 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards trustworthy seizure onset detection using workflow notes
Jun 14, 2023



A major barrier to deploying healthcare AI models is their trustworthiness. One form of trustworthiness is a model's robustness across different subgroups: while existing models may exhibit expert-level performance on aggregate metrics, they often rely on non-causal features, leading to errors in hidden subgroups. To take a step closer towards trustworthy seizure onset detection from EEG, we propose to leverage annotations that are produced by healthcare personnel in routine clinical workflows -- which we refer to as workflow notes -- that include multiple event descriptions beyond seizures. Using workflow notes, we first show that by scaling training data to an unprecedented level of 68,920 EEG hours, seizure onset detection performance significantly improves (+12.3 AUROC points) compared to relying on smaller training sets with expensive manual gold-standard labels. Second, we reveal that our binary seizure onset detection model underperforms on clinically relevant subgroups (e.g., up to a margin of 6.5 AUROC points between pediatrics and adults), while having significantly higher false positives on EEG clips showing non-epileptiform abnormalities compared to any EEG clip (+19 FPR points). To improve model robustness to hidden subgroups, we train a multilabel model that classifies 26 attributes other than seizures, such as spikes, slowing, and movement artifacts. We find that our multilabel model significantly improves overall seizure onset detection performance (+5.9 AUROC points) while greatly improving performance among subgroups (up to +8.3 AUROC points), and decreases false positives on non-epileptiform abnormalities by 8 FPR points. Finally, we propose a clinical utility metric based on false positives per 24 EEG hours and find that our multilabel model improves this clinical utility metric by a factor of 2x across different clinical settings.
Spatiotemporal Modeling of Multivariate Signals With Graph Neural Networks and Structured State Space Models
Nov 21, 2022Multivariate signals are prevalent in various domains, such as healthcare, transportation systems, and space sciences. Modeling spatiotemporal dependencies in multivariate signals is challenging due to (1) long-range temporal dependencies and (2) complex spatial correlations between sensors. To address these challenges, we propose representing multivariate signals as graphs and introduce GraphS4mer, a general graph neural network (GNN) architecture that captures both spatial and temporal dependencies in multivariate signals. Specifically, (1) we leverage Structured State Spaces model (S4), a