 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRF4CIR: Weight-Regularized Fine-Tuning Network for Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) task aims to retrieve target images based on reference images and modification texts. Current CIR methods primarily rely on fine-tuning vision-language pre-trained models. However, we find that these approaches commonly suffer from severe overfitting, posing challenges for CIR with limited triplet data. To better understand this issue, we present a systematic study of overfitting in VLP-based CIR, revealing a significant and previously overlooked generalization gap across different models and datasets. Motivated by these findings, we introduce WRF4CIR, a Weight-Regularized Fine-tuning network for CIR. Specifically, during the fine-tuning process, we apply adversarial perturbations to the model weights for regularization, where these perturbations are generated in the opposite direction of gradient descent. Intuitively, WRF4CIR increases the difficulty of fitting the training data, which helps mitigate overfitting in CIR under limited triplet supervision. Extensive experiments on benchmark datasets demonstrate that WRF4CIR significantly narrows the generalization gap and achieves substantial improvements over existing methods.
Stealthy and Adjustable Text-Guided Backdoor Attacks on Multimodal Pretrained Models
Apr 07, 2026Multimodal pretrained models are vulnerable to backdoor attacks, yet most existing methods rely on visual or multimodal triggers, which are impractical since visually embedded triggers rarely occur in real-world data. To overcome this limitation, we propose a novel Text-Guided Backdoor (TGB) attack on multimodal pretrained models, where commonly occurring words in textual descriptions serve as backdoor triggers, significantly improving stealthiness and practicality. Furthermore, we introduce visual adversarial perturbations on poisoned samples to modulate the model's learning of textual triggers, enabling a controllable and adjustable TGB attack. Extensive experiments on downstream tasks built upon multimodal pretrained models, including Composed Image Retrieval (CIR) and Visual Question Answering (VQA), demonstrate that TGB achieves practicality and stealthiness with adjustable attack success rates across diverse realistic settings, revealing critical security vulnerabilities in multimodal pretrained models.
VII: Visual Instruction Injection for Jailbreaking Image-to-Video Generation Models
Feb 24, 2026Image-to-Video (I2V) generation models, which condition video generation on reference images, have shown emerging visual instruction-following capability, allowing certain visual cues in reference images to act as implicit control signals for video generation. However, this capability also introduces a previously overlooked risk: adversaries may exploit visual instructions to inject malicious intent through the image modality. In this work, we uncover this risk by proposing Visual Instruction Injection (VII), a training-free and transferable jailbreaking framework that intentionally disguises the malicious intent of unsafe text prompts as benign visual instructions in the safe reference image. Specifically, VII coordinates a Malicious Intent Reprogramming module to distill malicious intent from unsafe text prompts while minimizing their static harmfulness, and a Visual Instruction Grounding module to ground the distilled intent onto a safe input image by rendering visual instructions that preserve semantic consistency with the original unsafe text prompt, thereby inducing harmful content during I2V generation. Empirically, our extensive experiments on four state-of-the-art commercial I2V models (Kling-v2.5-turbo, Gemini Veo-3.1, Seedance-1.5-pro, and PixVerse-V5) demonstrate that VII achieves Attack Success Rates of up to 83.5% while reducing Refusal Rates to near zero, significantly outperforming existing baselines.
Prototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
Layer-Aware Analysis of Catastrophic Overfitting: Revealing the Pseudo-Robust Shortcut Dependency
May 25, 2024Catastrophic overfitting (CO) presents a significant challenge in single-step adversarial training (AT), manifesting as highly distorted deep neural networks (DNNs) that are vulnerable to multi-step adversarial attacks. However, the underlying factors that lead to the distortion of decision boundaries remain unclear. In this work, we delve into the specific changes within different DNN layers and discover that during CO, the former layers are more susceptible, experiencing earlier and greater distortion, while the latter layers show relative insensitivity. Our analysis further reveals that this increased sensitivity in former layers stems from the formation of pseudo-robust shortcuts, which alone can impeccably defend against single-step adversarial attacks but bypass genuine-robust learning, resulting in distorted decision boundaries. Eliminating these shortcuts can partially restore robustness in DNNs from the CO state, thereby verifying that dependence on them triggers the occurrence of CO. This understanding motivates us to implement adaptive weight perturbations across different layers to hinder the generation of pseudo-robust shortcuts, consequently mitigating CO. Extensive experiments demonstrate that our proposed method, Layer-Aware Adversarial Weight Perturbation (LAP), can effectively prevent CO and further enhance robustness.
