 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOncoNet: Weakly Supervised Siamese Network to automate cancer treatment response assessment between longitudinal FDG PET/CT examinations
Aug 03, 2021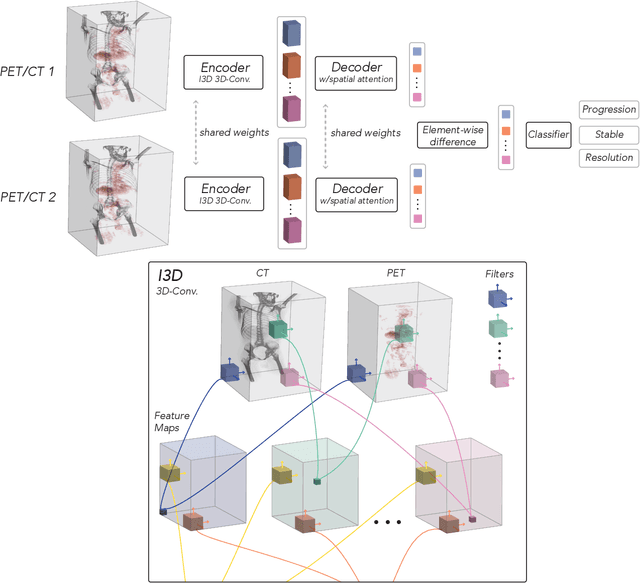

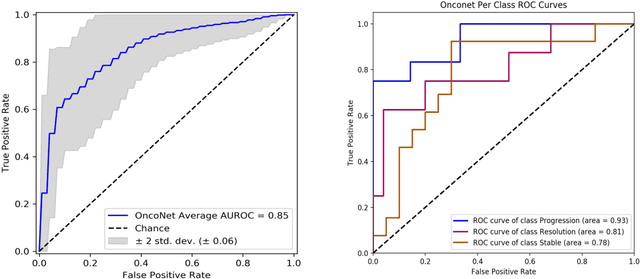
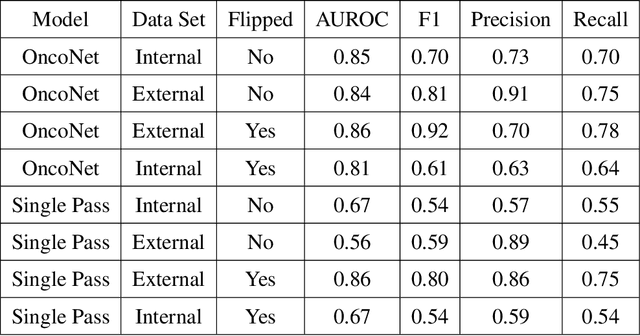
FDG PET/CT imaging is a resource intensive examination critical for managing malignant disease and is particularly important for longitudinal assessment during therapy. Approaches to automate longtudinal analysis present many challenges including lack of available longitudinal datasets, managing complex large multimodal imaging examinations, and need for detailed annotations for traditional supervised machine learning. In this work we develop OncoNet, novel machine learning algorithm that assesses treatment response from a 1,954 pairs of sequential FDG PET/CT exams through weak supervision using the standard uptake values (SUVmax) in associated radiology reports. OncoNet demonstrates an AUROC of 0.86 and 0.84 on internal and external institution test sets respectively for determination of change between scans while also showing strong agreement to clinical scoring systems with a kappa score of 0.8. We also curated a dataset of 1,954 paired FDG PET/CT exams designed for response assessment for the broader machine learning in healthcare research community. Automated assessment of radiographic response from FDG PET/CT with OncoNet could provide clinicians with a valuable tool to rapidly and consistently interpret change over time in longitudinal multi-modal imaging exams.
