 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho: Learning from Experience Data via User-Driven Refinement
May 21, 2026Static "human data" faces inherent limitations: it is expensive to scale and bounded by the knowledge of its creators. Continuous learning from "experience data" - interactions between agents and their environments - promises to transcend these barriers. Today, the widespread deployment of AI agents grants us low-cost access to massive streams of such real-world experience. However, raw interaction logs are inherently noisy, filled with trial-and-error and low information density, rendering them inefficient for direct model training. We introduce Echo, a generalized framework designed to operationalize the transition from raw experience to learnable knowledge, effectively "echoing" environmental feedback back into the training loop for model optimization. In today's agent ecosystem, user refinement serves as a primary source of such feedback: driven by responsibility for the outcome, users rigorously transform flawed agent proposals into verified solutions. These user-driven refinement sequences inherently distill agents' crude attempts into high-quality training signals. Echo systematically harvests these signals to continuously align the agent with real-world needs. Large-scale validation in a production code completion environment confirms that Echo effectively harnesses this pipeline, breaking the static performance ceiling by increasing the acceptance rate from 25.7% to 35.7%.
LEPO: Latent Reasoning Policy Optimization for Large Language Models
Apr 21, 2026Recently, latent reasoning has been introduced into large language models (LLMs) to leverage rich information within a continuous space. However, without stochastic sampling, these methods inevitably collapse to deterministic inference, failing to discover diverse reasoning paths. To bridge the gap, we inject controllable stochasticity into latent reasoning via Gumbel-Softmax, restoring LLMs' exploratory capacity and enhancing their compatibility with Reinforcement Learning (RL). Building on this, we propose \textbf{\underline{L}}atent R\textbf{\underline{e}}asoning \textbf{\underline{P}}olicy \textbf{\underline{O}}ptimization~(\textbf{LEPO}), a novel framework that applies RL directly to continuous latent representations. Specifically, in rollout stage, LEPO maintains stochasticity to enable diverse trajectory sampling, while in optimization stage, LEPO constructs a unified gradient estimation for both latent representations and discrete tokens. Extensive experiments show that LEPO significantly outperforms existing RL methods for discrete and latent reasoning.
TeamLLM: A Human-Like Team-Oriented Collaboration Framework for Multi-Step Contextualized Tasks
Apr 08, 2026Recently, multi-Large Language Model (LLM) frameworks have been proposed to solve contextualized tasks. However, these frameworks do not explicitly emulate human team role division, which may lead to a single perspective, thereby weakening performance on multi-step contextualized tasks. To address this issue, we propose TeamLLM, a human-like Team-Oriented Multi-LLM Collaboration Framework. TeamLLM adopts four team roles with distinct division and employs a three-phase multi-LLM collaboration for multi-step contextualized tasks. To evaluate the effectiveness of TeamLLM on multi-step contextualized tasks, we propose Contextually-Grounded and Procedurally-Structured tasks (CGPST) and construct the CGPST benchmark. This benchmark has four core features: contextual grounding, procedural structure, process-oriented evaluation and multi-dimensional assessment. We evaluate ten popular LLMs on CGPST at overall-level, step-level, and dimension-level. Results show that TeamLLM substantially improves performance on CGPST. We release the benchmark with scenarios, full-process responses and human scores from ten LLMs. The code and data are available at https://anonymous.4open.science/r/TeamLLM-anonymous-C50E/.
UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
Which price to pay? Auto-tuning building MPC controller for optimal economic cost
Jan 18, 2025



Model predictive control (MPC) controller is considered for temperature management in buildings but its performance heavily depends on hyperparameters. Consequently, MPC necessitates meticulous hyperparameter tuning to attain optimal performance under diverse contracts. However, conventional building controller design is an open-loop process without critical hyperparameter optimization, often leading to suboptimal performance due to unexpected environmental disturbances and modeling errors. Furthermore, these hyperparameters are not adapted to different pricing schemes and may lead to non-economic operations. To address these issues, we propose an efficient performance-oriented building MPC controller tuning method based on a cutting-edge efficient constrained Bayesian optimization algorithm, CONFIG, with global optimality guarantees. We demonstrate that this technique can be applied to efficiently deal with real-world DSM program selection problems under customized black-box constraints and objectives. In this study, a simple MPC controller, which offers the advantages of reduced commissioning costs, enhanced computational efficiency, was optimized to perform on a comparable level to a delicately designed and computationally expensive MPC controller. The results also indicate that with an optimized simple MPC, the monthly electricity cost of a household can be reduced by up to 26.90% compared with the cost when controlled by a basic rule-based controller under the same constraints. Then we compared 12 real electricity contracts in Belgium for a household family with customized black-box occupant comfort constraints. The results indicate a monthly electricity bill saving up to 20.18% when the most economic contract is compared with the worst one, which again illustrates the significance of choosing a proper electricity contract.
SPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness
Oct 24, 2024



Social media is often the first place where communities discuss the latest societal trends. Prior works have utilized this platform to extract epidemic-related information (e.g. infections, preventive measures) to provide early warnings for epidemic prediction. However, these works only focused on English posts, while epidemics can occur anywhere in the world, and early discussions are often in the local, non-English languages. In this work, we introduce the first multilingual Event Extraction (EE) framework SPEED++ for extracting epidemic event information for a wide range of diseases and languages. To this end, we extend a previous epidemic ontology with 20 argument roles; and curate our multilingual EE dataset SPEED++ comprising 5.1K tweets in four languages for four diseases. Annotating data in every language is infeasible; thus we develop zero-shot cross-lingual cross-disease models (i.e., training only on English COVID data) utilizing multilingual pre-training and show their efficacy in extracting epidemic-related events for 65 diverse languages across different diseases. Experiments demonstrate that our framework can provide epidemic warnings for COVID-19 in its earliest stages in Dec 2019 (3 weeks before global discussions) from Chinese Weibo posts without any training in Chinese. Furthermore, we exploit our framework's argument extraction capabilities to aggregate community epidemic discussions like symptoms and cure measures, aiding misinformation detection and public attention monitoring. Overall, we lay a strong foundation for multilingual epidemic preparedness.
Event Detection from Social Media for Epidemic Prediction
Apr 02, 2024



Social media is an easy-to-access platform providing timely updates about societal trends and events. Discussions regarding epidemic-related events such as infections, symptoms, and social interactions can be crucial for informing policymaking during epidemic outbreaks. In our work, we pioneer exploiting Event Detection (ED) for better preparedness and early warnings of any upcoming epidemic by developing a framework to extract and analyze epidemic-related events from social media posts. To this end, we curate an epidemic event ontology comprising seven disease-agnostic event types and construct a Twitter dataset SPEED with human-annotated events focused on the COVID-19 pandemic. Experimentation reveals how ED models trained on COVID-based SPEED can effectively detect epidemic events for three unseen epidemics of Monkeypox, Zika, and Dengue; while models trained on existing ED datasets fail miserably. Furthermore, we show that reporting sharp increases in the extracted events by our framework can provide warnings 4-9 weeks earlier than the WHO epidemic declaration for Monkeypox. This utility of our framework lays the foundations for better preparedness against emerging epidemics.
