 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoology: Measuring and Improving Recall in Efficient Language Models
Dec 08, 2023



Attention-free language models that combine gating and convolutions are growing in popularity due to their efficiency and increasingly competitive performance. To better understand these architectures, we pretrain a suite of 17 attention and "gated-convolution" language models, finding that SoTA gated-convolution architectures still underperform attention by up to 2.1 perplexity points on the Pile. In fine-grained analysis, we find 82% of the gap is explained by each model's ability to recall information that is previously mentioned in-context, e.g. "Hakuna Matata means no worries Hakuna Matata it means no" $\rightarrow$ "??". On this task, termed "associative recall", we find that attention outperforms gated-convolutions by a large margin: a 70M parameter attention model outperforms a 1.4 billion parameter gated-convolution model on associative recall. This is surprising because prior work shows gated convolutions can perfectly solve synthetic tests for AR capability. To close the gap between synthetics and real language, we develop a new formalization of the task called multi-query associative recall (MQAR) that better reflects actual language. We perform an empirical and theoretical study of MQAR that elucidates differences in the parameter-efficiency of attention and gated-convolution recall. Informed by our analysis, we evaluate simple convolution-attention hybrids and show that hybrids with input-dependent sparse attention patterns can close 97.4% of the gap to attention, while maintaining sub-quadratic scaling. Our code is accessible at: https://github.com/HazyResearch/zoology.
Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture
Oct 18, 2023



Machine learning models are increasingly being scaled in both sequence length and model dimension to reach longer contexts and better performance. However, existing architectures such as Transformers scale quadratically along both these axes. We ask: are there performant architectures that can scale sub-quadratically along sequence length and model dimension? We introduce Monarch Mixer (M2), a new architecture that uses the same sub-quadratic primitive along both sequence length and model dimension: Monarch matrices, a simple class of expressive structured matrices that captures many linear transforms, achieves high hardware efficiency on GPUs, and scales sub-quadratically. As a proof of concept, we explore the performance of M2 in three domains: non-causal BERT-style language modeling, ViT-style image classification, and causal GPT-style language modeling. For non-causal BERT-style modeling, M2 matches BERT-base and BERT-large in downstream GLUE quality with up to 27% fewer parameters, and achieves up to 9.1$\times$ higher throughput at sequence length 4K. On ImageNet, M2 outperforms ViT-b by 1% in accuracy, with only half the parameters. Causal GPT-style models introduce a technical challenge: enforcing causality via masking introduces a quadratic bottleneck. To alleviate this bottleneck, we develop a novel theoretical view of Monarch matrices based on multivariate polynomial evaluation and interpolation, which lets us parameterize M2 to be causal while remaining sub-quadratic. Using this parameterization, M2 matches GPT-style Transformers at 360M parameters in pretraining perplexity on The PILE--showing for the first time that it may be possible to match Transformer quality without attention or MLPs.
How to Train Your HiPPO: State Space Models with Generalized Orthogonal Basis Projections
Jun 24, 2022

