 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET -- Dual User Embedding Transformers for Offsite Conversion Prediction
Jun 08, 2026Offsite conversion rate (OCVR) prediction is an important ranking problem in computational recommendation systems. This task presents a modeling challenge: click signals are abundant and exhibit short temporal horizons, whereas conversion signals are inherently sparse, long-delayed, and frequently unattributed. Despite these statistical disparities, both signal types must inform models that operate within strict serving-latency constraints. Prior pre-training approaches address this heterogeneity with a single, undifferentiated encoder applied uniformly across both data streams. We propose DUET (Dual User Embedding Transformers), a framework that explicitly partitions user behavioral data into two domain-coherent streams -- clicks and conversions -- and pre-trains dedicated transformer encoders with architectures tailored to each stream's statistical characteristics: multi-layer self-attention for the dense click stream and interleaved cross- and self-attention for the sparse conversion stream. The resulting complementary embeddings are jointly consumed by a downstream ranker without exceeding serving-latency budgets. Evaluation demonstrates up to 0.38% normalized entropy (NE) reduction relative to the strongest baseline, and A/B test shows consistent improvements in OCVR prediction accuracy.
Viewpoint Recommendation for Point Cloud Labeling through Interaction Cost Modeling
Feb 11, 2026Semantic segmentation of 3D point clouds is important for many applications, such as autonomous driving. To train semantic segmentation models, labeled point cloud segmentation datasets are essential. Meanwhile, point cloud labeling is time-consuming for annotators, which typically involves tuning the camera viewpoint and selecting points by lasso. To reduce the time cost of point cloud labeling, we propose a viewpoint recommendation approach to reduce annotators' labeling time costs. We adapt Fitts' law to model the time cost of lasso selection in point clouds. Using the modeled time cost, the viewpoint that minimizes the lasso selection time cost is recommended to the annotator. We build a data labeling system for semantic segmentation of 3D point clouds that integrates our viewpoint recommendation approach. The system enables users to navigate to recommended viewpoints for efficient annotation. Through an ablation study, we observed that our approach effectively reduced the data labeling time cost. We also qualitatively compare our approach with previous viewpoint selection approaches on different datasets.
SYNBUILD-3D: A large, multi-modal, and semantically rich synthetic dataset of 3D building models at Level of Detail 4
Aug 28, 2025



3D building models are critical for applications in architecture, energy simulation, and navigation. Yet, generating accurate and semantically rich 3D buildings automatically remains a major challenge due to the lack of large-scale annotated datasets in the public domain. Inspired by the success of synthetic data in computer vision, we introduce SYNBUILD-3D, a large, diverse, and multi-modal dataset of over 6.2 million synthetic 3D residential buildings at Level of Detail (LoD) 4. In the dataset, each building is represented through three distinct modalities: a semantically enriched 3D wireframe graph at LoD 4 (Modality I), the corresponding floor plan images (Modality II), and a LiDAR-like roof point cloud (Modality III). The semantic annotations for each building wireframe are derived from the corresponding floor plan images and include information on rooms, doors, and windows. Through its tri-modal nature, future work can use SYNBUILD-3D to develop novel generative AI algorithms that automate the creation of 3D building models at LoD 4, subject to predefined floor plan layouts and roof geometries, while enforcing semantic-geometric consistency. Dataset and code samples are publicly available at https://github.com/kdmayer/SYNBUILD-3D.
