 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Optimizing RAG for Domain Chatbots
Jan 10, 2024



With the advent of Large Language Models (LLM), conversational assistants have become prevalent for domain use cases. LLMs acquire the ability to contextual question answering through training, and Retrieval Augmented Generation (RAG) further enables the bot to answer domain-specific questions. This paper describes a RAG-based approach for building a chatbot that answers user's queries using Frequently Asked Questions (FAQ) data. We train an in-house retrieval embedding model using infoNCE loss, and experimental results demonstrate that the in-house model works significantly better than the well-known general-purpose public embedding model, both in terms of retrieval accuracy and Out-of-Domain (OOD) query detection. As an LLM, we use an open API-based paid ChatGPT model. We noticed that a previously retrieved-context could be used to generate an answer for specific patterns/sequences of queries (e.g., follow-up queries). Hence, there is a scope to optimize the number of LLM tokens and cost. Assuming a fixed retrieval model and an LLM, we optimize the number of LLM tokens using Reinforcement Learning (RL). Specifically, we propose a policy-based model external to the RAG, which interacts with the RAG pipeline through policy actions and updates the policy to optimize the cost. The policy model can perform two actions: to fetch FAQ context or skip retrieval. We use the open API-based GPT-4 as the reward model. We then train a policy model using policy gradient on multiple training chat sessions. As a policy model, we experimented with a public gpt-2 model and an in-house BERT model. With the proposed RL-based optimization combined with similarity threshold, we are able to achieve significant cost savings while getting a slightly improved accuracy. Though we demonstrate results for the FAQ chatbot, the proposed RL approach is generic and can be experimented with any existing RAG pipeline.
Retinal Microvasculature as Biomarker for Diabetes and Cardiovascular Diseases
Jul 28, 2021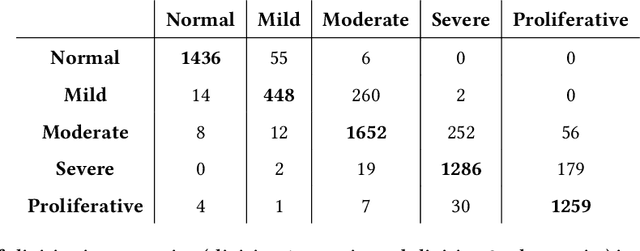
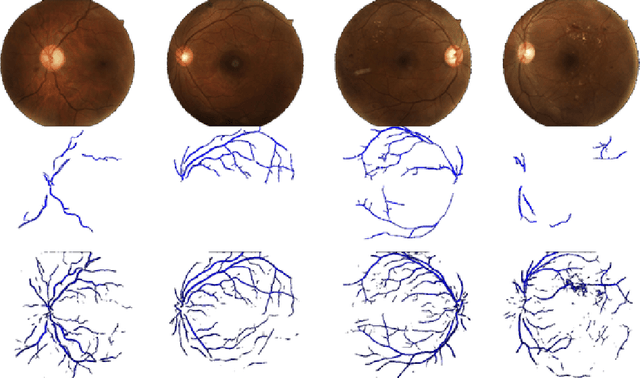
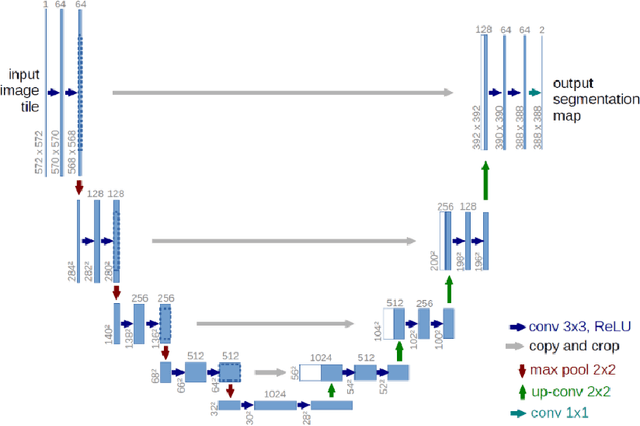
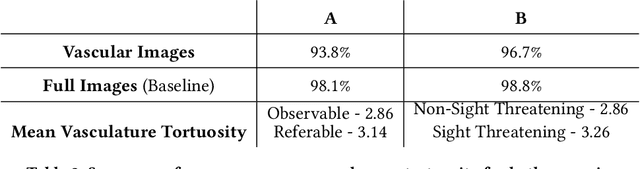
Purpose: To demonstrate that retinal microvasculature per se is a reliable biomarker for Diabetic Retinopathy (DR) and, by extension, cardiovascular diseases. Methods: Deep Learning Convolutional Neural Networks (CNN) applied to color fundus images for semantic segmentation of the blood vessels and severity classification on both vascular and full images. Vessel reconstruction through harmonic descriptors is also used as a smoothing and de-noising tool. The mathematical background of the theory is also outlined. Results: For diabetic patients, at least 93.8% of DR No-Refer vs. Refer classification can be related to vasculature defects. As for the Non-Sight Threatening vs. Sight Threatening case, the ratio is as high as 96.7%. Conclusion: In the case of DR, most of the disease biomarkers are related topologically to the vasculature. Translational Relevance: Experiments conducted on eye blood vasculature reconstruction as a biomarker shows a strong correlation between vasculature shape and later stages of DR.
