 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Document Similarity Ranking via Contextualized Language Models and Hierarchical Inference
Paper and Code

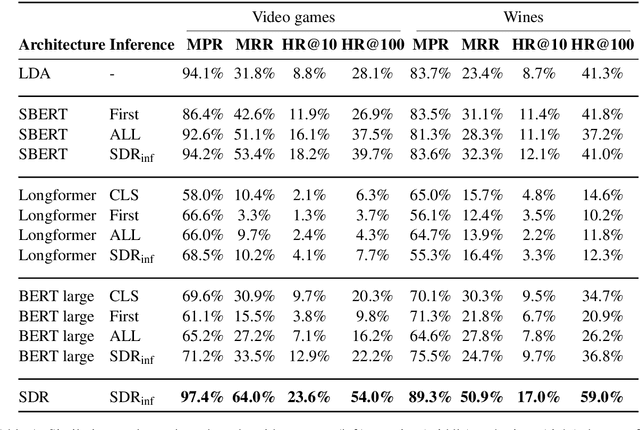
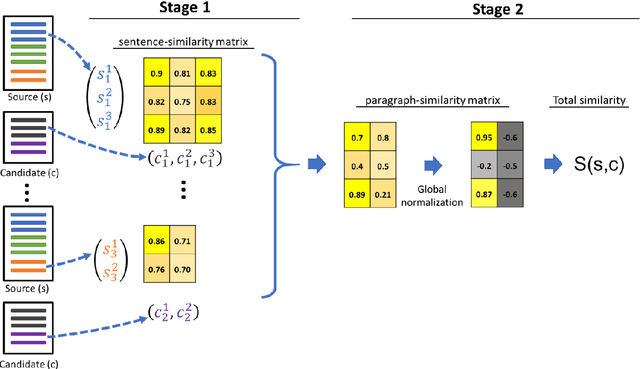
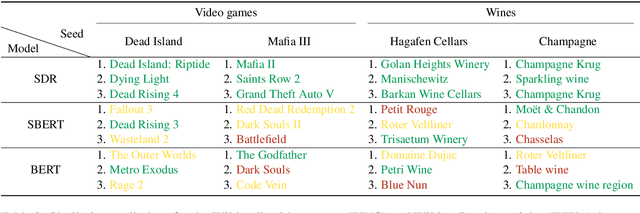
We present a novel model for the problem of ranking a collection of documents according to their semantic similarity to a source (query) document. While the problem of document-to-document similarity ranking has been studied, most modern methods are limited to relatively short documents or rely on the existence of "ground-truth" similarity labels. Yet, in most common real-world cases, similarity ranking is an unsupervised problem as similarity labels are unavailable. Moreover, an ideal model should not be restricted by documents' length. Hence, we introduce SDR, a self-supervised method for document similarity that can be applied to documents of arbitrary length. Importantly, SDR can be effectively applied to extremely long documents, exceeding the 4,096 maximal token limits of Longformer. Extensive evaluations on large document datasets show that SDR significantly outperforms its alternatives across all metrics. To accelerate future research on unlabeled long document similarity ranking, and as an additional contribution to the community, we herein publish two human-annotated test sets of long documents similarity evaluation. The SDR code and datasets are publicly available.