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models
Jun 15, 2025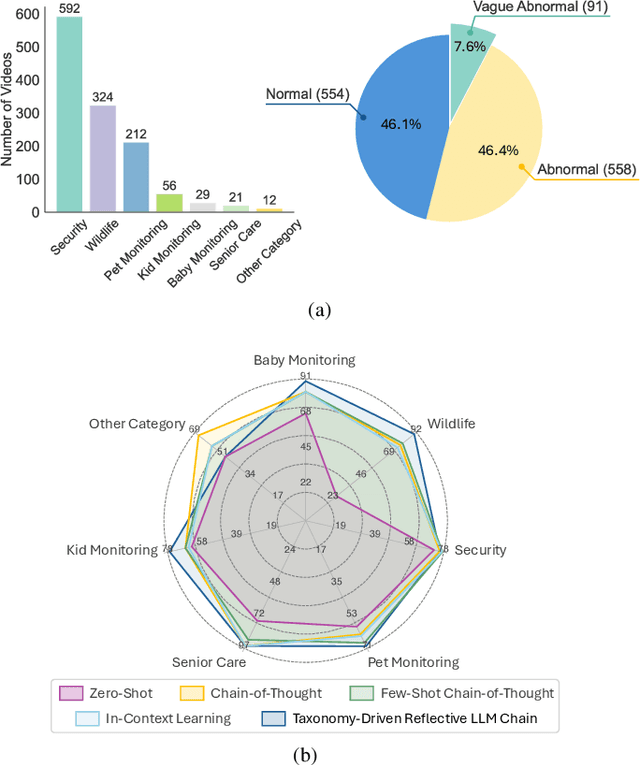
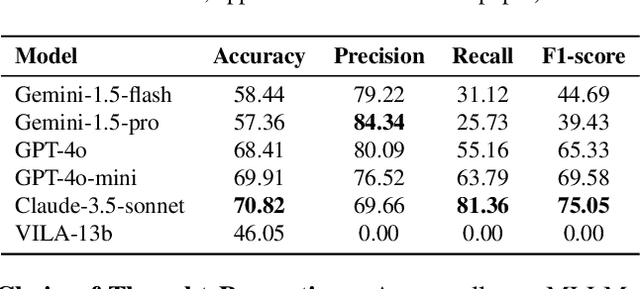

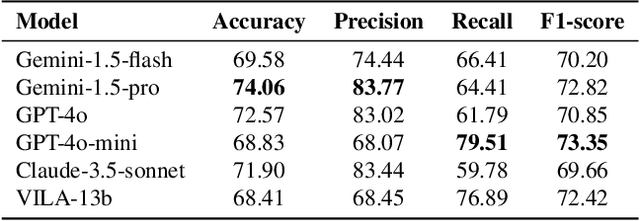
Video anomaly detection (VAD) is essential for enhancing safety and security by identifying unusual events across different environments. Existing VAD benchmarks, however, are primarily designed for general-purpose scenarios, neglecting the specific characteristics of smart home applications. To bridge this gap, we introduce SmartHome-Bench, the first comprehensive benchmark specially designed for evaluating VAD in smart home scenarios, focusing on the capabilities of multi-modal large language models (MLLMs). Our newly proposed benchmark consists of 1,203 videos recorded by smart home cameras, organized according to a novel anomaly taxonomy that includes seven categories, such as Wildlife, Senior Care, and Baby Monitoring. Each video is meticulously annotated with anomaly tags, detailed descriptions, and reasoning. We further investigate adaptation methods for MLLMs in VAD, assessing state-of-the-art closed-source and open-source models with various prompting techniques. Results reveal significant limitations in the current models' ability to detect video anomalies accurately. To address these limitations, we introduce the Taxonomy-Driven Reflective LLM Chain (TRLC), a new LLM chaining framework that achieves a notable 11.62% improvement in detection accuracy. The benchmark dataset and code are publicly available at https://github.com/Xinyi-0724/SmartHome-Bench-LLM.
Just read twice: closing the recall gap for recurrent language models
Jul 07, 2024



Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives $11.0 \pm 1.3$ points of improvement, averaged across $16$ recurrent LMs and the $6$ ICL tasks, with $11.9\times$ higher throughput than FlashAttention-2 for generation prefill (length $32$k, batch size $16$, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides $99\%$ of Transformer quality at $360$M params., $30$B tokens and $96\%$ at $1.3$B params., $50$B tokens on average across the tasks, with $19.2\times$ higher throughput for prefill than FA2.