Defending Democracy: Using Deep Learning to Identify and Prevent Misinformation
Jun 03, 2021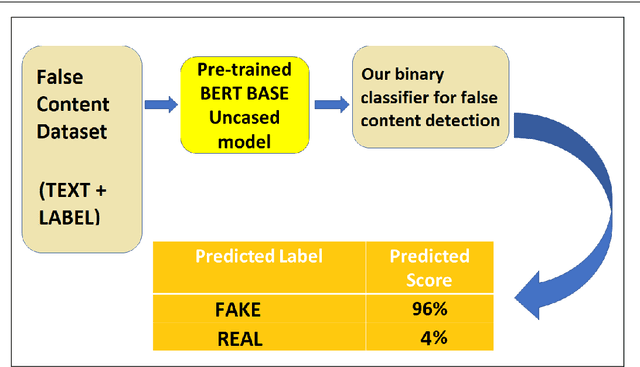

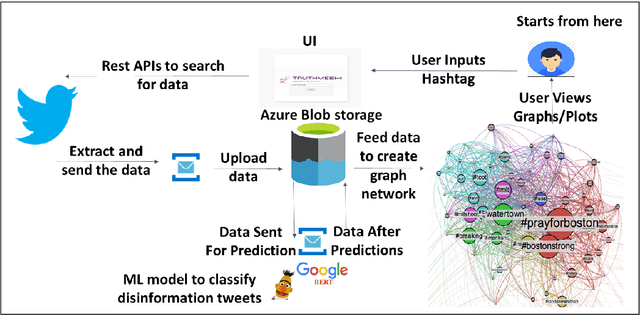
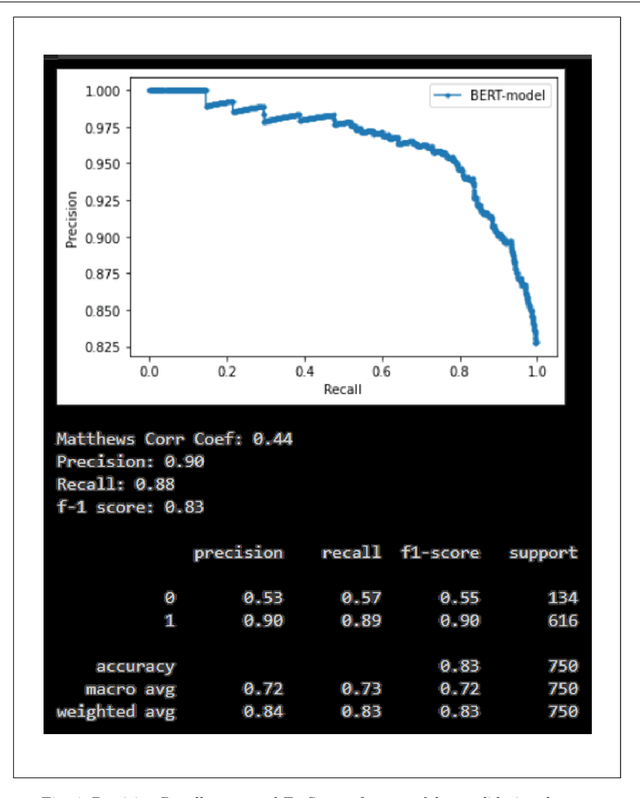
The rise in online misinformation in recent years threatens democracies by distorting authentic public discourse and causing confusion, fear, and even, in extreme cases, violence. There is a need to understand the spread of false content through online networks for developing interventions that disrupt misinformation before it achieves virality. Using a Deep Bidirectional Transformer for Language Understanding (BERT) and propagation graphs, this study classifies and visualizes the spread of misinformation on a social media network using publicly available Twitter data. The results confirm prior research around user clusters and the virality of false content while improving the precision of deep learning models for misinformation detection. The study further demonstrates the suitability of BERT for providing a scalable model for false information detection, which can contribute to the development of more timely and accurate interventions to slow the spread of misinformation in online environments.
