 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Budgeting for Machine Learning
Paper and Code
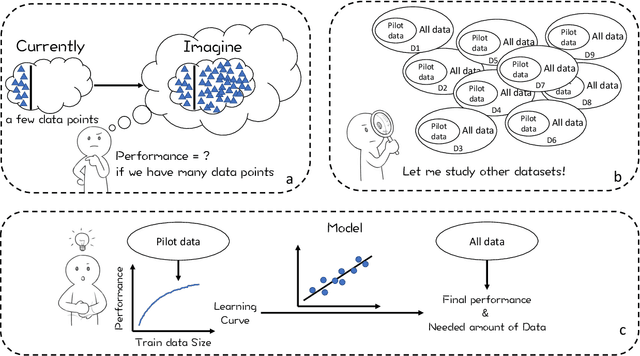


Data is the fuel powering AI and creates tremendous value for many domains. However, collecting datasets for AI is a time-consuming, expensive, and complicated endeavor. For practitioners, data investment remains to be a leap of faith in practice. In this work, we study the data budgeting problem and formulate it as two sub-problems: predicting (1) what is the saturating performance if given enough data, and (2) how many data points are needed to reach near the saturating performance. Different from traditional dataset-independent methods like PowerLaw, we proposed a learning method to solve data budgeting problems. To support and systematically evaluate the learning-based method for data budgeting, we curate a large collection of 383 tabular ML datasets, along with their data vs performance curves. Our empirical evaluation shows that it is possible to perform data budgeting given a small pilot study dataset with as few as $50$ data points.