 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCartridges: Lightweight and general-purpose long context representations via self-study
Jun 06, 2025



Large language models are often used to answer queries grounded in large text corpora (e.g. codebases, legal documents, or chat histories) by placing the entire corpus in the context window and leveraging in-context learning (ICL). Although current models support contexts of 100K-1M tokens, this setup is costly to serve because the memory consumption of the KV cache scales with input length. We explore an alternative: training a smaller KV cache offline on each corpus. At inference time, we load this trained KV cache, which we call a Cartridge, and decode a response. Critically, the cost of training a Cartridge can be amortized across all the queries referencing the same corpus. However, we find that the naive approach of training the Cartridge with next-token prediction on the corpus is not competitive with ICL. Instead, we propose self-study, a training recipe in which we generate synthetic conversations about the corpus and train the Cartridge with a context-distillation objective. We find that Cartridges trained with self-study replicate the functionality of ICL, while being significantly cheaper to serve. On challenging long-context benchmarks, Cartridges trained with self-study match ICL performance while using 38.6x less memory and enabling 26.4x higher throughput. Self-study also extends the model's effective context length (e.g. from 128k to 484k tokens on MTOB) and surprisingly, leads to Cartridges that can be composed at inference time without retraining.
Minions: Cost-efficient Collaboration Between On-device and Cloud Language Models
Feb 21, 2025We investigate an emerging setup in which a small, on-device language model (LM) with access to local data communicates with a frontier, cloud-hosted LM to solve real-world tasks involving financial, medical, and scientific reasoning over long documents. Can a local-remote collaboration reduce cloud inference costs while preserving quality? First, we consider a naive collaboration protocol where the local and remote models simply chat back and forth. Because only the local model reads the full context, this protocol achieves a 30.4x reduction in remote costs, but recovers only 87% of the performance of the frontier model. We identify two key limitations of this protocol: the local model struggles to (1) follow the remote model's multi-step instructions and (2) reason over long contexts. Motivated by these observations, we study an extension of this protocol, coined MinionS, in which the remote model decomposes the task into easier subtasks over shorter chunks of the document, that are executed locally in parallel. MinionS reduces costs by 5.7x on average while recovering 97.9% of the performance of the remote model alone. Our analysis reveals several key design choices that influence the trade-off between cost and performance in local-remote systems.
Just read twice: closing the recall gap for recurrent language models
Jul 07, 2024



Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives $11.0 \pm 1.3$ points of improvement, averaged across $16$ recurrent LMs and the $6$ ICL tasks, with $11.9\times$ higher throughput than FlashAttention-2 for generation prefill (length $32$k, batch size $16$, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides $99\%$ of Transformer quality at $360$M params., $30$B tokens and $96\%$ at $1.3$B params., $50$B tokens on average across the tasks, with $19.2\times$ higher throughput for prefill than FA2.
Simple linear attention language models balance the recall-throughput tradeoff
Feb 28, 2024



Recent work has shown that attention-based language models excel at recall, the ability to ground generations in tokens previously seen in context. However, the efficiency of attention-based models is bottle-necked during inference by the KV-cache's aggressive memory consumption. In this work, we explore whether we can improve language model efficiency (e.g. by reducing memory consumption) without compromising on recall. By applying experiments and theory to a broad set of architectures, we identify a key tradeoff between a model's state size and recall ability. We show that efficient alternatives to attention (e.g. H3, Mamba, RWKV) maintain a fixed-size recurrent state, but struggle at recall. We propose BASED a simple architecture combining linear and sliding window attention. By varying BASED window size and linear attention feature dimension, we can dial the state size and traverse the pareto frontier of the recall-memory tradeoff curve, recovering the full quality of attention on one end and the small state size of attention-alternatives on the other. We train language models up to 1.3b parameters and show that BASED matches the strongest sub-quadratic models (e.g. Mamba) in perplexity and outperforms them on real-world recall-intensive tasks by 6.22 accuracy points. Implementations of linear attention are often less efficient than optimized standard attention implementations. To make BASED competitive, we develop IO-aware algorithms that enable 24x higher throughput on language generation than FlashAttention-2, when generating 1024 tokens using 1.3b parameter models. Code for this work is provided at: https://github.com/HazyResearch/based.
Zoology: Measuring and Improving Recall in Efficient Language Models
Dec 08, 2023