Eliminating Catastrophic Overfitting Via Abnormal Adversarial Examples Regularization
Apr 11, 2024Single-step adversarial training (SSAT) has demonstrated the potential to achieve both efficiency and robustness. However, SSAT suffers from catastrophic overfitting (CO), a phenomenon that leads to a severely distorted classifier, making it vulnerable to multi-step adversarial attacks. In this work, we observe that some adversarial examples generated on the SSAT-trained network exhibit anomalous behaviour, that is, although these training samples are generated by the inner maximization process, their associated loss decreases instead, which we named abnormal adversarial examples (AAEs). Upon further analysis, we discover a close relationship between AAEs and classifier distortion, as both the number and outputs of AAEs undergo a significant variation with the onset of CO. Given this observation, we re-examine the SSAT process and uncover that before the occurrence of CO, the classifier already displayed a slight distortion, indicated by the presence of few AAEs. Furthermore, the classifier directly optimizing these AAEs will accelerate its distortion, and correspondingly, the variation of AAEs will sharply increase as a result. In such a vicious circle, the classifier rapidly becomes highly distorted and manifests as CO within a few iterations. These observations motivate us to eliminate CO by hindering the generation of AAEs. Specifically, we design a novel method, termed Abnormal Adversarial Examples Regularization (AAER), which explicitly regularizes the variation of AAEs to hinder the classifier from becoming distorted. Extensive experiments demonstrate that our method can effectively eliminate CO and further boost adversarial robustness with negligible additional computational overhead.
On the Over-Memorization During Natural, Robust and Catastrophic Overfitting
Oct 13, 2023Overfitting negatively impacts the generalization ability of deep neural networks (DNNs) in both natural and adversarial training. Existing methods struggle to consistently address different types of overfitting, typically designing strategies that focus separately on either natural or adversarial patterns. In this work, we adopt a unified perspective by solely focusing on natural patterns to explore different types of overfitting. Specifically, we examine the memorization effect in DNNs and reveal a shared behaviour termed over-memorization, which impairs their generalization capacity. This behaviour manifests as DNNs suddenly becoming high-confidence in predicting certain training patterns and retaining a persistent memory for them. Furthermore, when DNNs over-memorize an adversarial pattern, they tend to simultaneously exhibit high-confidence prediction for the corresponding natural pattern. These findings motivate us to holistically mitigate different types of overfitting by hindering the DNNs from over-memorization natural patterns. To this end, we propose a general framework, Distraction Over-Memorization (DOM), which explicitly prevents over-memorization by either removing or augmenting the high-confidence natural patterns. Extensive experiments demonstrate the effectiveness of our proposed method in mitigating overfitting across various training paradigms.
