 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Modeling of Multivariate Signals With Graph Neural Networks and Structured State Space Models
Nov 21, 2022Multivariate signals are prevalent in various domains, such as healthcare, transportation systems, and space sciences. Modeling spatiotemporal dependencies in multivariate signals is challenging due to (1) long-range temporal dependencies and (2) complex spatial correlations between sensors. To address these challenges, we propose representing multivariate signals as graphs and introduce GraphS4mer, a general graph neural network (GNN) architecture that captures both spatial and temporal dependencies in multivariate signals. Specifically, (1) we leverage Structured State Spaces model (S4), a state-of-the-art sequence model, to capture long-term temporal dependencies and (2) we propose a graph structure learning layer in GraphS4mer to learn dynamically evolving graph structures in the data. We evaluate our proposed model on three distinct tasks and show that GraphS4mer consistently improves over existing models, including (1) seizure detection from electroencephalography signals, outperforming a previous GNN with self-supervised pretraining by 3.1 points in AUROC; (2) sleep staging from polysomnography signals, a 4.1 points improvement in macro-F1 score compared to existing sleep staging models; and (3) traffic forecasting, reducing MAE by 8.8% compared to existing GNNs and by 1.4% compared to Transformer-based models.
Automated Seizure Detection and Seizure Type Classification From Electroencephalography With a Graph Neural Network and Self-Supervised Pre-Training
Apr 16, 2021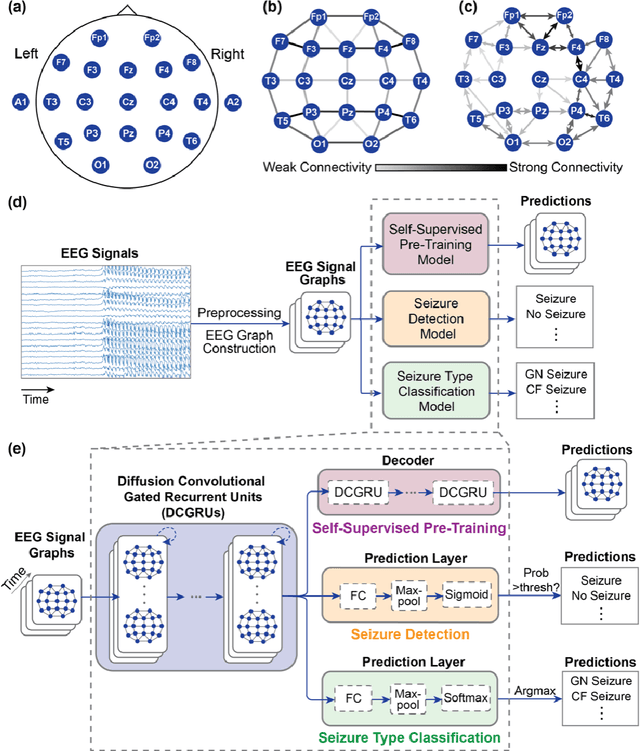
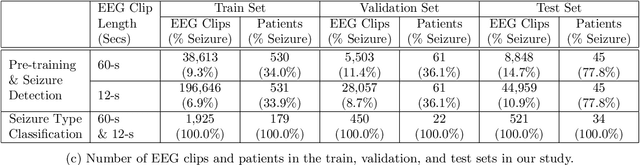
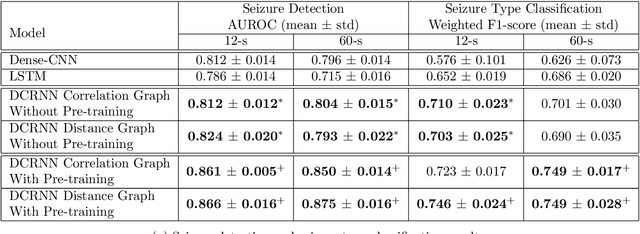
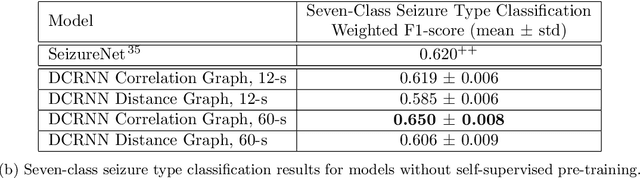
Automated seizure detection and classification from electroencephalography (EEG) can greatly improve the diagnosis and treatment of seizures. While prior studies mainly used convolutional neural networks (CNNs) that assume image-like structure in EEG signals or spectrograms, this modeling choice does not reflect the natural geometry of or connectivity between EEG electrodes. In this study, we propose modeling EEGs as graphs and present a graph neural network for automated seizure detection and classification. In addition, we leverage unlabeled EEG data using a self-supervised pre-training strategy. Our graph model with self-supervised pre-training significantly outperforms previous state-of-the-art CNN and Long Short-Term Memory (LSTM) models by 6.3 points (7.8%) in Area Under the Receiver Operating Characteristic curve (AUROC) for seizure detection and 6.3 points (9.2%) in weighted F1-score for seizure type classification. Ablation studies show that our graph-based modeling approach significantly outperforms existing CNN or LSTM models, and that self-supervision helps further improve the model performance. Moreover, we find that self-supervised pre-training substantially improves model performance on combined tonic seizures, a low-prevalence seizure type. Furthermore, our model interpretability analysis suggests that our model is better at identifying seizure regions compared to an existing CNN. In summary, our graph-based modeling approach integrates domain knowledge about EEG, sets a new state-of-the-art for seizure detection and classification on a large public dataset (5,499 EEG files), and provides better ability to identify seizure regions.
