 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging Transformer for MRI Denoising: a Scalable Model Architecture that enables SNR << 1 Imaging
Apr 13, 2025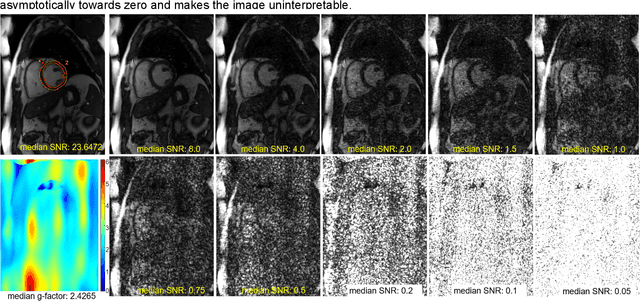

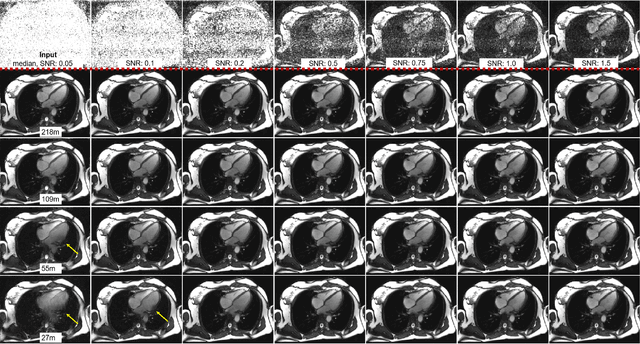
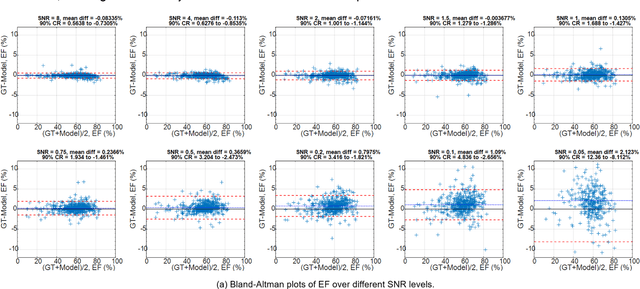
Purpose: To propose a flexible and scalable imaging transformer (IT) architecture with three attention modules for multi-dimensional imaging data and apply it to MRI denoising with very low input SNR. Methods: Three independent attention modules were developed: spatial local, spatial global, and frame attentions. They capture long-range signal correlation and bring back the locality of information in images. An attention-cell-block design processes 5D tensors ([B, C, F, H, W]) for 2D, 2D+T, and 3D image data. A High Resolution (HRNet) backbone was built to hold IT blocks. Training dataset consists of 206,677 cine series and test datasets had 7,267 series. Ten input SNR levels from 0.05 to 8.0 were tested. IT models were compared to seven convolutional and transformer baselines. To test scalability, four IT models 27m to 218m parameters were trained. Two senior cardiologists reviewed IT model outputs from which the EF was measured and compared against the ground-truth. Results: IT models significantly outperformed other models over the tested SNR levels. The performance gap was most prominent at low SNR levels. The IT-218m model had the highest SSIM and PSNR, restoring good image quality and anatomical details even at SNR 0.2. Two experts agreed at this SNR or above, the IT model output gave the same clinical interpretation as the ground-truth. The model produced images that had accurate EF measurements compared to ground-truth values. Conclusions: Imaging transformer model offers strong performance, scalability, and versatility for MR denoising. It recovers image quality suitable for confident clinical reading and accurate EF measurement, even at very low input SNR of 0.2.
A Study on Context Length and Efficient Transformers for Biomedical Image Analysis
Dec 31, 2024



Biomedical imaging modalities often produce high-resolution, multi-dimensional images that pose computational challenges for deep neural networks. These computational challenges are compounded when training transformers due to the self-attention operator, which scales quadratically with context length. Recent developments in long-context models have potential to alleviate these difficulties and enable more efficient application of transformers to large biomedical images, although a systematic evaluation on this topic is lacking. In this study, we investigate the impact of context length on biomedical image analysis and we evaluate the performance of recently proposed long-context models. We first curate a suite of biomedical imaging datasets, including 2D and 3D data for segmentation, denoising, and classification tasks. We then analyze the impact of context length on network performance using the Vision Transformer and Swin Transformer by varying patch size and attention window size. Our findings reveal a strong relationship between context length and performance, particularly for pixel-level prediction tasks. Finally, we show that recent long-context models demonstrate significant improvements in efficiency while maintaining comparable performance, though we highlight where gaps remain. This work underscores the potential and challenges of using long-context models in biomedical imaging.
Assessing Robustness to Noise: Low-Cost Head CT Triage
Mar 29, 2020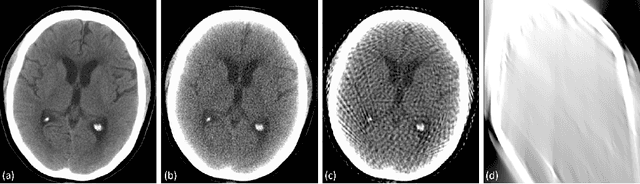