state-of-the-art sequence model, to capture long-term temporal dependencies and (2) we propose a graph structure learning layer in GraphS4mer to learn dynamically evolving graph structures in the data. We evaluate our proposed model on three distinct tasks and show that GraphS4mer consistently improves over existing models, including (1) seizure detection from electroencephalography signals, outperforming a previous GNN with self-supervised pretraining by 3.1 points in AUROC; (2) sleep staging from polysomnography signals, a 4.1 points improvement in macro-F1 score compared to existing sleep staging models; and (3) traffic forecasting, reducing MAE by 8.8% compared to existing GNNs and by 1.4% compared to Transformer-based models.
ATCON: Attention Consistency for Vision Models
Oct 18, 2022
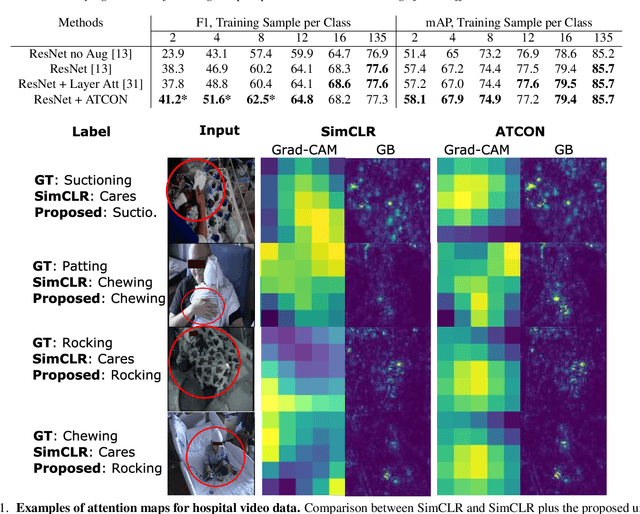

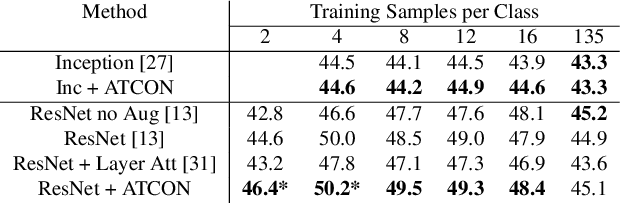
Attention--or attribution--maps methods are methods designed to highlight regions of the model's input that were discriminative for its predictions. However, different attention maps methods can highlight different regions of the input, with sometimes contradictory explanations for a prediction. This effect is exacerbated when the training set is small. This indicates that either the model learned incorrect representations or that the attention maps methods did not accurately estimate the model's representations. We propose an unsupervised fine-tuning method that optimizes the consistency of attention maps and show that it improves both classification performance and the quality of attention maps. We propose an implementation for two state-of-the-art attention computation methods, Grad-CAM and Guided Backpropagation, which relies on an input masking technique. We also show results on Grad-CAM and Integrated Gradients in an ablation study. We evaluate this method on our own dataset of event detection in continuous video recordings of hospital patients aggregated and curated for this work. As a sanity check, we also evaluate the proposed method on PASCAL VOC and SVHN. With the proposed method, with small training sets, we achieve a 6.6 points lift of F1 score over the baselines on our video dataset, a 2.9 point lift of F1 score on PASCAL, and a 1.8 points lift of mean Intersection over Union over Grad-CAM for weakly supervised detection on PASCAL. Those improved attention maps may help clinicians better understand vision model predictions and ease the deployment of machine learning systems into clinical care. We share part of the code for this article at the following repository: https://github.com/alimirzazadeh/SemisupervisedAttention.
TRUST-LAPSE: An Explainable & Actionable Mistrust Scoring Framework for Model Monitoring
