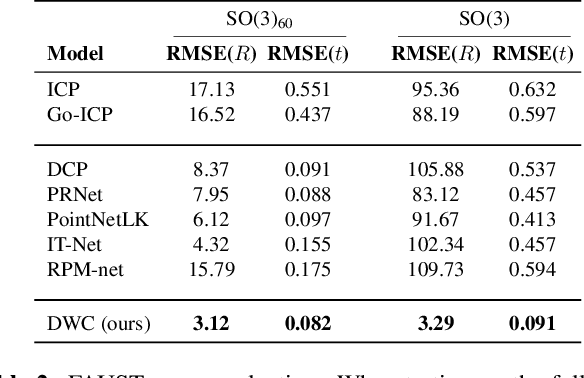
We present a new paradigm for rigid alignment between point clouds based on learnable weighted consensus which is robust to noise as well as the full spectrum of the rotation group. Current models, learnable or axiomatic, work well for constrained orientations and limited noise levels, usually by an end-to-end learner or an iterative scheme. However, real-world tasks require us to deal with large rotations as well as outliers and all known models fail to deliver. Here we present a different direction. We claim that we can align point clouds out of sampled matched points according to confidence level derived from a dense, soft alignment map. The pipeline is differentiable, and converges under large rotations in the full spectrum of SO(3), even with high noise levels. We compared the network to recently presented methods such as DCP, PointNetLK, RPM-Net, PRnet, and axiomatic methods such as ICP and Go-ICP. We report here a fundamental boost in performance.
Unsupervised Scale-Invariant Multispectral Shape Matching
Dec 19, 2020
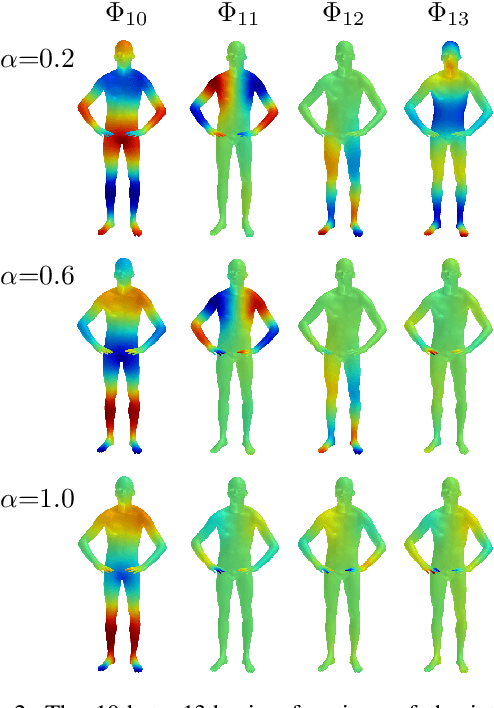

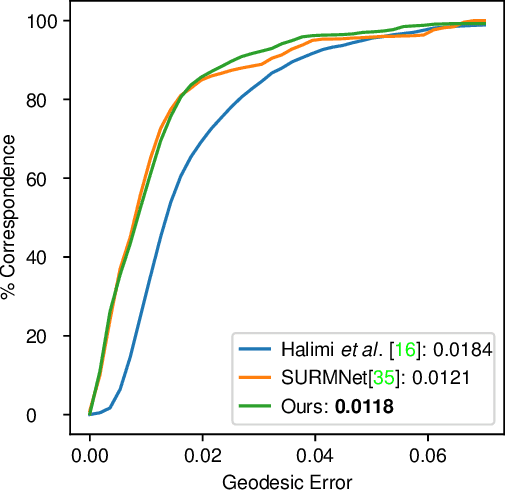
Alignment between non-rigid stretchable structures is one of the hardest tasks in computer vision, as the invariant properties are hard to define on one hand, and on the other hand no labelled data exists for real datasets. We present unsupervised neural network architecture based upon the spectrum of scale-invariant geometry. We build ontop the functional maps architecture, but show that learning local features, as done until now, is not enough once the isometric assumption breaks but can be solved using scale-invariant geometry. Our method is agnostic to local-scale deformations and shows superior performance for matching shapes from different domains when compared to existing spectral state-of-the-art solutions.