Height Estimation of Children under Five Years using Depth Images
May 04, 2021

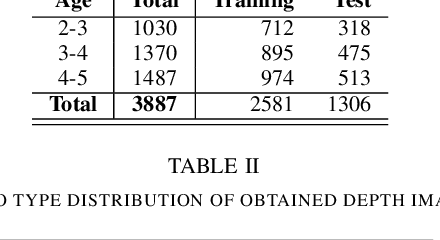
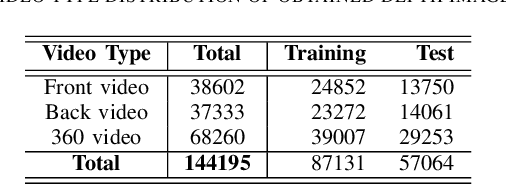
Malnutrition is a global health crisis and is the leading cause of death among children under five. Detecting malnutrition requires anthropometric measurements of weight, height, and middle-upper arm circumference. However, measuring them accurately is a challenge, especially in the global south, due to limited resources. In this work, we propose a CNN-based approach to estimate the height of standing children under five years from depth images collected using a smart-phone. According to the SMART Methodology Manual [5], the acceptable accuracy for height is less than 1.4 cm. On training our deep learning model on 87131 depth images, our model achieved an average mean absolute error of 1.64% on 57064 test images. For 70.3% test images, we estimated height accurately within the acceptable 1.4 cm range. Thus, our proposed solution can accurately detect stunting (low height-for-age) in standing children below five years of age.
Improving Lesion Detection by exploring bias on Skin Lesion dataset
Oct 04, 2020
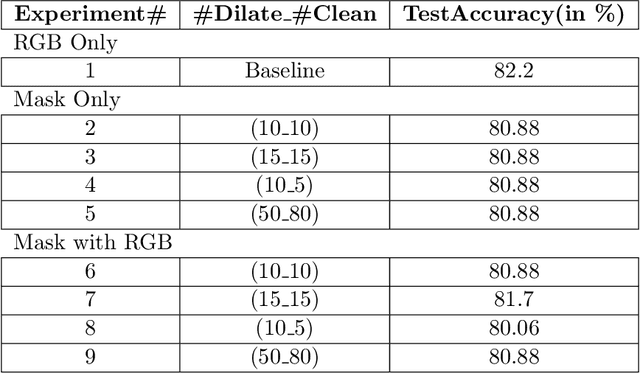
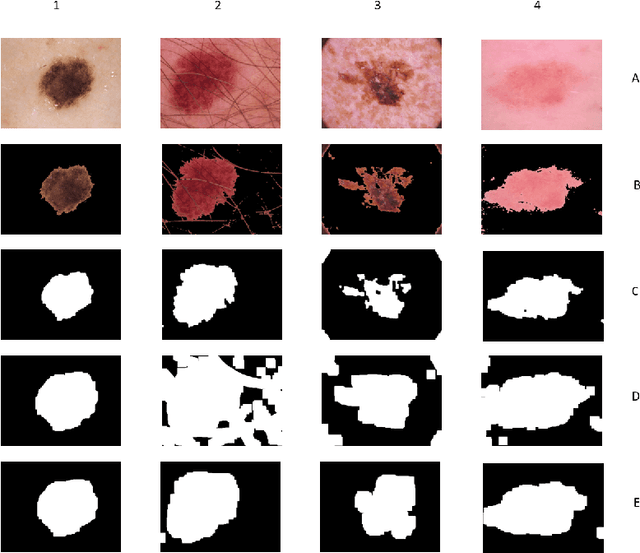
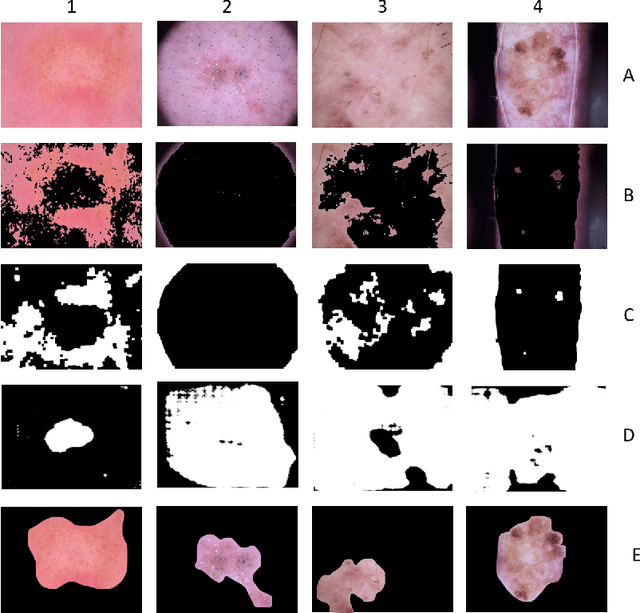
All datasets contain some biases, often unintentional, due to how they were acquired and annotated. These biases distort machine-learning models' performance, creating spurious correlations that the models can unfairly exploit, or, contrarily destroying clear correlations that the models could learn. With the popularity of deep learning models, automated skin lesion analysis is starting to play an essential role in the early detection of Melanoma. The ISIC Archive is one of the most used skin lesion sources to benchmark deep learning-based tools. Bissoto et al. experimented with different bounding-box based masks and showed that deep learning models could classify skin lesion images without clinically meaningful information in the input data. Their findings seem confounding since the ablated regions (random rectangular boxes) are not significant. The shape of the lesion is a crucial factor in the clinical characterization of a skin lesion. In that context, we performed a set of experiments that generate shape-preserving masks instead of rectangular bounding-box based masks. A deep learning model trained on these shape-preserving masked images does not outperform models trained on images without clinically meaningful information. That strongly suggests spurious correlations guiding the models. We propose use of general adversarial network (GAN) to mitigate the underlying bias.