CheXternal: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays and External Clinical Settings
Feb 21, 2021
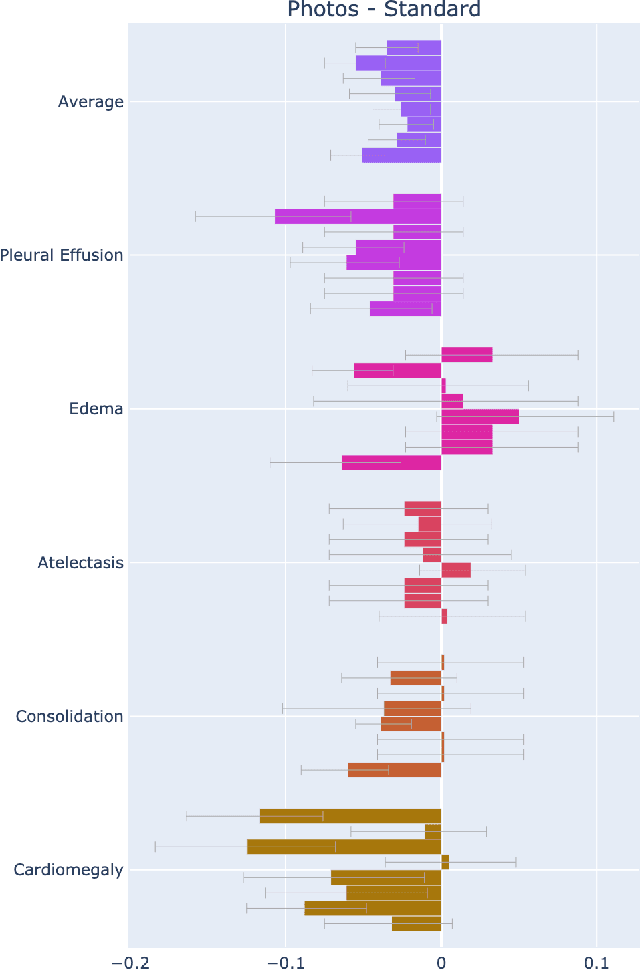


Recent advances in training deep learning models have demonstrated the potential to provide accurate chest X-ray interpretation and increase access to radiology expertise. However, poor generalization due to data distribution shifts in clinical settings is a key barrier to implementation. In this study, we measured the diagnostic performance for 8 different chest X-ray models when applied to (1) smartphone photos of chest X-rays and (2) external datasets without any finetuning. All models were developed by different groups and submitted to the CheXpert challenge, and re-applied to test datasets without further tuning. We found that (1) on photos of chest X-rays, all 8 models experienced a statistically significant drop in task performance, but only 3 performed significantly worse than radiologists on average, and (2) on the external set, none of the models performed statistically significantly worse than radiologists, and five models performed statistically significantly better than radiologists. Our results demonstrate that some chest X-ray models, under clinically relevant distribution shifts, were comparable to radiologists while other models were not. Future work should investigate aspects of model training procedures and dataset collection that influence generalization in the presence of data distribution shifts.
GloFlow: Global Image Alignment for Creation of Whole Slide Images for Pathology from Video
Nov 12, 2020
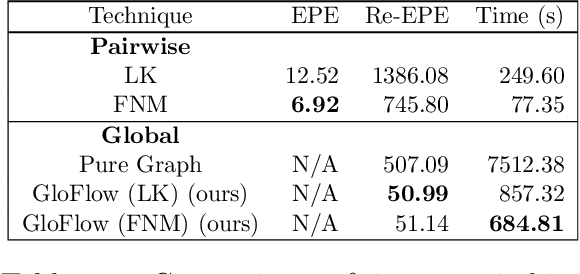
The application of deep learning to pathology assumes the existence of digital whole slide images of pathology slides. However, slide digitization is bottlenecked by the high cost of precise motor stages in slide scanners that are needed for position information used for slide stitching. We propose GloFlow, a two-stage method for creating a whole slide image using optical flow-based image registration with global alignment using a computationally tractable graph-pruning approach. In the first stage, we train an optical flow predictor to predict pairwise translations between successive video frames to approximate a stitch. In the second stage, this approximate stitch is used to create a neighborhood graph to produce a corrected stitch. On a simulated dataset of video scans of WSIs, we find that our method outperforms known approaches to slide-stitching, and stitches WSIs resembling those produced by slide scanners.