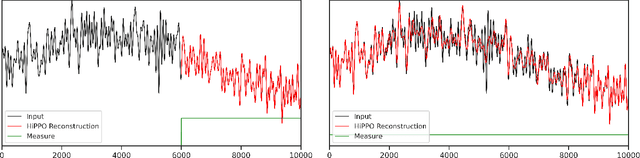

Linear time-invariant state space models (SSM) are a classical model from engineering and statistics, that have recently been shown to be very promising in machine learning through the Structured State Space sequence model (S4). A core component of S4 involves initializing the SSM state matrix to a particular matrix called a HiPPO matrix, which was empirically important for S4's ability to handle long sequences. However, the specific matrix that S4 uses was actually derived in previous work for a particular time-varying dynamical system, and the use of this matrix as a time-invariant SSM had no known mathematical interpretation. Consequently, the theoretical mechanism by which S4 models long-range dependencies actually remains unexplained. We derive a more general and intuitive formulation of the HiPPO framework, which provides a simple mathematical interpretation of S4 as a decomposition onto exponentially-warped Legendre polynomials, explaining its ability to capture long dependencies. Our generalization introduces a theoretically rich class of SSMs that also lets us derive more intuitive S4 variants for other bases such as the Fourier basis, and explains other aspects of training S4, such as how to initialize the important timescale parameter. These insights improve S4's performance to 86% on the Long Range Arena benchmark, with 96% on the most difficult Path-X task.
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
Oct 26, 2021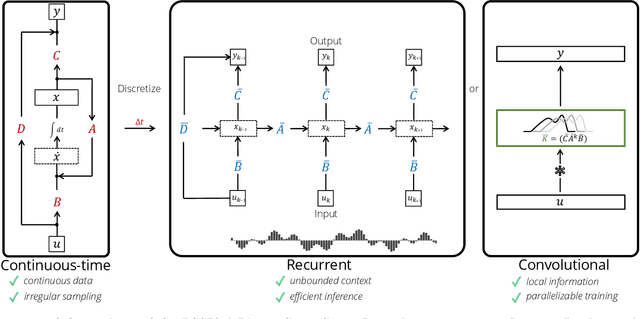
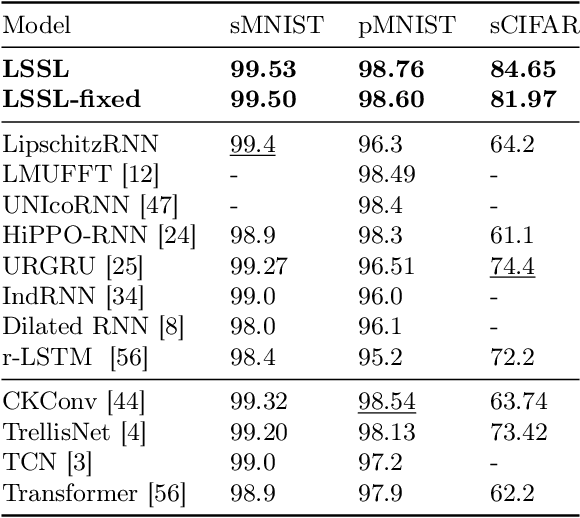
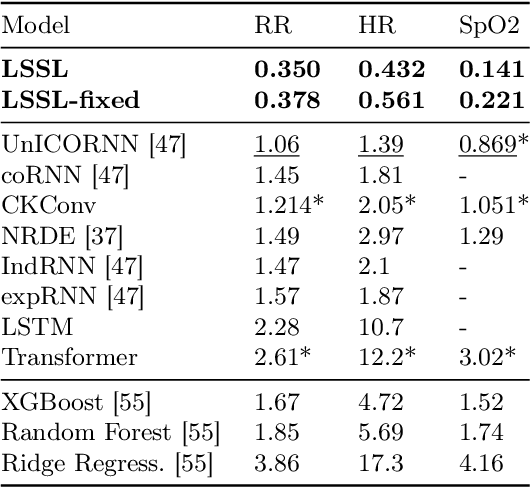
Recurrent neural networks (RNNs), temporal convolutions, and neural differential equations (NDEs) are popular families of deep learning models for time-series data, each with unique strengths and tradeoffs in modeling power and computational efficiency. We introduce a simple sequence model inspired by control systems that generalizes these approaches while addressing their shortcomings. The Linear State-Space Layer (LSSL) maps a sequence $u \mapsto y$ by simply simulating a linear continuous-time state-space representation $\dot{x} = Ax + Bu, y = Cx + Du$. Theoretically, we show that LSSL models are closely related to the three aforementioned families of models and inherit their strengths. For example, they generalize convolutions to continuous-time, explain common RNN heuristics, and share features of NDEs such as time-scale adaptation. We then incorporate and generalize recent theory on continuous-time memorization to introduce a trainable subset of structured matrices $A$ that endow LSSLs with long-range memory. Empirically, stacking LSSL layers into a simple deep neural network obtains state-of-the-art results across time series benchmarks for long dependencies in sequential image classification, real-world healthcare regression tasks, and speech. On a difficult speech classification task with length-16000 sequences, LSSL outperforms prior approaches by 24 accuracy points, and even outperforms baselines that use hand-crafted features on 100x shorter sequences.