 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware SQL Error Correction Using Few-Shot Learning -- A Novel Approach Based on NLQ, Error, and SQL Similarity
Paper and Code
Oct 11, 2024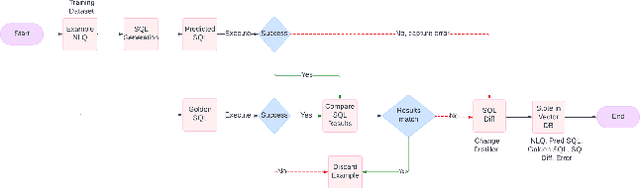
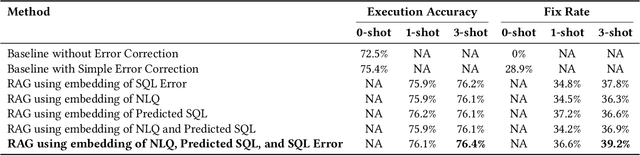
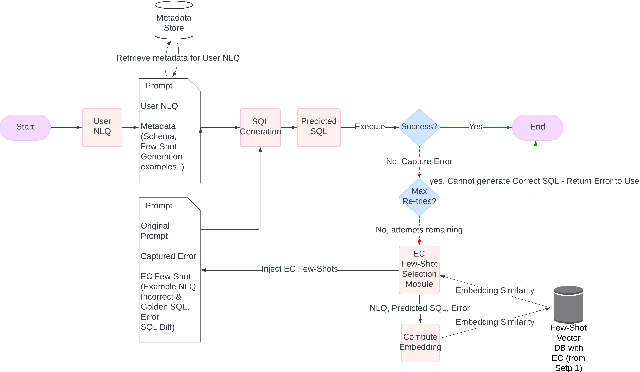
In recent years, the demand for automated SQL generation has increased significantly, driven by the need for efficient data querying in various applications. However, generating accurate SQL queries remains a challenge due to the complexity and variability of natural language inputs. This paper introduces a novel few-shot learning-based approach for error correction in SQL generation, enhancing the accuracy of generated queries by selecting the most suitable few-shot error correction examples for a given natural language question (NLQ). In our experiments with the open-source Gretel dataset, the proposed model offers a 39.2% increase in fixing errors from the baseline approach with no error correction and a 10% increase from a simple error correction method. The proposed technique leverages embedding-based similarity measures to identify the closest matches from a repository of few-shot examples. Each example comprises an incorrect SQL query, the resulting error, the correct SQL query, and detailed steps to transform the incorrect query into the correct one. By employing this method, the system can effectively guide the correction of errors in newly generated SQL queries. Our approach demonstrates significant improvements in SQL generation accuracy by providing contextually relevant examples that facilitate error identification and correction. The experimental results highlight the effectiveness of embedding-based selection in enhancing the few-shot learning process, leading to more precise and reliable SQL query generation. This research contributes to the field of automated SQL generation by offering a robust framework for error correction, paving the way for more advanced and user-friendly database interaction tools.