 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSight: Towards expert-AI co-assessment for improved immunohistochemistry staining interpretation
Feb 03, 2026Immunohistochemistry (IHC) provides information on protein expression in tissue sections and is commonly used to support pathology diagnosis and disease triage. While AI models for H\&E-stained slides show promise, their applicability to IHC is limited due to domain-specific variations. Here we introduce HPA10M, a dataset that contains 10,495,672 IHC images from the Human Protein Atlas with comprehensive metadata included, and encompasses 45 normal tissue types and 20 major cancer types. Based on HPA10M, we trained iSight, a multi-task learning framework for automated IHC staining assessment. iSight combines visual features from whole-slide images with tissue metadata through a token-level attention mechanism, simultaneously predicting staining intensity, location, quantity, tissue type, and malignancy status. On held-out data, iSight achieved 85.5\% accuracy for location, 76.6\% for intensity, and 75.7\% for quantity, outperforming fine-tuned foundation models (PLIP, CONCH) by 2.5--10.2\%. In addition, iSight demonstrates well-calibrated predictions with expected calibration errors of 0.0150-0.0408. Furthermore, in a user study with eight pathologists evaluating 200 images from two datasets, iSight outperformed initial pathologist assessments on the held-out HPA dataset (79\% vs 68\% for location, 70\% vs 57\% for intensity, 68\% vs 52\% for quantity). Inter-pathologist agreement also improved after AI assistance in both held-out HPA (Cohen's $κ$ increased from 0.63 to 0.70) and Stanford TMAD datasets (from 0.74 to 0.76), suggesting expert--AI co-assessment can improve IHC interpretation. This work establishes a foundation for AI systems that can improve IHC diagnostic accuracy and highlights the potential for integrating iSight into clinical workflows to enhance the consistency and reliability of IHC assessment.
ECHO-2: A Large-Scale Distributed Rollout Framework for Cost-Efficient Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.
STEER: Inference-Time Risk Control via Constrained Quality-Diversity Search
Feb 02, 2026Large Language Models (LLMs) trained for average correctness often exhibit mode collapse, producing narrow decision behaviors on tasks where multiple responses may be reasonable. This limitation is particularly problematic in ordinal decision settings such as clinical triage, where standard alignment removes the ability to trade off specificity and sensitivity (the ROC operating point) based on contextual constraints. We propose STEER (Steerable Tuning via Evolutionary Ensemble Refinement), a training-free framework that reintroduces this tunable control. STEER constructs a population of natural-language personas through an offline, constrained quality-diversity search that promotes behavioral coverage while enforcing minimum safety, reasoning, and stability thresholds. At inference time, STEER exposes a single, interpretable control parameter that maps a user-specified risk percentile to a selected persona, yielding a monotonic adjustment of decision conservativeness. On two clinical triage benchmarks, STEER achieves broader behavioral coverage compared to temperature-based sampling and static persona ensembles. Compared to a representative post-training method, STEER maintains substantially higher accuracy on unambiguous urgent cases while providing comparable control over ambiguous decisions. These results demonstrate STEER as a safety-preserving paradigm for risk control, capable of steering behavior without compromising domain competence.
DynaWeb: Model-Based Reinforcement Learning of Web Agents
Jan 29, 2026The development of autonomous web agents, powered by Large Language Models (LLMs) and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.
MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification
Jan 21, 2026Speculative Decoding (SD) accelerates autoregressive large language model (LLM) inference by decoupling generation and verification. While recent methods improve draft quality by tightly coupling the drafter with the target model, the verification mechanism itself remains largely unchanged, relying on strict token-level rejection sampling. In practice, modern LLMs frequently operate in low-margin regimes where the target model exhibits weak preference among top candidates. In such cases, rejecting plausible runner-up tokens yields negligible information gain while incurring substantial rollback cost, leading to a fundamental inefficiency in verification. We propose Margin-Aware Speculative Verification, a training-free and domain-agnostic verification strategy that adapts to the target model's local decisiveness. Our method conditions verification on decision stability measured directly from the target logits and relaxes rejection only when strict verification provides minimal benefit. Importantly, the approach modifies only the verification rule and is fully compatible with existing target-coupled speculative decoding frameworks. Extensive experiments across model scales ranging from 8B to 235B demonstrate that our method delivers consistent and significant inference speedups over state-of-the-art baselines while preserving generation quality across diverse benchmarks.