Jul 22, 2022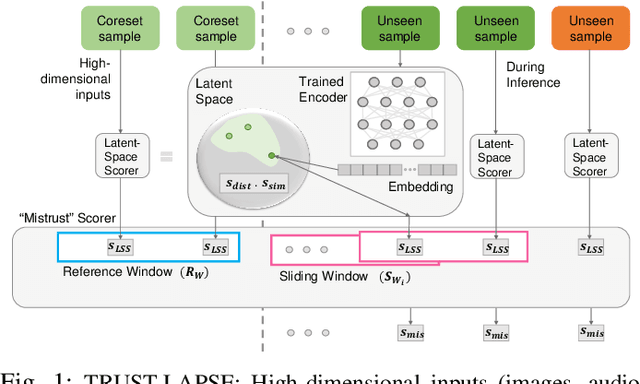
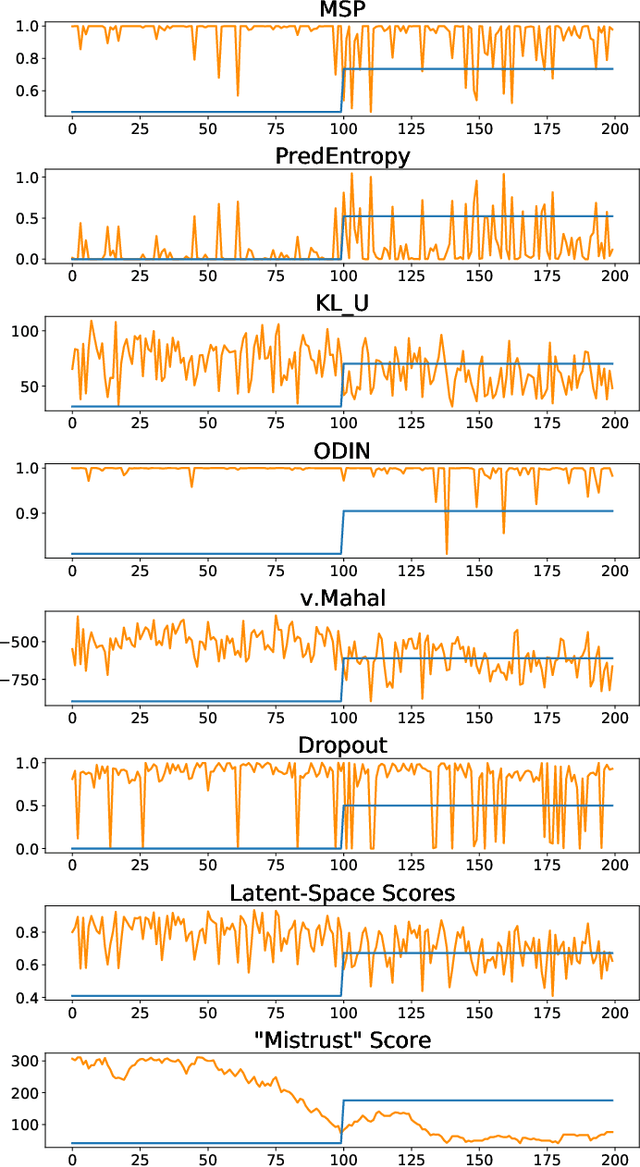


Continuous monitoring of trained ML models to determine when their predictions should and should not be trusted is essential for their safe deployment. Such a framework ought to be high-performing, explainable, post-hoc and actionable. We propose TRUST-LAPSE, a "mistrust" scoring framework for continuous model monitoring. We assess the trustworthiness of each input sample's model prediction using a sequence of latent-space embeddings. Specifically, (a) our latent-space mistrust score estimates mistrust using distance metrics (Mahalanobis distance) and similarity metrics (cosine similarity) in the latent-space and (b) our sequential mistrust score determines deviations in correlations over the sequence of past input representations in a non-parametric, sliding-window based algorithm for actionable continuous monitoring. We evaluate TRUST-LAPSE via two downstream tasks: (1) distributionally shifted input detection and (2) data drift detection, across diverse domains -- audio & vision using public datasets and further benchmark our approach on challenging, real-world electroencephalograms (EEG) datasets for seizure detection. Our latent-space mistrust scores achieve state-of-the-art results with AUROCs of 84.1 (vision), 73.9 (audio), 77.1 (clinical EEGs), outperforming baselines by over 10 points. We expose critical failures in popular baselines that remain insensitive to input semantic content, rendering them unfit for real-world model monitoring. We show that our sequential mistrust scores achieve high drift detection rates: over 90% of the streams show < 20% error for all domains. Through extensive qualitative and quantitative evaluations, we show that our mistrust scores are more robust and provide explainability for easy adoption into practice.
Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Apr 11, 2022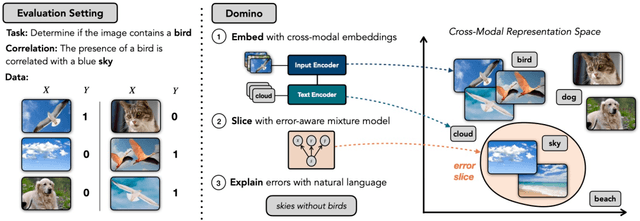
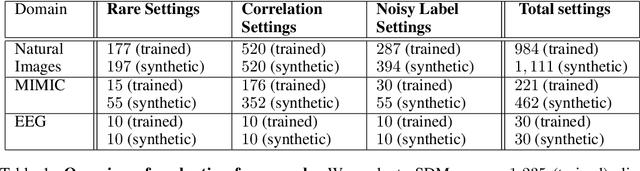
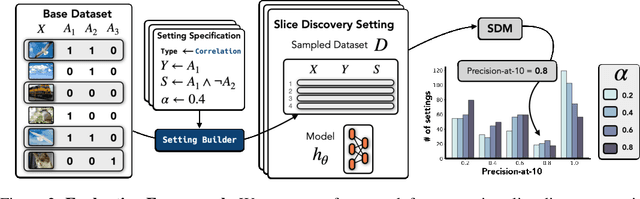
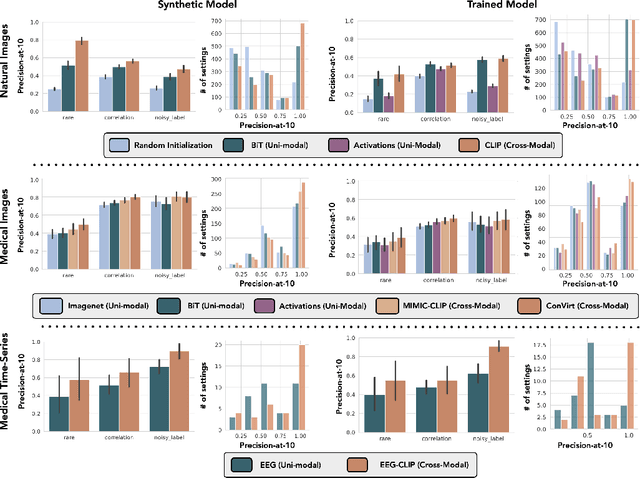
Machine learning models that achieve high overall accuracy often make systematic errors on important subsets (or slices) of data. Identifying underperforming slices is particularly challenging when working with high-dimensional inputs (e.g. images, audio), where important slices are often unlabeled. In order to address this issue, recent studies have proposed automated slice discovery methods (SDMs), which leverage learned model representations to mine input data for slices on which a model performs poorly. To be useful to a practitioner, these methods must identify slices that are both underperforming and coherent (i.e. united by a human-understandable