CheXphotogenic: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays
Nov 12, 2020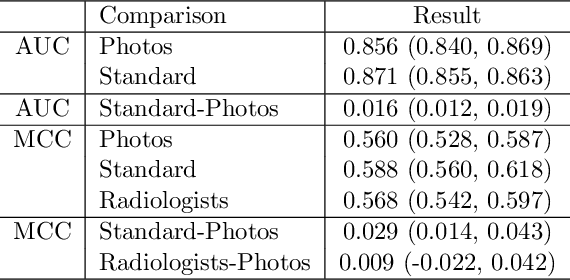
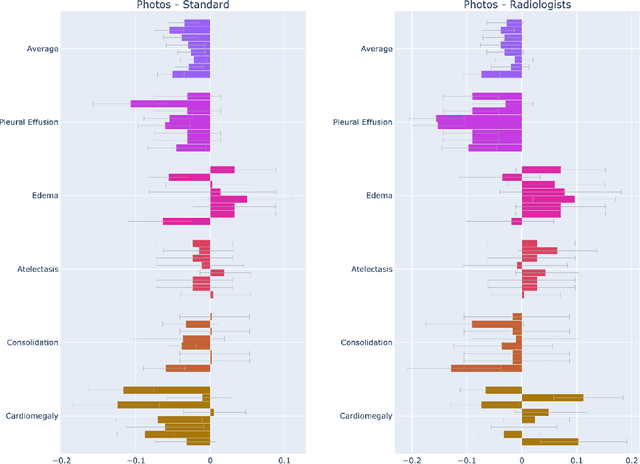
The use of smartphones to take photographs of chest x-rays represents an appealing solution for scaled deployment of deep learning models for chest x-ray interpretation. However, the performance of chest x-ray algorithms on photos of chest x-rays has not been thoroughly investigated. In this study, we measured the diagnostic performance for 8 different chest x-ray models when applied to photos of chest x-rays. All models were developed by different groups and submitted to the CheXpert challenge, and re-applied to smartphone photos of x-rays in the CheXphoto dataset without further tuning. We found that several models had a drop in performance when applied to photos of chest x-rays, but even with this drop, some models still performed comparably to radiologists. Further investigation could be directed towards understanding how different model training procedures may affect model generalization to photos of chest x-rays.
Dr. Summarize: Global Summarization of Medical Dialogue by Exploiting Local Structures
Sep 18, 2020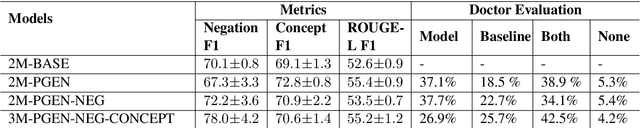
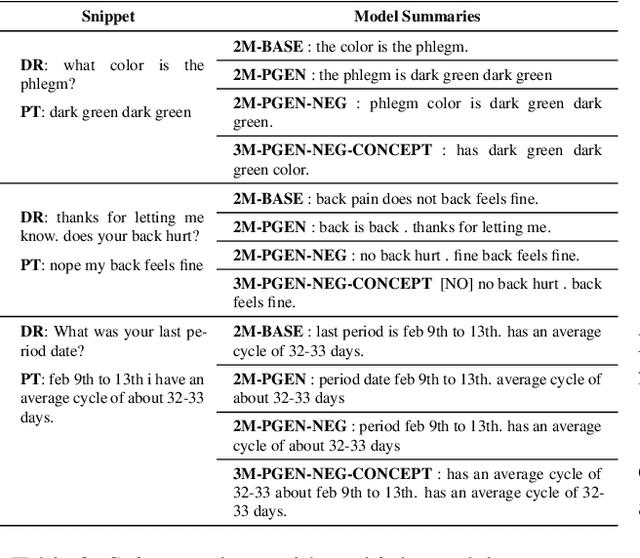
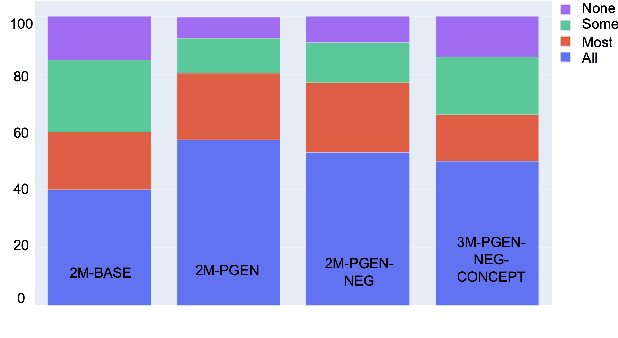
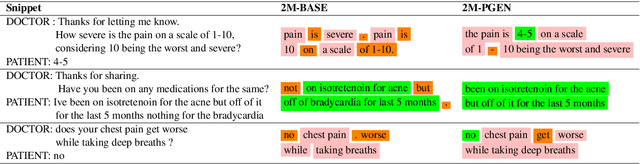