Attention-free language models that combine gating and convolutions are growing in popularity due to their efficiency and increasingly competitive performance. To better understand these architectures, we pretrain a suite of 17 attention and "gated-convolution" language models, finding that SoTA gated-convolution architectures still underperform attention by up to 2.1 perplexity points on the Pile. In fine-grained analysis, we find 82% of the gap is explained by each model's ability to recall information that is previously mentioned in-context, e.g. "Hakuna Matata means no worries Hakuna Matata it means no" $\rightarrow$ "??". On this task, termed "associative recall", we find that attention outperforms gated-convolutions by a large margin: a 70M parameter attention model outperforms a 1.4 billion parameter gated-convolution model on associative recall. This is surprising because prior work shows gated convolutions can perfectly solve synthetic tests for AR capability. To close the gap between synthetics and real language, we develop a new formalization of the task called multi-query associative recall (MQAR) that better reflects actual language. We perform an empirical and theoretical study of MQAR that elucidates differences in the parameter-efficiency of attention and gated-convolution recall. Informed by our analysis, we evaluate simple convolution-attention hybrids and show that hybrids with input-dependent sparse attention patterns can close 97.4% of the gap to attention, while maintaining sub-quadratic scaling. Our code is accessible at: https://github.com/HazyResearch/zoology.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023



Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
Apr 20, 2023
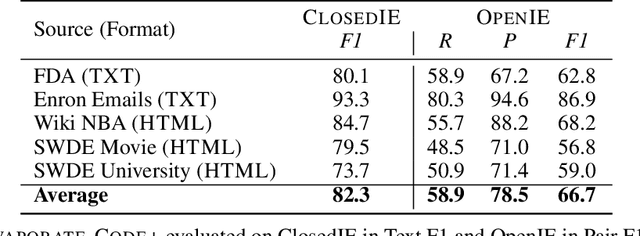

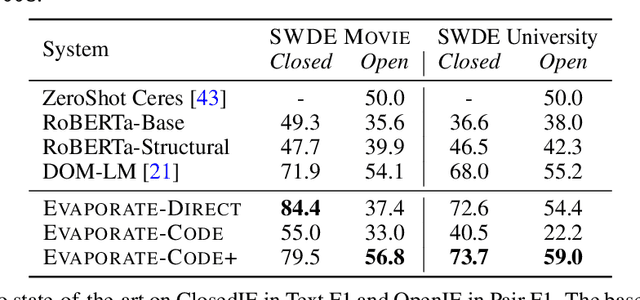
A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
HAPI: A Large-scale Longitudinal Dataset of Commercial ML API Predictions
Sep 18, 2022
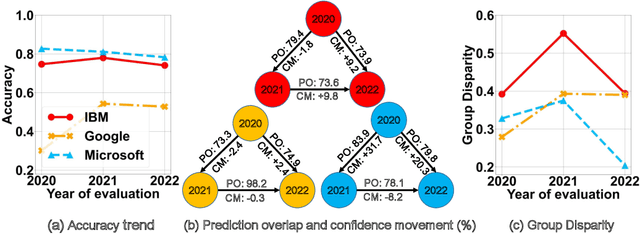