concept). However, no quantitative evaluation framework currently exists for rigorously assessing SDMs with respect to these criteria. Additionally, prior qualitative evaluations have shown that SDMs often identify slices that are incoherent. In this work, we address these challenges by first designing a principled evaluation framework that enables a quantitative comparison of SDMs across 1,235 slice discovery settings in three input domains (natural images, medical images, and time-series data). Then, motivated by the recent development of powerful cross-modal representation learning approaches, we present Domino, an SDM that leverages cross-modal embeddings and a novel error-aware mixture model to discover and describe coherent slices. We find that Domino accurately identifies 36% of the 1,235 slices in our framework - a 12 percentage point improvement over prior methods. Further, Domino is the first SDM that can provide natural language descriptions of identified slices, correctly generating the exact name of the slice in 35% of settings.
Automated Detection of Patients in Hospital Video Recordings
Nov 28, 2021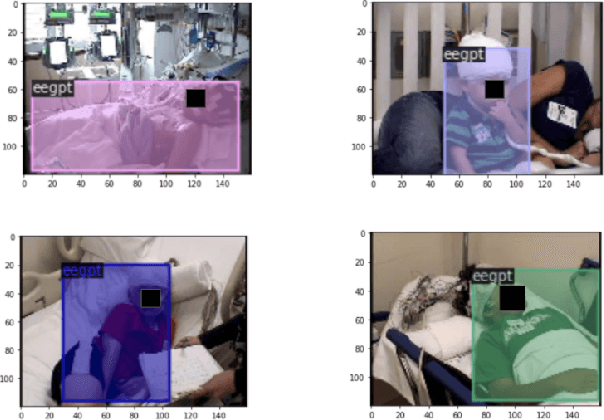
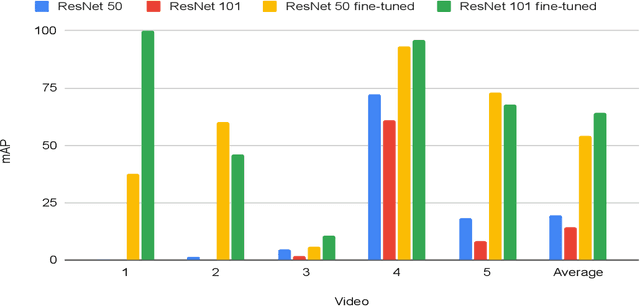
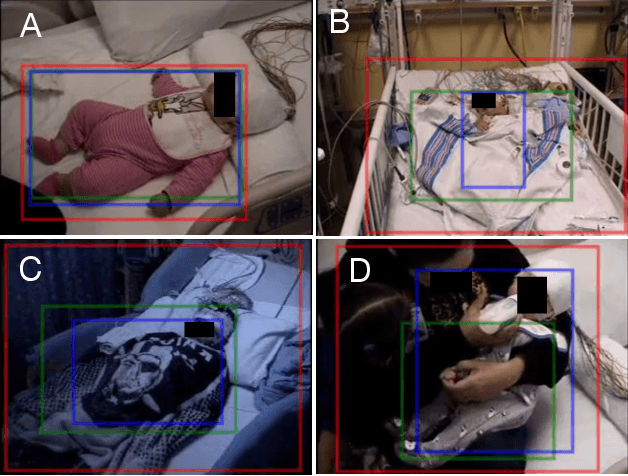
In a clinical setting, epilepsy patients are monitored via video electroencephalogram (EEG) tests. A video EEG records what the patient experiences on videotape while an EEG device records their brainwaves. Currently, there are no existing automated methods for tracking the patient's location during a seizure, and video recordings of hospital patients are substantially different from publicly available video benchmark datasets. For example, the camera angle can be unusual, and patients can be partially covered with bedding sheets and electrode sets. Being able to track a patient in real-time with video EEG would be a promising innovation towards improving the quality of healthcare. Specifically, an automated patient detection system could supplement clinical oversight and reduce the resource-intensive efforts of nurses and doctors who need to continuously monitor patients. We evaluate an ImageNet pre-trained Mask R-CNN, a standard deep learning model for object detection, on the task of patient detection using our own curated dataset of 45 videos of hospital patients. The dataset was aggregated and curated for this work. We show that without fine-tuning, ImageNet pre-trained Mask R-CNN models perform poorly on such data. By fine-tuning the models with a subset of our dataset, we observe a substantial improvement in patient detection performance, with a mean average precision of 0.64. We show that the results vary substantially depending on the video clip.