Dual Geometric Graph Network (DG2N) -- Zero-Shot Refinement for Dense Shape Correspondence
Nov 30, 2020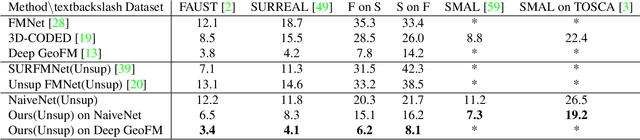
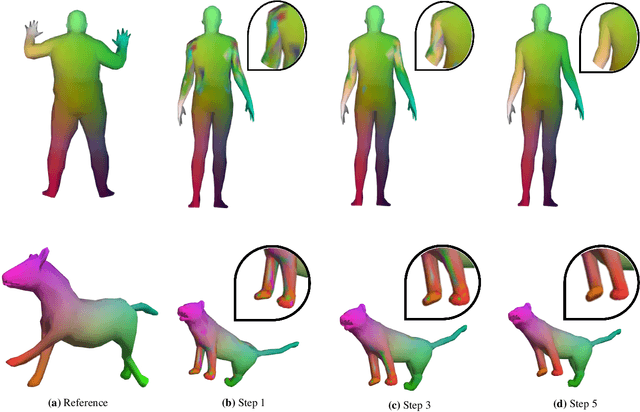
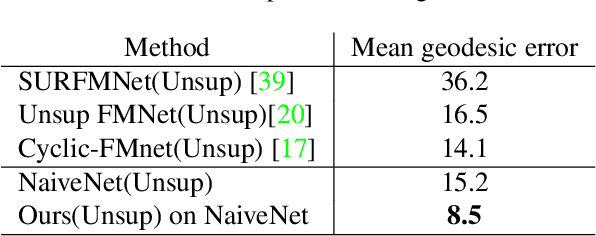
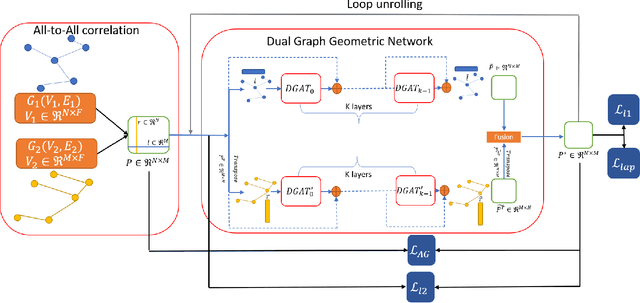
We provide a novel new approach for aligning geometric models using a dual graph structure where local features are mapping probabilities. Alignment of non-rigid structures is one of the most challenging computer vision tasks due to the high number of unknowns needed to model the correspondence. We have seen a leap forward using DNN models in template alignment and functional maps, but those methods fail for inter-class alignment where nonisometric deformations exist. Here we propose to rethink this task and use unrolling concepts on a dual graph structure - one for a forward map and one for a backward map, where the features are pulled back matching probabilities from the target into the source. We report state of the art results on stretchable domains alignment in a rapid and stable solution for meshes and cloud of points.
Cyclic Functional Mapping: Self-supervised correspondence between non-isometric deformable shapes
Dec 03, 2019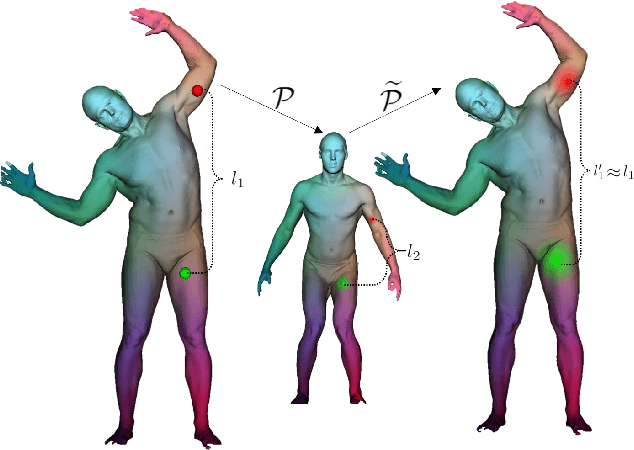
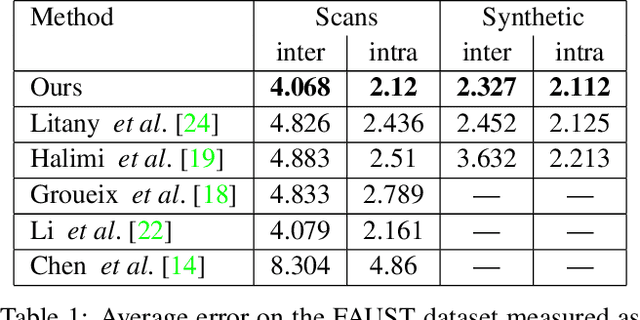
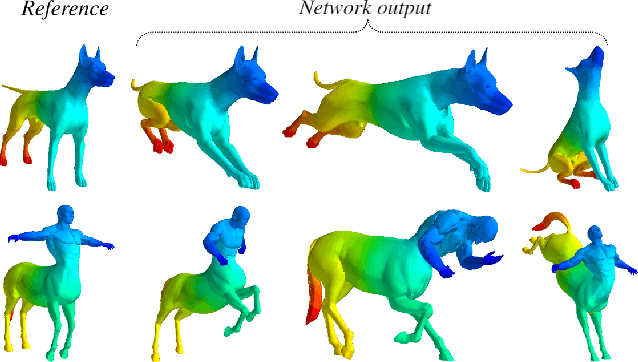
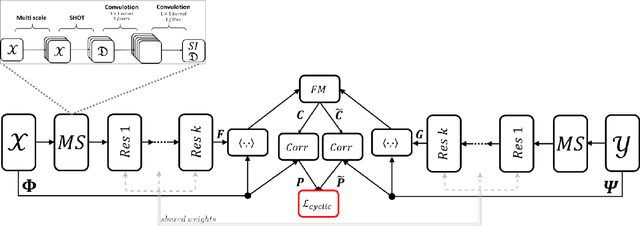
We present the first utterly self-supervised network for dense correspondence mapping between non-isometric shapes. The task of alignment in non-Euclidean domains is one of the most fundamental and crucial problems in computer vision. As 3D scanners can generate highly complex and dense models, the mission of finding dense mappings between those models is vital. The novelty of our solution is based on a cyclic mapping between metric spaces, where the distance between a pair of points should remain invariant after the full cycle. As the same learnable rules that generate the point-wise descriptors apply in both directions, the network learns invariant structures without any labels while coping with non-isometric deformations. We show here state-of-the-art-results by a large margin for a variety of tasks compared to known self-supervised and supervised methods.