 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Data Programming Enables Rapid Medical Machine Learning
Paper and Code
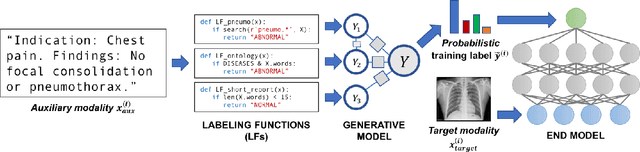
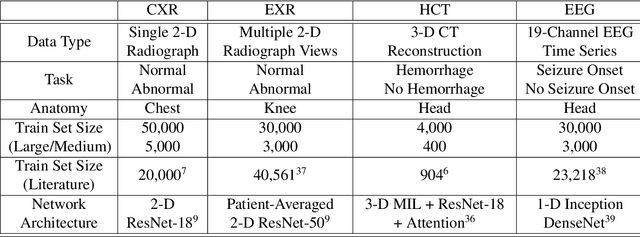
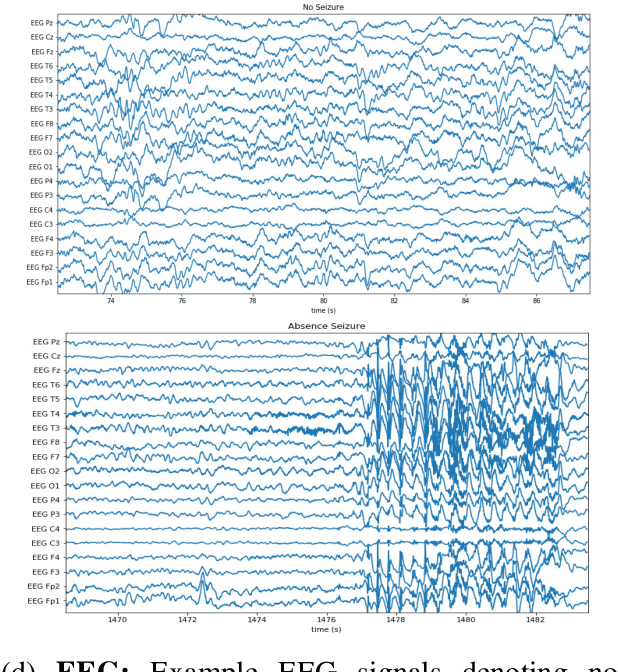

Labeling training datasets has become a key barrier to building medical machine learning models. One strategy is to generate training labels programmatically, for example by applying natural language processing pipelines to text reports associated with imaging studies. We propose cross-modal data programming, which generalizes this intuitive strategy in a theoretically-grounded way that enables simpler, clinician-driven input, reduces required labeling time, and improves with additional unlabeled data. In this approach, clinicians generate training labels for models defined over a target modality (e.g. images or time series) by writing rules over an auxiliary modality (e.g. text reports). The resulting technical challenge consists of estimating the accuracies and correlations of these rules; we extend a recent unsupervised generative modeling technique to handle this cross-modal setting in a provably consistent way. Across four applications in radiography, computed tomography, and electroencephalography, and using only several hours of clinician time, our approach matches or exceeds the efficacy of physician-months of hand-labeling with statistical significance, demonstrating a fundamentally faster and more flexible way of building machine learning models in medicine.