Double Descent Optimization Pattern and Aliasing: Caveats of Noisy Labels
Jun 03, 2021

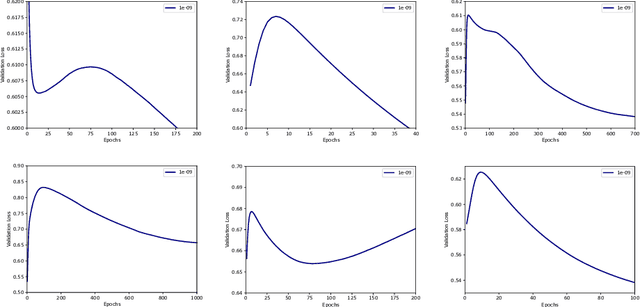
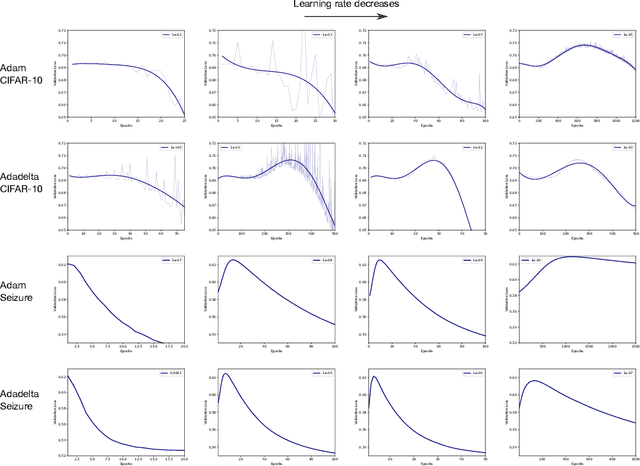
Optimization plays a key role in the training of deep neural networks. Deciding when to stop training can have a substantial impact on the performance of the network during inference. Under certain conditions, the generalization error can display a double descent pattern during training: the learning curve is non-monotonic and seemingly diverges before converging again after additional epochs. This optimization pattern can lead to early stopping procedures to stop training before the second convergence and consequently select a suboptimal set of parameters for the network, with worse performance during inference. In this work, in addition to confirming that double descent occurs with small datasets and noisy labels as evidenced by others, we show that noisy labels must be present both in the training and generalization sets to observe a double descent pattern. We also show that the learning rate has an influence on double descent, and study how different optimizers and optimizer parameters influence the apparition of double descent. Finally, we show that increasing the learning rate can create an aliasing effect that masks the double descent pattern without suppressing it. We study this phenomenon through extensive experiments on variants of CIFAR-10 and show that they translate to a real world application: the forecast of seizure events in epileptic patients from continuous electroencephalographic recordings.