No Subclass Left Behind: Fine-Grained Robustness in Coarse-Grained Classification Problems
Nov 25, 2020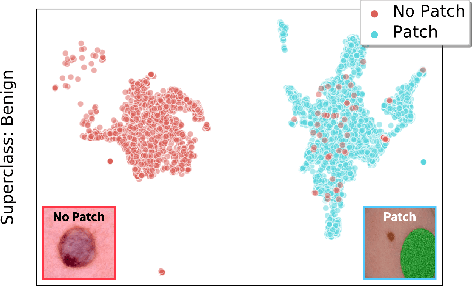
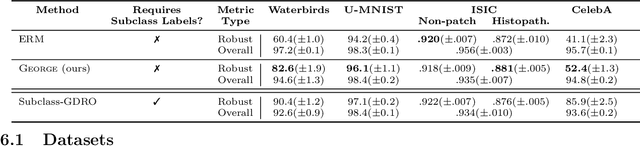


In real-world classification tasks, each class often comprises multiple finer-grained "subclasses." As the subclass labels are frequently unavailable, models trained using only the coarser-grained class labels often exhibit highly variable performance across different subclasses. This phenomenon, known as hidden stratification, has important consequences for models deployed in safety-critical applications such as medicine. We propose GEORGE, a method to both measure and mitigate hidden stratification even when subclass labels are unknown. We first observe that unlabeled subclasses are often separable in the feature space of deep models, and exploit this fact to estimate subclass labels for the training data via clustering techniques. We then use these approximate subclass labels as a form of noisy supervision in a distributionally robust optimization objective. We theoretically characterize the performance of GEORGE in terms of the worst-case generalization error across any subclass. We empirically validate GEORGE on a mix of real-world and benchmark image classification datasets, and show that our approach boosts worst-case subclass accuracy by up to 22 percentage points compared to standard training techniques, without requiring any information about the subclasses.
Data Valuation for Medical Imaging Using Shapley Value: Application on A Large-scale Chest X-ray Dataset
Oct 15, 2020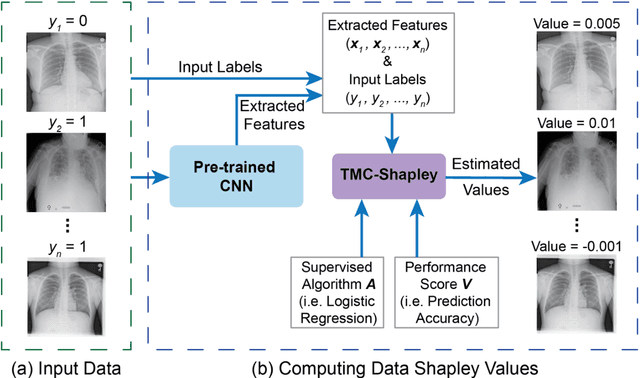
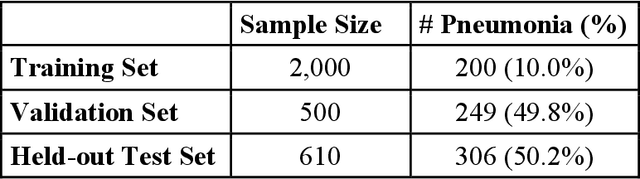
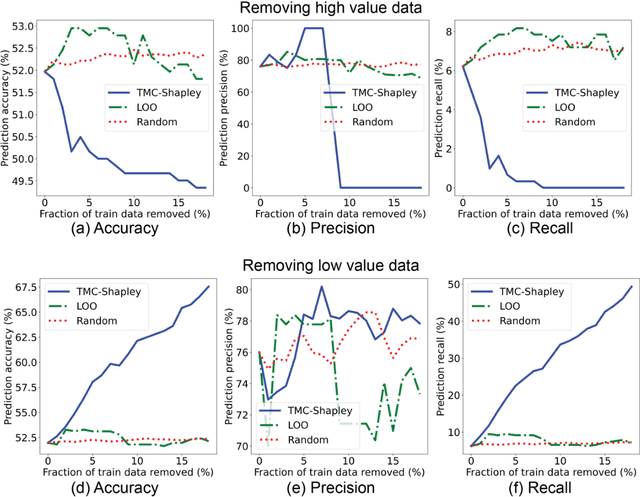

The reliability of machine learning models can be compromised when trained on low quality data. Many large-scale medical imaging datasets contain low quality labels extracted from sources such as medical reports. Moreover, images within a dataset may have heterogeneous quality due to artifacts and biases arising from equipment or measurement errors. Therefore, algorithms that can automatically identify low quality data are highly desired. In this study, we used data Shapley, a data valuation metric, to quantify the value of training data to the performance of a pneumonia detection algorithm in a large chest X-ray dataset. We characterized the effectiveness of data