CgT-GAN: CLIP-guided Text GAN for Image Captioning
Aug 23, 2023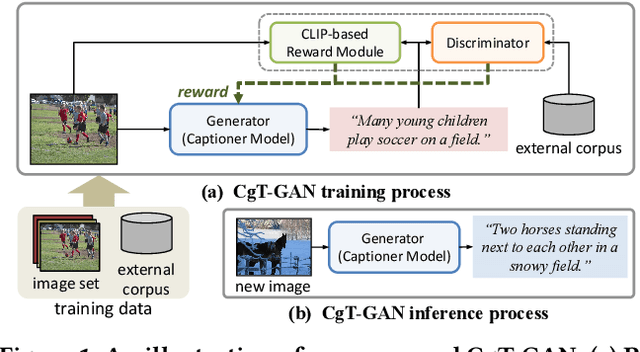
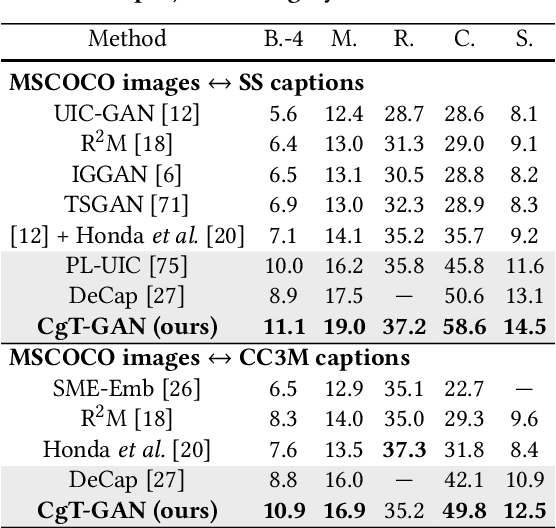
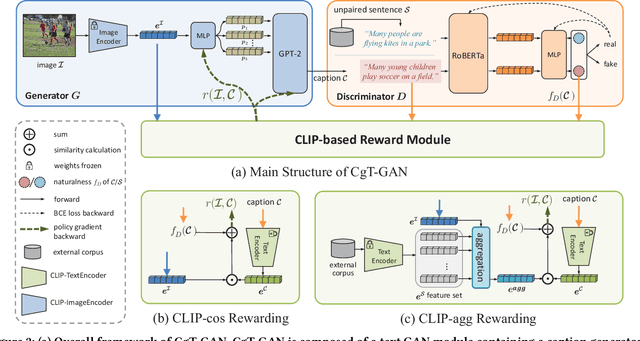
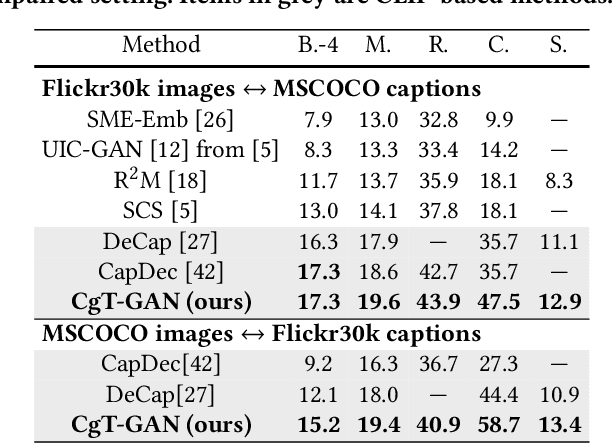
The large-scale visual-language pre-trained model, Contrastive Language-Image Pre-training (CLIP), has significantly improved image captioning for scenarios without human-annotated image-caption pairs. Recent advanced CLIP-based image captioning without human annotations follows a text-only training paradigm, i.e., reconstructing text from shared embedding space. Nevertheless, these approaches are limited by the training/inference gap or huge storage requirements for text embeddings. Given that it is trivial to obtain images in the real world, we propose CLIP-guided text GAN (CgT-GAN), which incorporates images into the training process to enable the model to "see" real visual modality. Particularly, we use adversarial training to teach CgT-GAN to mimic the phrases of an external text corpus and CLIP-based reward to provide semantic guidance. The caption generator is jointly rewarded based on the caption naturalness to human language calculated from the GAN's discriminator and the semantic guidance reward computed by the CLIP-based reward module. In addition to the cosine similarity as the semantic guidance reward (i.e., CLIP-cos), we further introduce a novel semantic guidance reward called CLIP-agg, which aligns the generated caption with a weighted text embedding by attentively aggregating the entire corpus. Experimental results on three subtasks (ZS-IC, In-UIC and Cross-UIC) show that CgT-GAN outperforms state-of-the-art methods significantly across all metrics. Code is available at https://github.com/Lihr747/CgtGAN.