On the Onset of Robust Overfitting in Adversarial Training
Oct 01, 2023


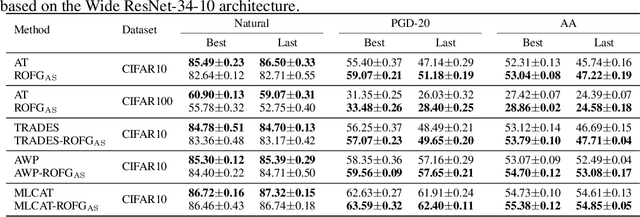
Adversarial Training (AT) is a widely-used algorithm for building robust neural networks, but it suffers from the issue of robust overfitting, the fundamental mechanism of which remains unclear. In this work, we consider normal data and adversarial perturbation as separate factors, and identify that the underlying causes of robust overfitting stem from the normal data through factor ablation in AT. Furthermore, we explain the onset of robust overfitting as a result of the model learning features that lack robust generalization, which we refer to as non-effective features. Specifically, we provide a detailed analysis of the generation of non-effective features and how they lead to robust overfitting. Additionally, we explain various empirical behaviors observed in robust overfitting and revisit different techniques to mitigate robust overfitting from the perspective of non-effective features, providing a comprehensive understanding of the robust overfitting phenomenon. This understanding inspires us to propose two measures, attack strength and data augmentation, to hinder the learning of non-effective features by the neural network, thereby alleviating robust overfitting. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of the proposed methods in mitigating robust overfitting and enhancing adversarial robustness.
Strength-Adaptive Adversarial Training
Oct 04, 2022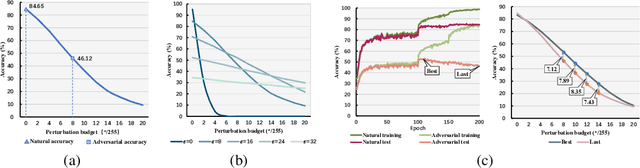
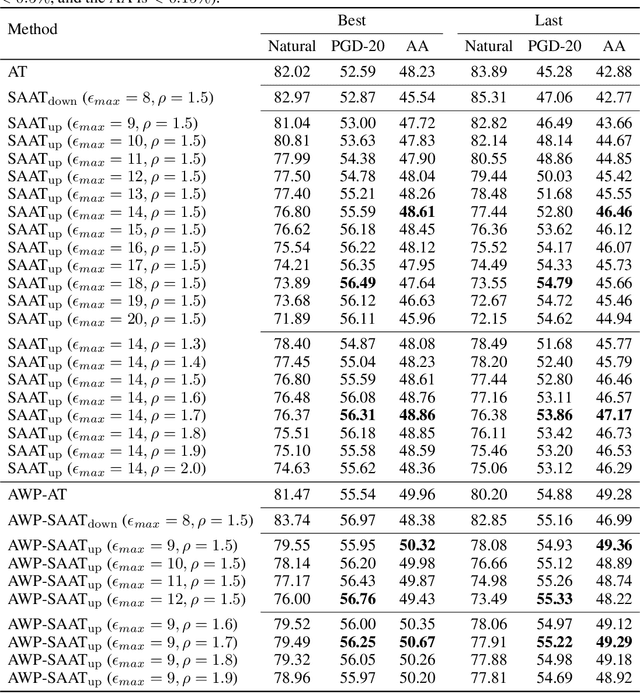

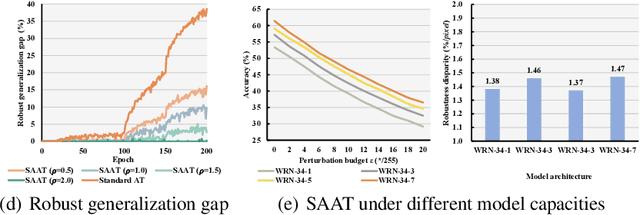
Adversarial training (AT) is proved to reliably improve network's robustness against adversarial data. However, current AT with a pre-specified perturbation budget has limitations in learning a robust network. Firstly, applying a pre-specified perturbation budget on networks of various model capacities will yield divergent degree of robustness disparity between natural and robust accuracies, which deviates from robust network's desideratum. Secondly, the attack strength of adversarial training data constrained by the pre-specified perturbation budget fails to upgrade as the growth of network robustness, which leads to robust overfitting and further degrades the adversarial robustness. To overcome these limitations, we propose \emph{Strength-Adaptive Adversarial Training} (SAAT). Specifically, the adversary employs an adversarial loss constraint to generate adversarial training data. Under this constraint, the perturbation budget will be adaptively adjusted according to the training state of adversarial data, which can effectively avoid robust overfitting. Besides, SAAT explicitly constrains the attack strength of training data through the adversarial loss, which manipulates model capacity scheduling during training, and thereby can flexibly control the degree of robustness disparity and adjust the tradeoff between natural accuracy and robustness. Extensive experiments show that our proposal boosts the robustness of adversarial training.