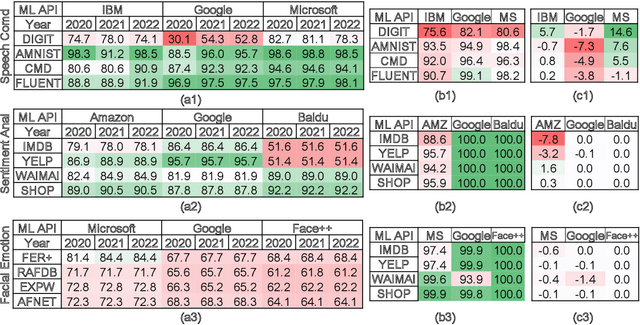
Commercial ML APIs offered by providers such as Google, Amazon and Microsoft have dramatically simplified ML adoption in many applications. Numerous companies and academics pay to use ML APIs for tasks such as object detection, OCR and sentiment analysis. Different ML APIs tackling the same task can have very heterogeneous performance. Moreover, the ML models underlying the APIs also evolve over time. As ML APIs rapidly become a valuable marketplace and a widespread way to consume machine learning, it is critical to systematically study and compare different APIs with each other and to characterize how APIs change over time. However, this topic is currently underexplored due to the lack of data. In this paper, we present HAPI (History of APIs), a longitudinal dataset of 1,761,417 instances of commercial ML API applications (involving APIs from Amazon, Google, IBM, Microsoft and other providers) across diverse tasks including image tagging, speech recognition and text mining from 2020 to 2022. Each instance consists of a query input for an API (e.g., an image or text) along with the API's output prediction/annotation and confidence scores. HAPI is the first large-scale dataset of ML API usages and is a unique resource for studying ML-as-a-service (MLaaS). As examples of the types of analyses that HAPI enables, we show that ML APIs' performance change substantially over time--several APIs' accuracies dropped on specific benchmark datasets. Even when the API's aggregate performance stays steady, its error modes can shift across different subtypes of data between 2020 and 2022. Such changes can substantially impact the entire analytics pipelines that use some ML API as a component. We further use HAPI to study commercial APIs' performance disparities across demographic subgroups over time. HAPI can stimulate more research in the growing field of MLaaS.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022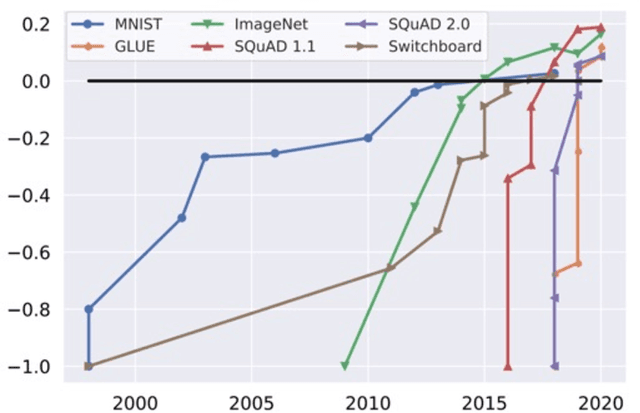
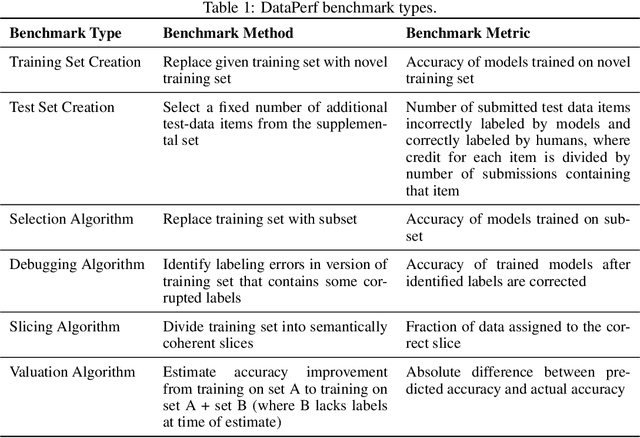