Understanding a medical conversation between a patient and a physician poses a unique natural language understanding challenge since it combines elements of standard open ended conversation with very domain specific elements that require expertise and medical knowledge. Summarization of medical conversations is a particularly important aspect of medical conversation understanding since it addresses a very real need in medical practice: capturing the most important aspects of a medical encounter so that they can be used for medical decision making and subsequent follow ups. In this paper we present a novel approach to medical conversation summarization that leverages the unique and independent local structures created when gathering a patient's medical history. Our approach is a variation of the pointer generator network where we introduce a penalty on the generator distribution, and we explicitly model negations. The model also captures important properties of medical conversations such as medical knowledge coming from standardized medical ontologies better than when those concepts are introduced explicitly. Through evaluation by doctors, we show that our approach is preferred on twice the number of summaries to the baseline pointer generator model and captures most or all of the information in 80% of the conversations making it a realistic alternative to costly manual summarization by medical experts.
CheXpedition: Investigating Generalization Challenges for Translation of Chest X-Ray Algorithms to the Clinical Setting
Mar 11, 2020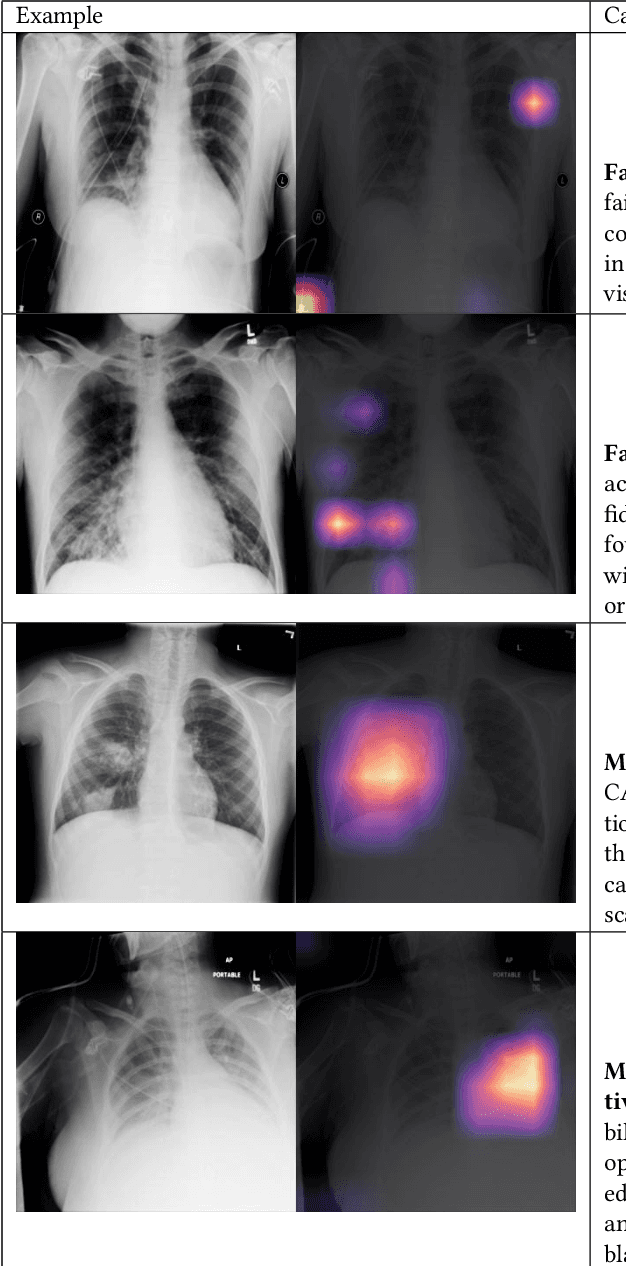
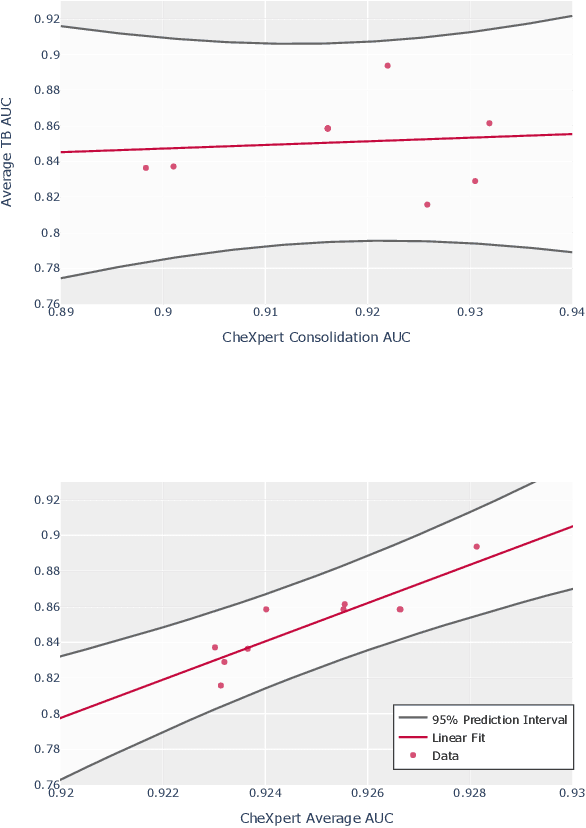
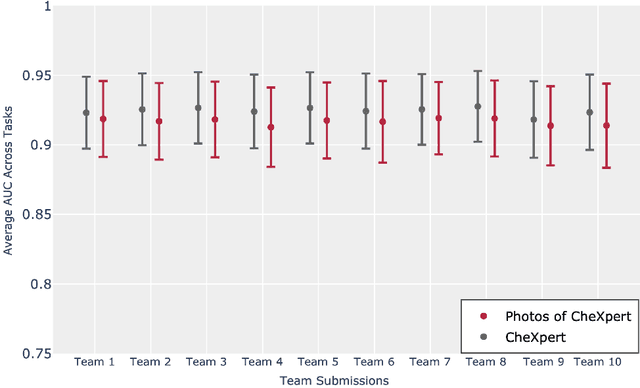
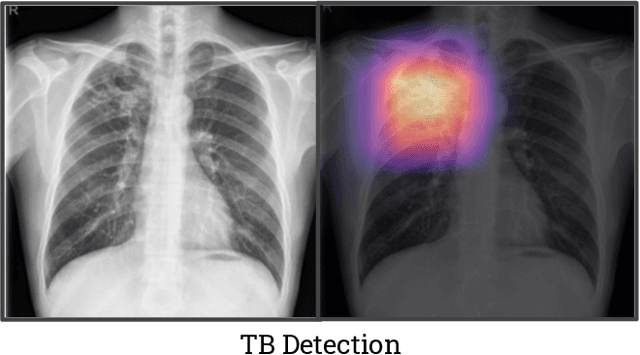
Although there have been several recent advances in the application of deep learning algorithms to chest x-ray interpretation, we identify three major challenges for the translation of chest x-ray algorithms to the clinical setting. We examine the performance of the top 10 performing models on the CheXpert challenge leaderboard on three tasks: (1) TB detection, (2) pathology detection on photos of chest x-rays, and (3) pathology detection on data from an external institution. First, we find that the top 10 chest x-ray models on the CheXpert competition achieve an average AUC of 0.851 on the task of detecting TB on two public TB datasets without fine-tuning or including the TB labels in training data. Second, we find that the average performance of the models on photos of x-rays (AUC = 0.916) is similar to their performance on the original chest x-ray images (AUC = 0.924). Third, we find that the models tested on an external dataset either perform comparably to or exceed the average performance of radiologists. We believe that our investigation will inform rapid translation of deep learning algorithms to safe and effective clinical decision support tools that can be validated prospectively with large impact studies and clinical trials.