EVM-QuestBench: An Execution-Grounded Benchmark for Natural-Language Transaction Code Generation
Jan 10, 2026Large language models are increasingly applied to various development scenarios. However, in on-chain transaction scenarios, even a minor error can cause irreversible loss for users. Existing evaluations often overlook execution accuracy and safety. We introduce EVM-QuestBench, an execution-grounded benchmark for natural-language transaction-script generation on EVM-compatible chains. The benchmark employs dynamic evaluation: instructions are sampled from template pools, numeric parameters are drawn from predefined intervals, and validators verify outcomes against these instantiated values. EVM-QuestBench contains 107 tasks (62 atomic, 45 composite). Its modular architecture enables rapid task development. The runner executes scripts on a forked EVM chain with snapshot isolation; composite tasks apply step-efficiency decay. We evaluate 20 models and find large performance gaps, with split scores revealing persistent asymmetry between single-action precision and multi-step workflow completion. Code: https://anonymous.4open.science/r/bsc_quest_bench-A9CF/.
Speculative Decoding in Decentralized LLM Inference: Turning Communication Latency into Computation Throughput
Nov 13, 2025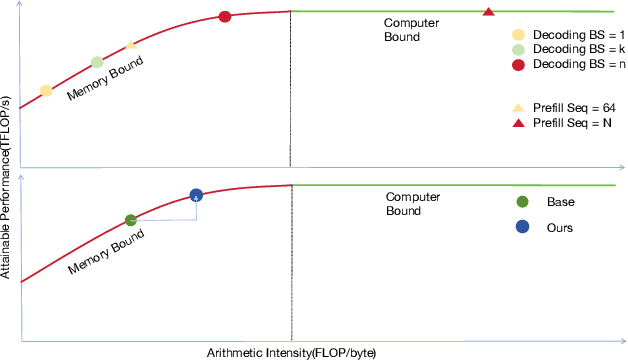
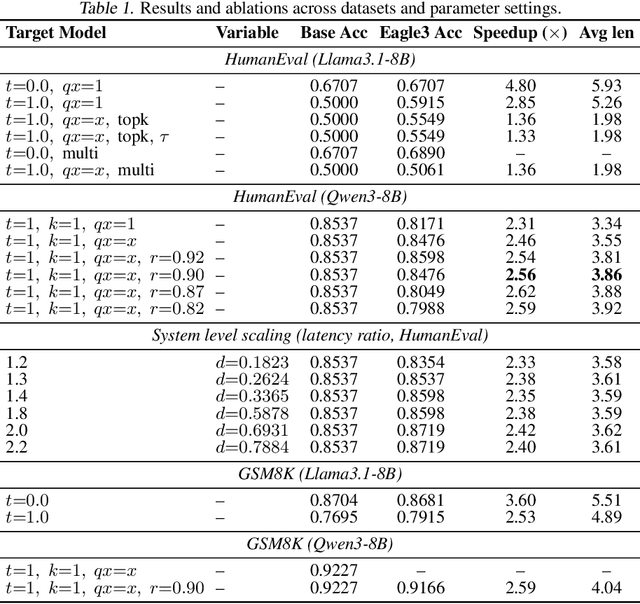

Speculative decoding accelerates large language model (LLM) inference by using a lightweight draft model to propose tokens that are later verified by a stronger target model. While effective in centralized systems, its behavior in decentralized settings, where network latency often dominates compute, remains under-characterized. We present Decentralized Speculative Decoding (DSD), a plug-and-play framework for decentralized inference that turns communication delay into useful computation by verifying multiple candidate tokens in parallel across distributed nodes. We further introduce an adaptive speculative verification strategy that adjusts acceptance thresholds by token-level semantic importance, delivering an additional 15% to 20% end-to-end speedup without retraining. In theory, DSD reduces cross-node communication cost by approximately (N-1)t1(k-1)/k, where t1 is per-link latency and k is the average number of tokens accepted per round. In practice, DSD achieves up to 2.56x speedup on HumanEval and 2.59x on GSM8K, surpassing the Eagle3 baseline while preserving accuracy. These results show that adapting speculative decoding for decentralized execution provides a system-level optimization that converts network stalls into throughput, enabling faster distributed LLM inference with no model retraining or architectural changes.