Understanding Robust Overfitting of Adversarial Training and Beyond
Jun 22, 2022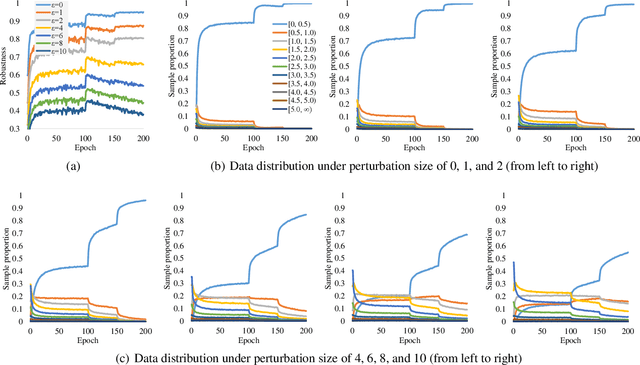
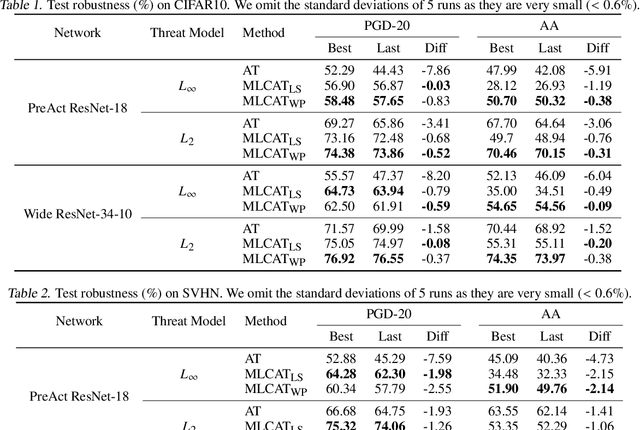
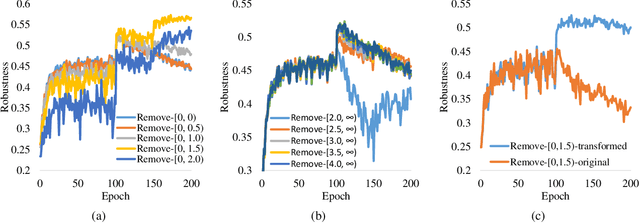

Robust overfitting widely exists in adversarial training of deep networks. The exact underlying reasons for this are still not completely understood. Here, we explore the causes of robust overfitting by comparing the data distribution of \emph{non-overfit} (weak adversary) and \emph{overfitted} (strong adversary) adversarial training, and observe that the distribution of the adversarial data generated by weak adversary mainly contain small-loss data. However, the adversarial data generated by strong adversary is more diversely distributed on the large-loss data and the small-loss data. Given these observations, we further designed data ablation adversarial training and identify that some small-loss data which are not worthy of the adversary strength cause robust overfitting in the strong adversary mode. To relieve this issue, we propose \emph{minimum loss constrained adversarial training} (MLCAT): in a minibatch, we learn large-loss data as usual, and adopt additional measures to increase the loss of the small-loss data. Technically, MLCAT hinders data fitting when they become easy to learn to prevent robust overfitting; philosophically, MLCAT reflects the spirit of turning waste into treasure and making the best use of each adversarial data; algorithmically, we designed two realizations of MLCAT, and extensive experiments demonstrate that MLCAT can eliminate robust overfitting and further boost adversarial robustness.