Automated Seizure Detection and Seizure Type Classification From Electroencephalography With a Graph Neural Network and Self-Supervised Pre-Training
Apr 16, 2021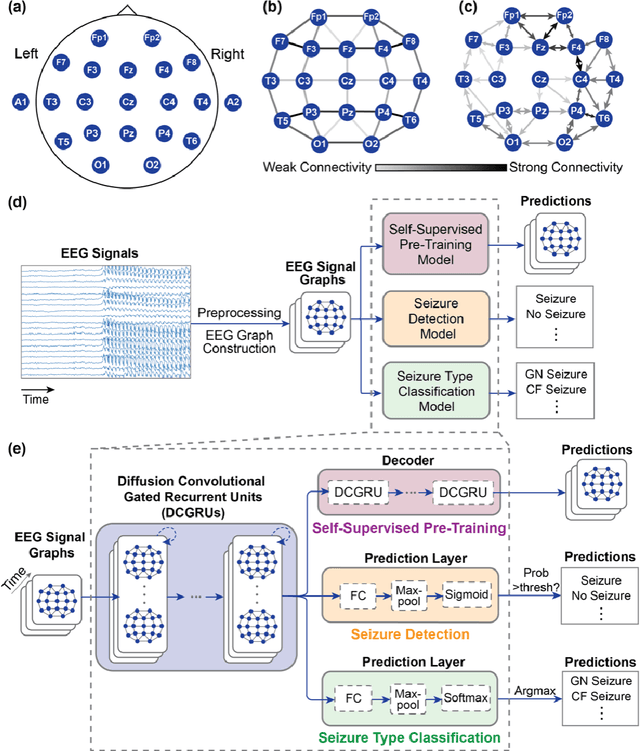
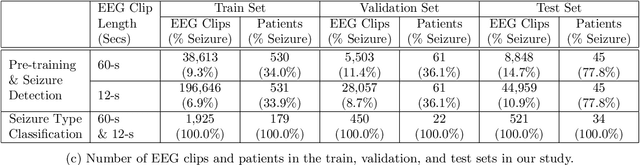
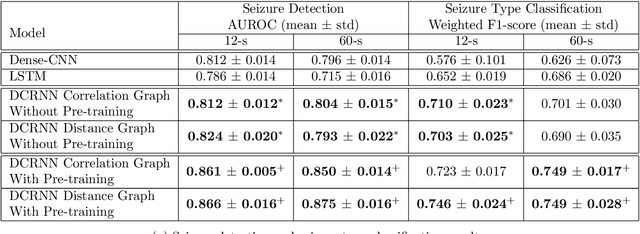
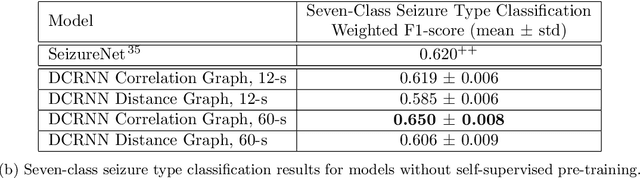
Automated seizure detection and classification from electroencephalography (EEG) can greatly improve the diagnosis and treatment of seizures. While prior studies mainly used convolutional neural networks (CNNs) that assume image-like structure in EEG signals or spectrograms, this modeling choice does not reflect the natural geometry of or connectivity between EEG electrodes. In this study, we propose modeling EEGs as graphs and present a graph neural network for automated seizure detection and classification. In addition, we leverage unlabeled EEG data using a self-supervised pre-training strategy. Our graph model with self-supervised pre-training significantly outperforms previous state-of-the-art CNN and Long Short-Term Memory (LSTM) models by 6.3 points (7.8%) in Area Under the Receiver Operating Characteristic curve (AUROC) for seizure detection and 6.3 points (9.2%) in weighted F1-score for seizure type classification. Ablation studies show that our graph-based modeling approach significantly outperforms existing CNN or LSTM models, and that self-supervision helps further improve the model performance. Moreover, we find that self-supervised pre-training substantially improves model performance on combined tonic seizures, a low-prevalence seizure type. Furthermore, our model interpretability analysis suggests that our model is better at identifying seizure regions compared to an existing CNN. In summary, our graph-based modeling approach integrates domain knowledge about EEG, sets a new state-of-the-art for seizure detection and classification on a large public dataset (5,499 EEG files), and provides better ability to identify seizure regions.