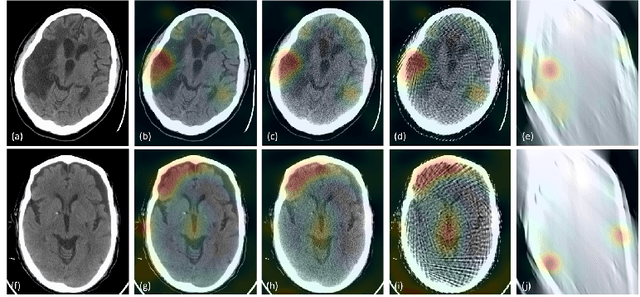
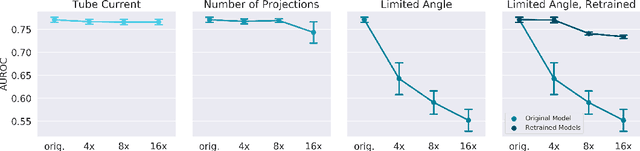
Automated medical image classification with convolutional neural networks (CNNs) has great potential to impact healthcare, particularly in resource-constrained healthcare systems where fewer trained radiologists are available. However, little is known about how well a trained CNN can perform on images with the increased noise levels, different acquisition protocols, or additional artifacts that may arise when using low-cost scanners, which can be underrepresented in datasets collected from well-funded hospitals. In this work, we investigate how a model trained to triage head computed tomography (CT) scans performs on images acquired with reduced x-ray tube current, fewer projections per gantry rotation, and limited angle scans. These changes can reduce the cost of the scanner and demands on electrical power but come at the expense of increased image noise and artifacts. We first develop a model to triage head CTs and report an area under the receiver operating characteristic curve (AUROC) of 0.77. We then show that the trained model is robust to reduced tube current and fewer projections, with the AUROC dropping only 0.65% for images acquired with a 16x reduction in tube current and 0.22% for images acquired with 8x fewer projections. Finally, for significantly degraded images acquired by a limited angle scan, we show that a model trained specifically to classify such images can overcome the technological limitations to reconstruction and maintain an AUROC within 0.09% of the original model.
Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
Feb 27, 2020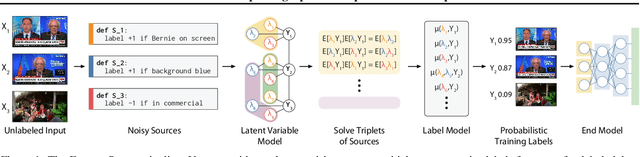
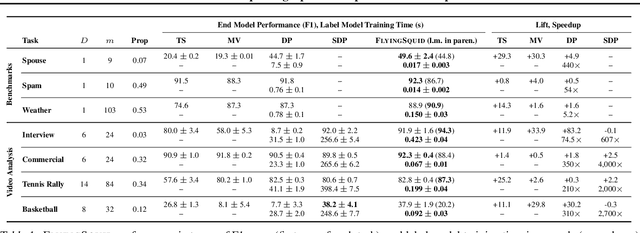

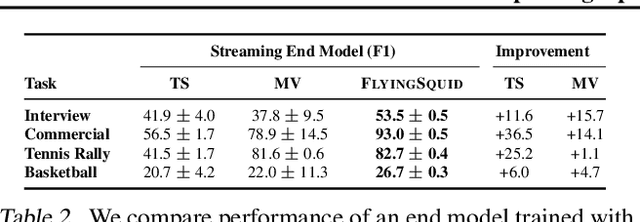
Weak supervision is a popular method for building machine learning models without relying on ground truth annotations. Instead, it generates probabilistic training labels by estimating the accuracies of multiple noisy labeling sources (e.g., heuristics, crowd workers). Existing approaches use latent variable estimation to model the noisy sources, but these methods can be computationally expensive, scaling superlinearly in the data. In this work, we show that, for a class of latent variable models highly applicable to weak supervision, we can find a closed-form solution to model parameters, obviating the need for iterative solutions like stochastic gradient descent (SGD). We use this insight to build FlyingSquid, a weak supervision framework that runs orders of magnitude faster than previous weak supervision approaches and requires fewer assumptions. In particular, we prove bounds on generalization error without assuming that the latent variable model can exactly parameterize the underlying data distribution. Empirically, we validate FlyingSquid on benchmark weak supervision datasets and find that it achieves the same or higher quality compared to previous approaches without the need to tune an SGD procedure, recovers model parameters 170 times faster on average, and enables new video analysis and online learning applications.