 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetricBERT: Text Representation Learning via Self-Supervised Triplet Training
Aug 13, 2022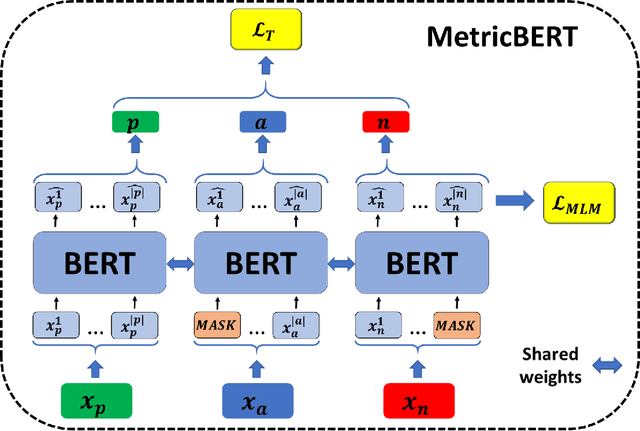

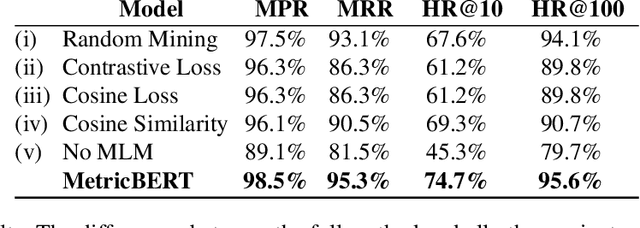
We present MetricBERT, a BERT-based model that learns to embed text under a well-defined similarity metric while simultaneously adhering to the ``traditional'' masked-language task. We focus on downstream tasks of learning similarities for recommendations where we show that MetricBERT outperforms state-of-the-art alternatives, sometimes by a substantial margin. We conduct extensive evaluations of our method and its different variants, showing that our training objective is highly beneficial over a traditional contrastive loss, a standard cosine similarity objective, and six other baselines. As an additional contribution, we publish a dataset of video games descriptions along with a test set of similarity annotations crafted by a domain expert.