Symphony: A Decentralized Multi-Agent Framework for Scalable Collective Intelligence
Aug 27, 2025Most existing Large Language Model (LLM)-based agent frameworks rely on centralized orchestration, incurring high deployment costs, rigid communication topologies, and limited adaptability. To address these challenges, we introduce Symphony, a decentralized multi-agent system which enables lightweight LLMs on consumer-grade GPUs to coordinate. Symphony introduces three key mechanisms: (1) a decentralized ledger that records capabilities, (2) a Beacon-selection protocol for dynamic task allocation, and (3) weighted result voting based on CoTs. This design forms a privacy-saving, scalable, and fault-tolerant orchestration with low overhead. Empirically, Symphony outperforms existing baselines on reasoning benchmarks, achieving substantial accuracy gains and demonstrating robustness across models of varying capacities.
Echo: Decoupling Inference and Training for Large-Scale RL Alignment on Heterogeneous Swarms
Aug 07, 2025Modern RL-based post-training for large language models (LLMs) co-locate trajectory sampling and policy optimisation on the same GPU cluster, forcing the system to switch between inference and training workloads. This serial context switching violates the single-program-multiple-data (SPMD) assumption underlying today's distributed training systems. We present Echo, the RL system that cleanly decouples these two phases across heterogeneous "inference" and "training" swarms while preserving statistical efficiency. Echo introduces two lightweight synchronization protocols: a sequential pull mode that refreshes sampler weights on every API call for minimal bias, and an asynchronous push-pull mode that streams version-tagged rollouts through a replay buffer to maximise hardware utilisation. Training three representative RL workloads with Qwen3-4B, Qwen2.5-7B and Qwen3-32B on a geographically distributed cluster, Echo matches a fully co-located Verl baseline in convergence speed and final reward while off-loading trajectory generation to commodity edge hardware. These promising results demonstrate that large-scale RL for LLMs could achieve datacentre-grade performance using decentralised, heterogeneous resources.
AI Agents for Conversational Patient Triage: Preliminary Simulation-Based Evaluation with Real-World EHR Data
Jun 04, 2025Background: We present a Patient Simulator that leverages real world patient encounters which cover a broad range of conditions and symptoms to provide synthetic test subjects for development and testing of healthcare agentic models. The simulator provides a realistic approach to patient presentation and multi-turn conversation with a symptom-checking agent. Objectives: (1) To construct and instantiate a Patient Simulator to train and test an AI health agent, based on patient vignettes derived from real EHR data. (2) To test the validity and alignment of the simulated encounters provided by the Patient Simulator to expert human clinical providers. (3) To illustrate the evaluation framework of such an LLM system on the generated realistic, data-driven simulations -- yielding a preliminary assessment of our proposed system. Methods: We first constructed realistic clinical scenarios by deriving patient vignettes from real-world EHR encounters. These vignettes cover a variety of presenting symptoms and underlying conditions. We then evaluate the performance of the Patient Simulator as a simulacrum of a real patient encounter across over 500 different patient vignettes. We leveraged a separate AI agent to provide multi-turn questions to obtain a history of present illness. The resulting multiturn conversations were evaluated by two expert clinicians. Results: Clinicians scored the Patient Simulator as consistent with the patient vignettes in those same 97.7% of cases. The extracted case summary based on the conversation history was 99% relevant. Conclusions: We developed a methodology to incorporate vignettes derived from real healthcare patient data to build a simulation of patient responses to symptom checking agents. The performance and alignment of this Patient Simulator could be used to train and test a multi-turn conversational AI agent at scale.