Shapley in identifying low quality versus valuable data for pneumonia detection. We found that removing training data with high Shapley values decreased the pneumonia detection performance, whereas removing data with low Shapley values improved the model performance. Furthermore, there were more mislabeled examples in low Shapley value data and more true pneumonia cases in high Shapley value data. Our results suggest that low Shapley value indicates mislabeled or poor quality images, whereas high Shapley value indicates data that are valuable for pneumonia detection. Our method can serve as a framework for using data Shapley to denoise large-scale medical imaging datasets.
Assessing Robustness to Noise: Low-Cost Head CT Triage
Mar 29, 2020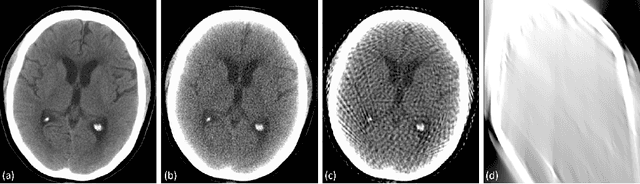

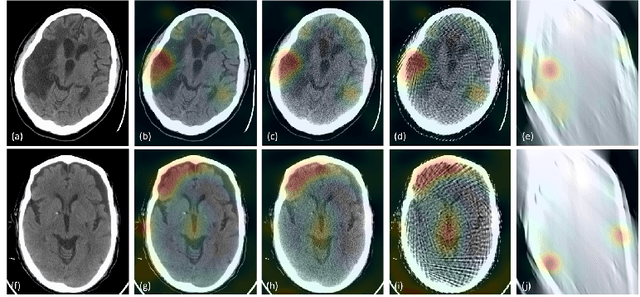
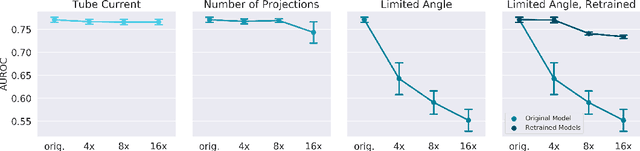
Automated medical image classification with convolutional neural networks (CNNs) has great potential to impact healthcare, particularly in resource-constrained healthcare systems where fewer trained radiologists are available. However, little is known about how well a trained CNN can perform on images with the increased noise levels, different acquisition protocols, or additional artifacts that may arise when using low-cost scanners, which can be underrepresented in datasets collected from well-funded hospitals. In this work, we investigate how a model trained to triage head computed tomography (CT) scans performs on images acquired with reduced x-ray tube current, fewer projections per gantry rotation, and limited angle scans. These changes can reduce the cost of the scanner and demands on electrical power but come at the expense of increased image noise and artifacts. We first develop a model to triage head CTs and report an area under the receiver operating characteristic curve (AUROC) of 0.77. We then show that the trained model is robust to reduced tube current and fewer projections, with the AUROC dropping only 0.65% for images acquired with a 16x reduction in tube current and 0.22% for images acquired with 8x fewer projections. Finally, for significantly degraded images acquired by a limited angle scan, we show that a model trained specifically to classify such images can overcome the technological limitations to reconstruction and maintain an AUROC within 0.09% of the original model.