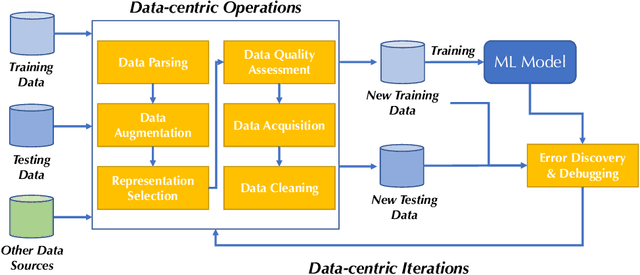
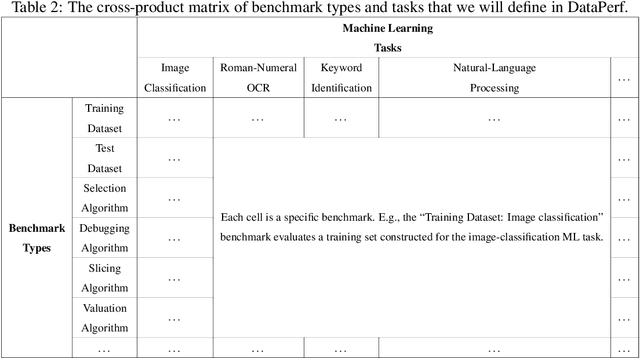
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Apr 11, 2022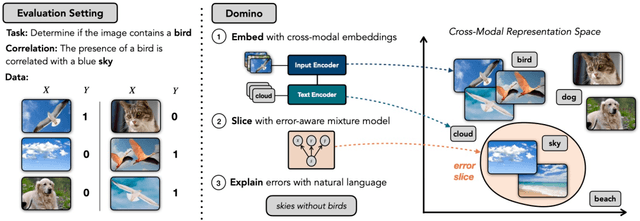
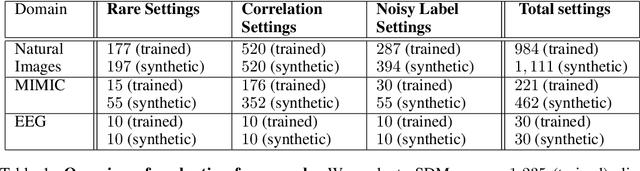
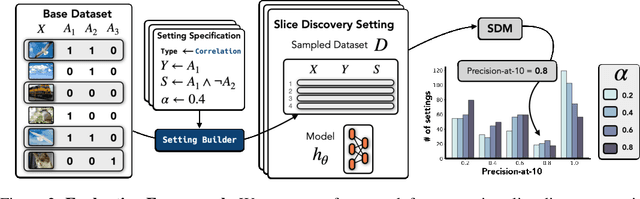
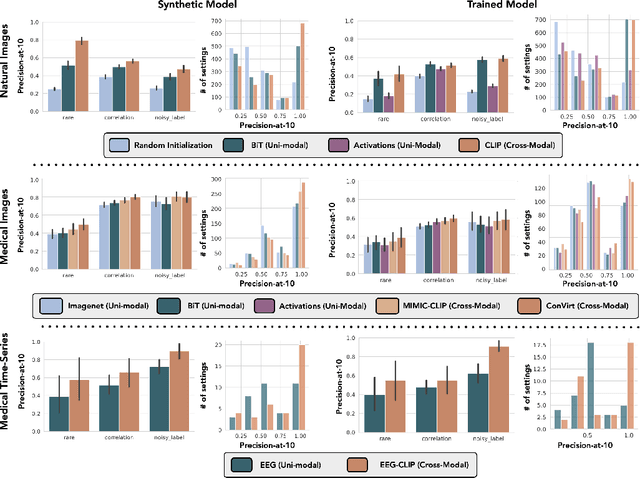
Machine learning models that achieve high overall accuracy often make systematic errors on important subsets (or slices) of data. Identifying underperforming slices is particularly challenging when working with high-dimensional inputs (e.g. images, audio), where important slices are often unlabeled. In order to address this issue, recent studies have proposed automated slice discovery methods (SDMs), which leverage learned model representations to mine input data for slices on which a model performs poorly. To be useful to a practitioner, these methods must identify slices that are both underperforming and coherent (i.e. united by a human-understandable concept). However, no quantitative evaluation framework currently exists for rigorously assessing SDMs with respect to these criteria. Additionally, prior qualitative evaluations have shown that SDMs often identify slices that are incoherent. In this work, we address these challenges by first designing a principled evaluation framework that enables a quantitative comparison of SDMs across 1,235 slice discovery settings in three input domains (natural images, medical images, and time-series data). Then, motivated by the recent development of powerful cross-modal representation learning approaches, we present Domino, an SDM that leverages cross-modal embeddings and a novel error-aware mixture model to discover and describe coherent slices. We find that Domino accurately identifies 36% of the 1,235 slices in our framework - a 12 percentage point improvement over prior methods. Further, Domino is the first SDM that can provide natural language descriptions of identified slices, correctly generating the exact name of the slice in 35% of settings.