Demystifying CNNs for Images by Matched Filters
Oct 16, 2022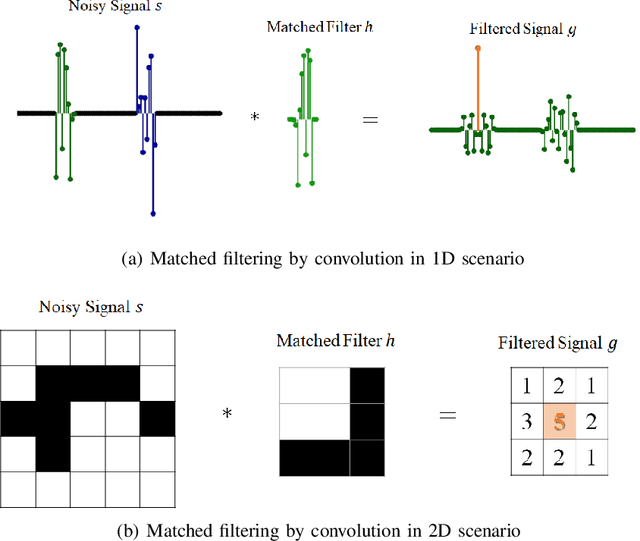
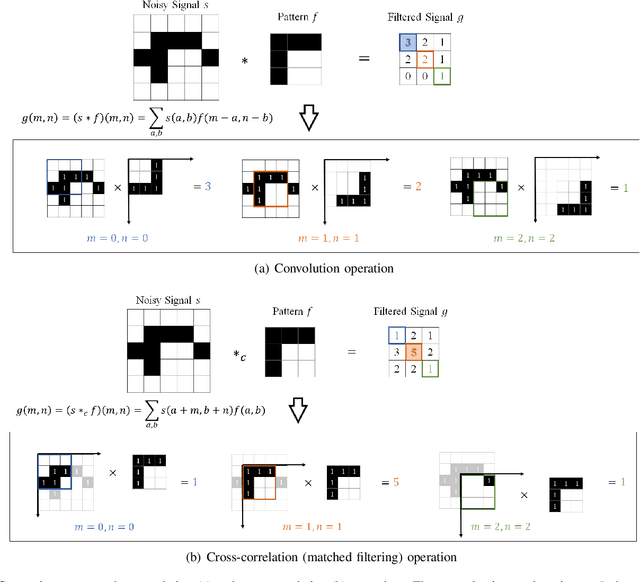
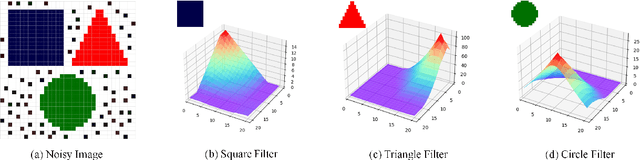
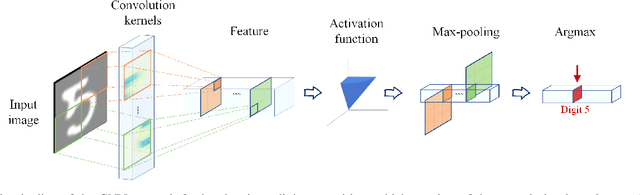
The success of convolution neural networks (CNN) has been revolutionising the way we approach and use intelligent machines in the Big Data era. Despite success, CNNs have been consistently put under scrutiny owing to their \textit{black-box} nature, an \textit{ad hoc} manner of their construction, together with the lack of theoretical support and physical meanings of their operation. This has been prohibitive to both the quantitative and qualitative understanding of CNNs, and their application in more sensitive areas such as AI for health. We set out to address these issues, and in this way demystify the operation of CNNs, by employing the perspective of matched filtering. We first illuminate that the convolution operation, the very core of CNNs, represents a matched filter which aims to identify the presence of features in input data. This then serves as a vehicle to interpret the convolution-activation-pooling chain in CNNs under the theoretical umbrella of matched filtering, a common operation in signal processing. We further provide extensive examples and experiments to illustrate this connection, whereby the learning in CNNs is shown to also perform matched filtering, which further sheds light onto physical meaning of learnt parameters and layers. It is our hope that this material will provide new insights into the understanding, constructing and analysing of CNNs, as well as paving the way for developing new methods and architectures of CNNs.
