 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEED++: A Multilingual Event Extraction Framework for Epidemic Prediction and Preparedness
Oct 24, 2024



Social media is often the first place where communities discuss the latest societal trends. Prior works have utilized this platform to extract epidemic-related information (e.g. infections, preventive measures) to provide early warnings for epidemic prediction. However, these works only focused on English posts, while epidemics can occur anywhere in the world, and early discussions are often in the local, non-English languages. In this work, we introduce the first multilingual Event Extraction (EE) framework SPEED++ for extracting epidemic event information for a wide range of diseases and languages. To this end, we extend a previous epidemic ontology with 20 argument roles; and curate our multilingual EE dataset SPEED++ comprising 5.1K tweets in four languages for four diseases. Annotating data in every language is infeasible; thus we develop zero-shot cross-lingual cross-disease models (i.e., training only on English COVID data) utilizing multilingual pre-training and show their efficacy in extracting epidemic-related events for 65 diverse languages across different diseases. Experiments demonstrate that our framework can provide epidemic warnings for COVID-19 in its earliest stages in Dec 2019 (3 weeks before global discussions) from Chinese Weibo posts without any training in Chinese. Furthermore, we exploit our framework's argument extraction capabilities to aggregate community epidemic discussions like symptoms and cure measures, aiding misinformation detection and public attention monitoring. Overall, we lay a strong foundation for multilingual epidemic preparedness.
Improving Lesion Detection by exploring bias on Skin Lesion dataset
Oct 04, 2020
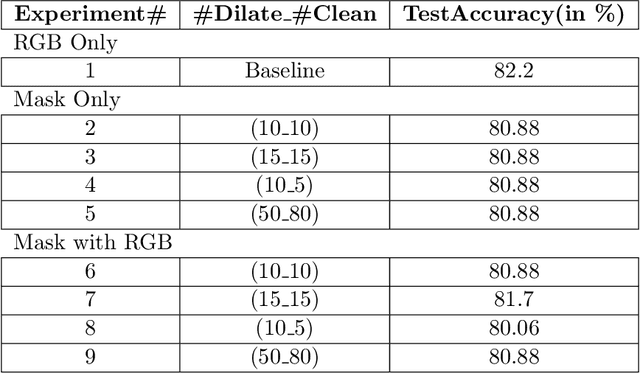
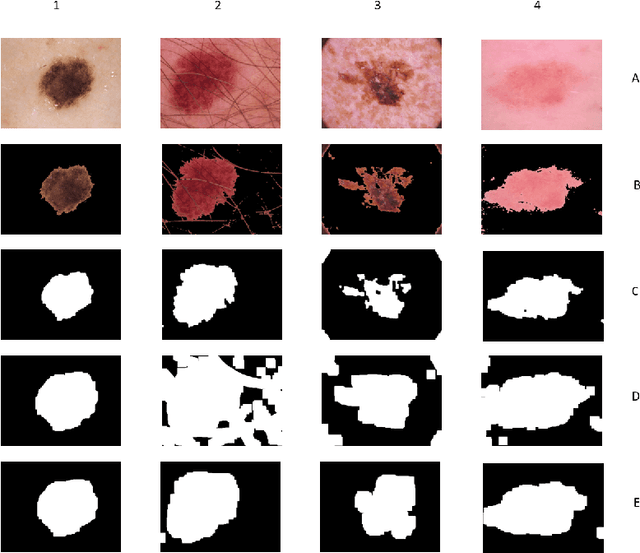
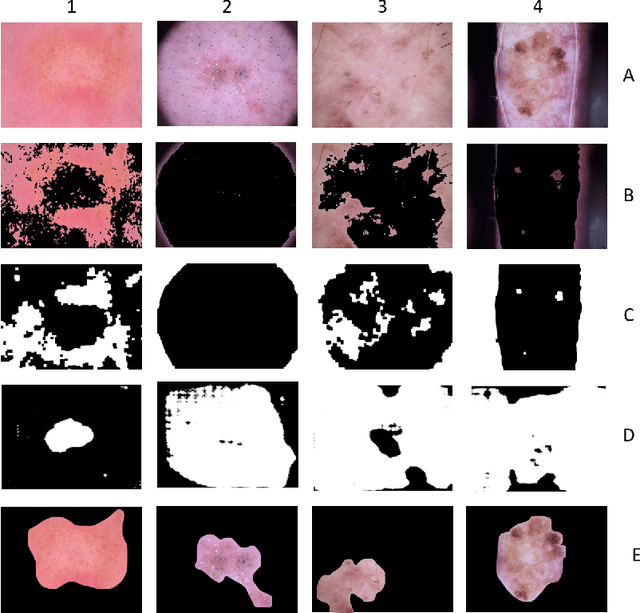
All datasets contain some biases, often unintentional, due to how they were acquired and annotated. These biases distort machine-learning models' performance, creating spurious correlations that the models can unfairly exploit, or, contrarily destroying clear correlations that the models could learn. With the popularity of deep learning models, automated skin lesion analysis is starting to play an essential role in the early detection of Melanoma. The ISIC Archive is one of the most used skin lesion sources to benchmark deep learning-based tools. Bissoto et al. experimented with different bounding-box based masks and showed that deep learning models could classify skin lesion images without clinically meaningful information in the input data. Their findings seem confounding since the ablated regions (random rectangular boxes) are not significant. The shape of the lesion is a crucial factor in the clinical characterization of a skin lesion. In that context, we performed a set of experiments that generate shape-preserving masks instead of rectangular bounding-box based masks. A deep learning model trained on these shape-preserving masked images does not outperform models trained on images without clinically meaningful information. That strongly suggests spurious correlations guiding the models. We propose use of general adversarial network (GAN) to mitigate the underlying bias.