Inaccurate Supervision of Neural Networks with Incorrect Labels: Application to Epilepsy
Dec 01, 2020
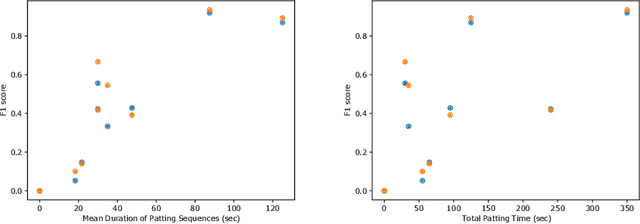
This work describes multiple weak supervision strategies for video processing with neural networks in the context of seizure detection. To study seizure onset, we have designed automated methods to detect seizures from electroencephalography (EEG), a modality used for recording electrical brain activity. However, the EEG signal alone is sometimes not enough for existing detection methods to discriminate seizure from artifacts having a similar signal on EEG. For example, such artifacts could be triggered by patting, rocking or suctioning in the case of neonates. In this article, we addressed this problem by automatically detecting an example artifact -- patting of neonates -- from continuous video recordings of neonates acquired during clinical routine. We computed frame-to-frame cross-correlation matrices to isolate patterns showing repetitive movements indicative of patting of the patient. Next, a convolutional neural network was trained to classify whether these matrices contained patting events using weak training labels -- noisy labels generated during daily clinical procedure. The labels were considered weak as they were sometimes incorrect. We investigated whether networks trained with more samples, containing more uncertain and weak labels, could achieve a higher performance. Our results showed that, in the case of patting detection, such networks could achieve a higher recall, without sacrificing precision. These networks focused on areas of the cross-correlation matrices that were more meaningful to the task. More generally, our work gives insights into building more accurate models from weakly labelled time sequences.
Cross-Modal Data Programming Enables Rapid Medical Machine Learning
Mar 26, 2019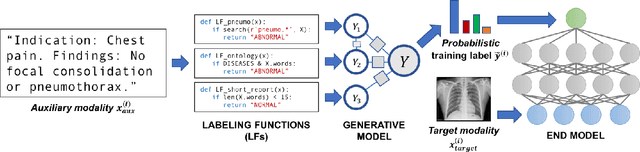
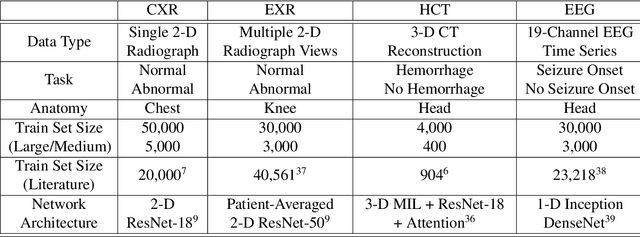
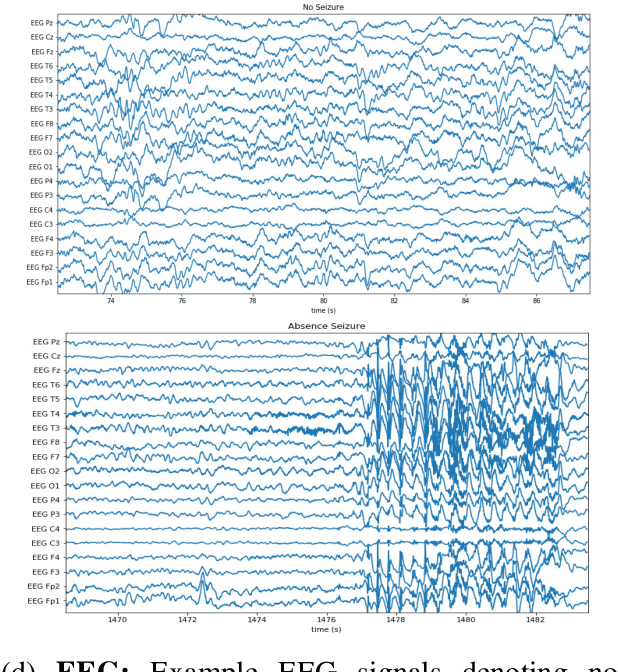

Labeling training datasets has become a key barrier to building medical machine learning models. One strategy is to generate training labels programmatically, for example by applying natural language processing pipelines to text reports associated with imaging studies. We propose cross-modal data programming, which generalizes this intuitive strategy in a theoretically-grounded way that enables simpler, clinician-driven input, reduces required labeling time, and improves with additional unlabeled data. In this approach, clinicians generate training labels for models defined over a target modality (e.g. images or time series) by writing rules over an auxiliary modality (e.g. text reports). The resulting technical challenge consists of estimating the accuracies and correlations of these rules; we extend a recent unsupervised generative modeling technique to handle this cross-modal setting in a provably consistent way. Across four applications in radiography, computed tomography, and electroencephalography, and using only several hours of clinician time, our approach matches or exceeds the efficacy of physician-months of hand-labeling with statistical significance, demonstrating a fundamentally faster and more flexible way of building machine learning models in medicine.