 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Robust Overfitting of Adversarial Training and Beyond
Paper and Code
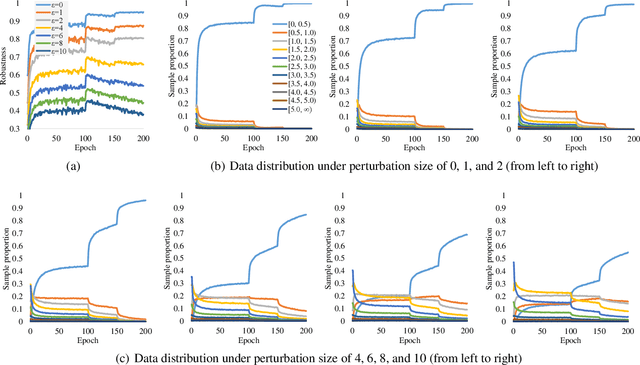
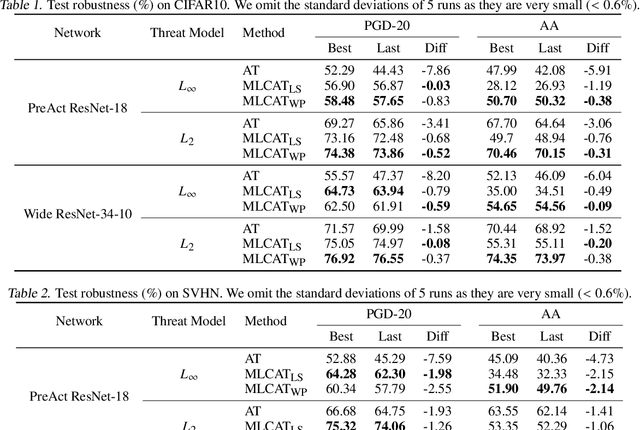
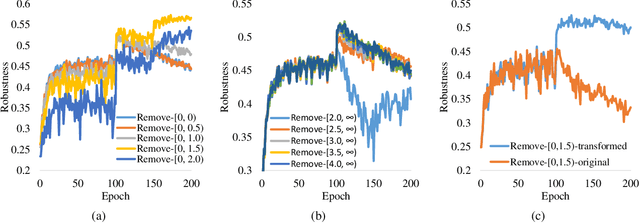

Robust overfitting widely exists in adversarial training of deep networks. The exact underlying reasons for this are still not completely understood. Here, we explore the causes of robust overfitting by comparing the data distribution of \emph{non-overfit} (weak adversary) and \emph{overfitted} (strong adversary) adversarial training, and observe that the distribution of the adversarial data generated by weak adversary mainly contain small-loss data. However, the adversarial data generated by strong adversary is more diversely distributed on the large-loss data and the small-loss data. Given these observations, we further designed data ablation adversarial training and identify that some small-loss data which are not worthy of the adversary strength cause robust overfitting in the strong adversary mode. To relieve this issue, we propose \emph{minimum loss constrained adversarial training} (MLCAT): in a minibatch, we learn large-loss data as usual, and adopt additional measures to increase the loss of the small-loss data. Technically, MLCAT hinders data fitting when they become easy to learn to prevent robust overfitting; philosophically, MLCAT reflects the spirit of turning waste into treasure and making the best use of each adversarial data; algorithmically, we designed two realizations of MLCAT, and extensive experiments demonstrate that MLCAT can eliminate robust overfitting and further boost adversarial robustness.