Data Budgeting for Machine Learning
Oct 03, 2022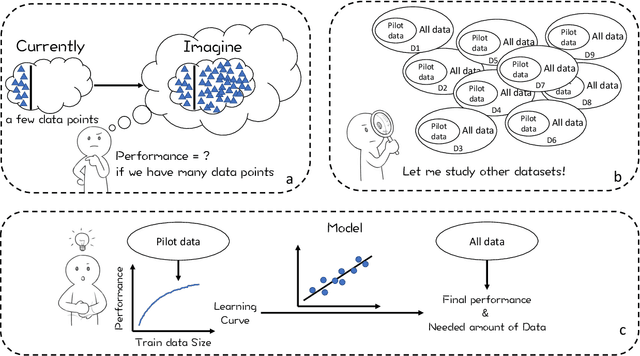


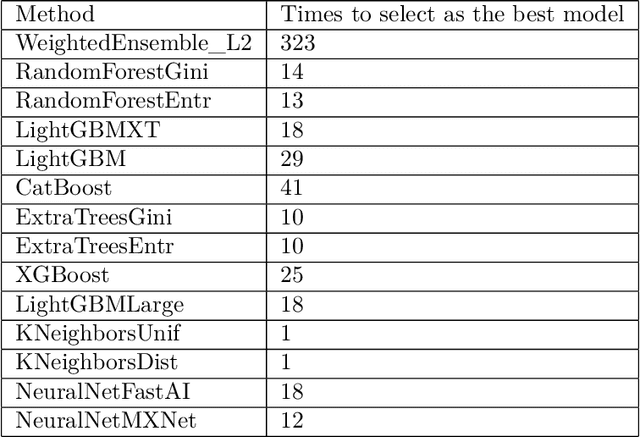
Data is the fuel powering AI and creates tremendous value for many domains. However, collecting datasets for AI is a time-consuming, expensive, and complicated endeavor. For practitioners, data investment remains to be a leap of faith in practice. In this work, we study the data budgeting problem and formulate it as two sub-problems: predicting (1) what is the saturating performance if given enough data, and (2) how many data points are needed to reach near the saturating performance. Different from traditional dataset-independent methods like PowerLaw, we proposed a learning method to solve data budgeting problems. To support and systematically evaluate the learning-based method for data budgeting, we curate a large collection of 383 tabular ML datasets, along with their data vs performance curves. Our empirical evaluation shows that it is possible to perform data budgeting given a small pilot study dataset with as few as $50$ data points.
Return migration of German-affiliated researchers: Analyzing departure and return by gender, cohort, and discipline using Scopus bibliometric data 1996-2020
Oct 15, 2021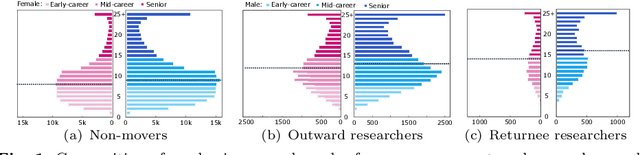

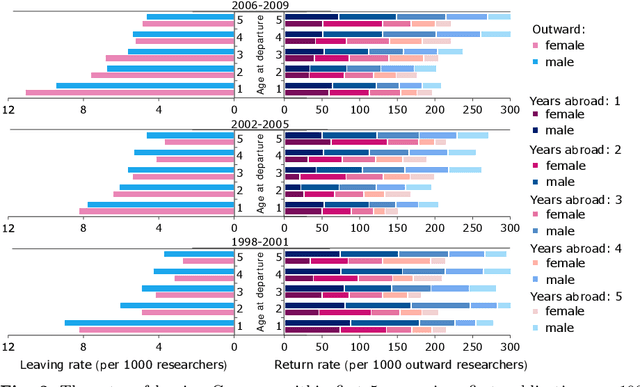
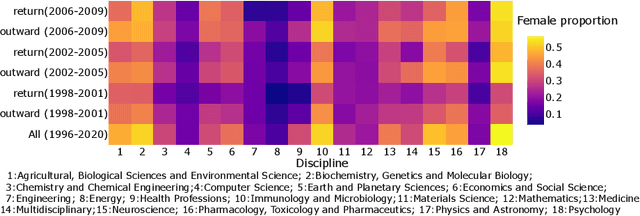
The international migration of researchers is a highly prized dimension of scientific mobility and motivates considerable policy debate. However, tracking migration life courses of researchers is challenging due to data limitations. In this study, we use Scopus bibliometric data on 8 million publications from 1.1 million researchers who have published at least once with an affiliation address from Germany in 1996-2020. We describe several key steps and algorithms we develop that enable us to construct the partial life histories of published researchers in this period. These tools allow us to explore both the out-migration of researchers with German affiliations as well as the subsequent return of a share of this group - the returnees. Our analyses shed light on important career stages and gender disparities between researchers who remain in Germany and those who both migrate out and those who eventually return. Return migration streams are even more gender imbalanced and point to the importance of additional efforts to attract female researchers back to Germany. We document a slightly declining trend in return migration with cohorts which, for most disciplines, is associated with decreasing German collaboration ties among cohorts of researchers who leave Germany. Also, gender disparities for the most gender imbalanced disciplines are unlikely to be mitigated by return migration given the gender compositions in cohorts of researchers who leave Germany and those who return. This analysis reveals new dimensions of scholarly migration by investigating the return migration of published researchers which is critical for science policy development.
Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition
Jul 26, 2018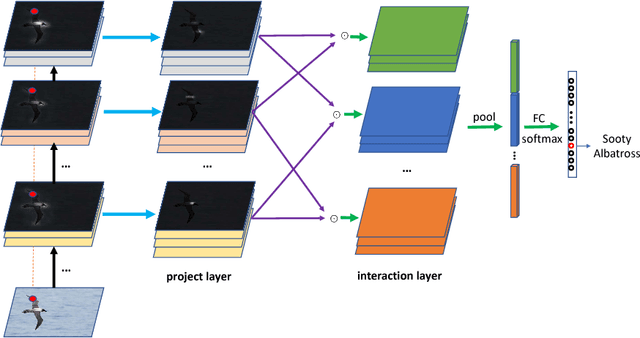
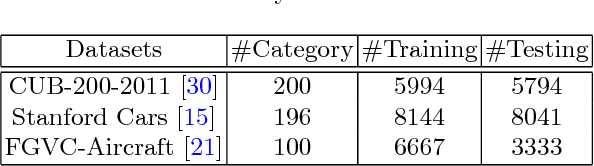
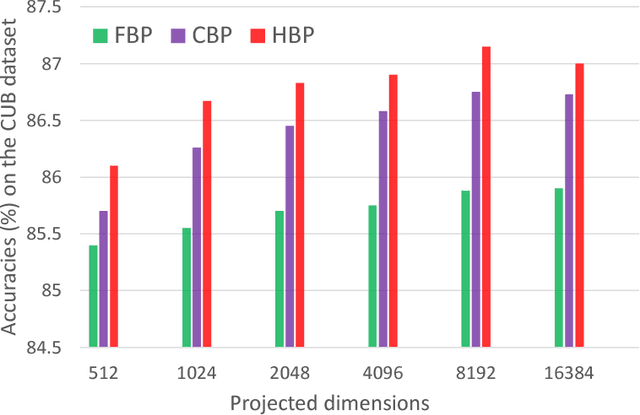
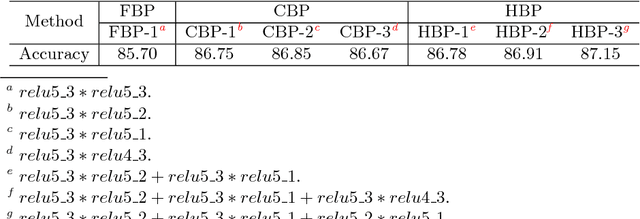
Fine-grained visual recognition is challenging because it highly relies on the modeling of various semantic parts and fine-grained feature learning. Bilinear pooling based models have been shown to be effective at fine-grained recognition, while most previous approaches neglect the fact that inter-layer part feature interaction and fine-grained feature learning are mutually correlated and can reinforce each other. In this paper, we present a novel model to address these issues. First, a cross-layer bilinear pooling approach is proposed to capture the inter-layer part feature relations, which results in superior performance compared with other bilinear pooling based approaches. Second, we propose a novel hierarchical bilinear pooling framework to integrate multiple cross-layer bilinear features to enhance their representation capability. Our formulation is intuitive, efficient and achieves state-of-the-art results on the widely used fine-grained recognition datasets.