 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Grounding In the Wild
Mar 27, 2026Reconstructing accurate 3D models of large-scale real-world scenes from unstructured, in-the-wild imagery remains a core challenge in computer vision, especially when the input views have little or no overlap. In such cases, existing reconstruction pipelines often produce multiple disconnected partial reconstructions or erroneously merge non-overlapping regions into overlapping geometry. In this work, we propose a framework that grounds each partial reconstruction to a complete reference model of the scene, enabling globally consistent alignment even in the absence of visual overlap. We obtain reference models from dense, geospatially accurate pseudo-synthetic renderings derived from Google Earth Studio. These renderings provide full scene coverage but differ substantially in appearance from real-world photographs. Our key insight is that, despite this significant domain gap, both domains share the same underlying scene semantics. We represent the reference model using 3D Gaussian Splatting, augmenting each Gaussian with semantic features, and formulate alignment as an inverse feature-based optimization scheme that estimates a global 6DoF pose and scale while keeping the reference model fixed. Furthermore, we introduce the WikiEarth dataset, which registers existing partial 3D reconstructions with pseudo-synthetic reference models. We demonstrate that our approach consistently improves global alignment when initialized with various classical and learning-based pipelines, while mitigating failure modes of state-of-the-art end-to-end models. All code and data will be released.
Multi-View Foundation Models
Dec 17, 2025



Foundation models are vital tools in various Computer Vision applications. They take as input a single RGB image and output a deep feature representation that is useful for various applications. However, in case we have multiple views of the same 3D scene, they operate on each image independently and do not always produce consistent features for the same 3D point. We propose a way to convert a Foundation Model into a Multi-View Foundation Model. Such a model takes as input a set of images and outputs a feature map for each image such that the features of corresponding points are as consistent as possible. This approach bypasses the need to build a consistent 3D model of the features and allows direct manipulation in the image space. Specifically, we show how to augment Transformers-based foundation models (i.e., DINO, SAM, CLIP) with intermediate 3D-aware attention layers that help match features across different views. As leading examples, we show surface normal estimation and multi-view segmentation tasks. Quantitative experiments show that our method improves feature matching considerably compared to current foundation models.
Frequency-Aware Gaussian Splatting Decomposition
Mar 27, 2025



3D Gaussian Splatting (3D-GS) has revolutionized novel view synthesis with its efficient, explicit representation. However, it lacks frequency interpretability, making it difficult to separate low-frequency structures from fine details. We introduce a frequency-decomposed 3D-GS framework that groups 3D Gaussians that correspond to subbands in the Laplacian Pyrmaids of the input images. Our approach enforces coherence within each subband (i.e., group of 3D Gaussians) through dedicated regularization, ensuring well-separated frequency components. We extend color values to both positive and negative ranges, allowing higher-frequency layers to add or subtract residual details. To stabilize optimization, we employ a progressive training scheme that refines details in a coarse-to-fine manner. Beyond interpretability, this frequency-aware design unlocks a range of practical benefits. Explicit frequency separation enables advanced 3D editing and stylization, allowing precise manipulation of specific frequency bands. It also supports dynamic level-of-detail control for progressive rendering, streaming, foveated rendering and fast geometry interaction. Through extensive experiments, we demonstrate that our method provides improved control and flexibility for emerging applications in scene editing and interactive rendering. Our code will be made publicly available.
Optimize the Unseen -- Fast NeRF Cleanup with Free Space Prior
Dec 18, 2024



Neural Radiance Fields (NeRF) have advanced photorealistic novel view synthesis, but their reliance on photometric reconstruction introduces artifacts, commonly known as "floaters". These artifacts degrade novel view quality, especially in areas unseen by the training cameras. We present a fast, post-hoc NeRF cleanup method that eliminates such artifacts by enforcing our Free Space Prior, effectively minimizing floaters without disrupting the NeRF's representation of observed regions. Unlike existing approaches that rely on either Maximum Likelihood (ML) estimation to fit the data or a complex, local data-driven prior, our method adopts a Maximum-a-Posteriori (MAP) approach, selecting the optimal model parameters under a simple global prior assumption that unseen regions should remain empty. This enables our method to clean artifacts in both seen and unseen areas, enhancing novel view quality even in challenging scene regions. Our method is comparable with existing NeRF cleanup models while being 2.5x faster in inference time, requires no additional memory beyond the original NeRF, and achieves cleanup training in less than 30 seconds. Our code will be made publically available.
VF-NeRF: Viewshed Fields for Rigid NeRF Registration
Apr 04, 2024



3D scene registration is a fundamental problem in computer vision that seeks the best 6-DoF alignment between two scenes. This problem was extensively investigated in the case of point clouds and meshes, but there has been relatively limited work regarding Neural Radiance Fields (NeRF). In this paper, we consider the problem of rigid registration between two NeRFs when the position of the original cameras is not given. Our key novelty is the introduction of Viewshed Fields (VF), an implicit function that determines, for each 3D point, how likely it is to be viewed by the original cameras. We demonstrate how VF can help in the various stages of NeRF registration, with an extensive evaluation showing that VF-NeRF achieves SOTA results on various datasets with different capturing approaches such as LLFF and Objaverese.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022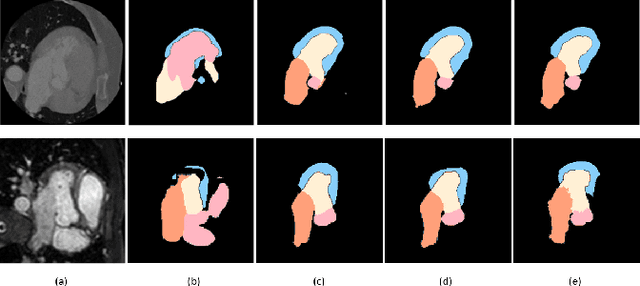
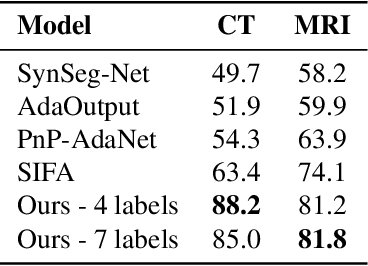


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.