Protecting GANs against privacy attacks by preventing overfitting
Jan 03, 2020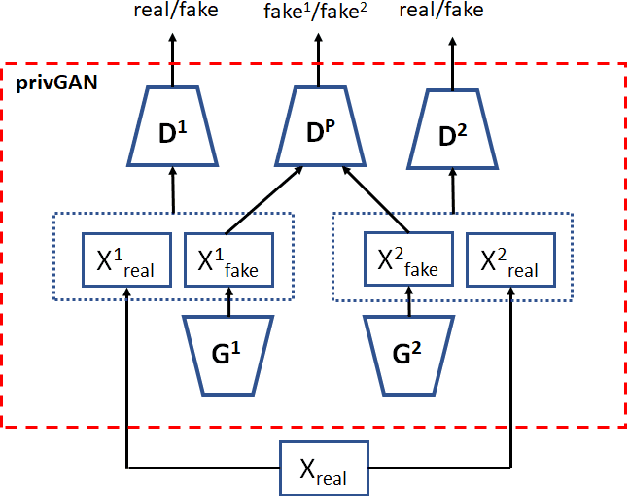


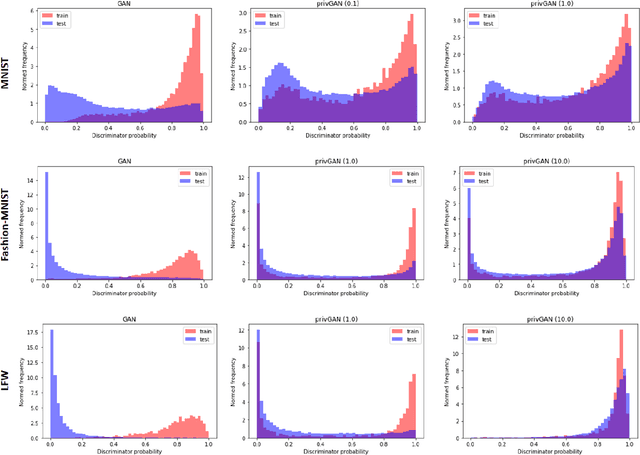
Generative Adversarial Networks (GANs) have made releasing of synthetic images a viable approach to share data without releasing the original dataset. It has been shown that such synthetic data can be used for a variety of downstream tasks such as training classifiers that would otherwise require the original dataset to be shared. However, recent work has shown that the GAN models and their synthetically generated data can be used to infer the training set membership by an adversary who has access to the entire dataset and some auxiliary information. Here we develop a new GAN architecture (privGAN) which provides protection against this mode of attack while leading to negligible loss in downstream performances. Our architecture explicitly prevents overfitting to the training set thereby providing implicit protection against white-box attacks. The main contributions of this paper are: i) we propose a novel GAN architecture that can generate synthetic data in a privacy preserving manner and demonstrate the effectiveness of our model against white--box attacks on several benchmark datasets, ii) we provide a theoretical understanding of the optimal solution of the GAN loss function, iii) we demonstrate on two common benchmark datasets that synthetic images generated by privGAN lead to negligible loss in downstream performance when compared against non--private GANs. While we have focosued on benchmarking privGAN exclusively of image datasets, the architecture of privGAN is not exclusive to image datasets and can be easily extended to other types of datasets.
Risks of Using Non-verified Open Data: A case study on using Machine Learning techniques for predicting Pregnancy Outcomes in India
Oct 21, 2019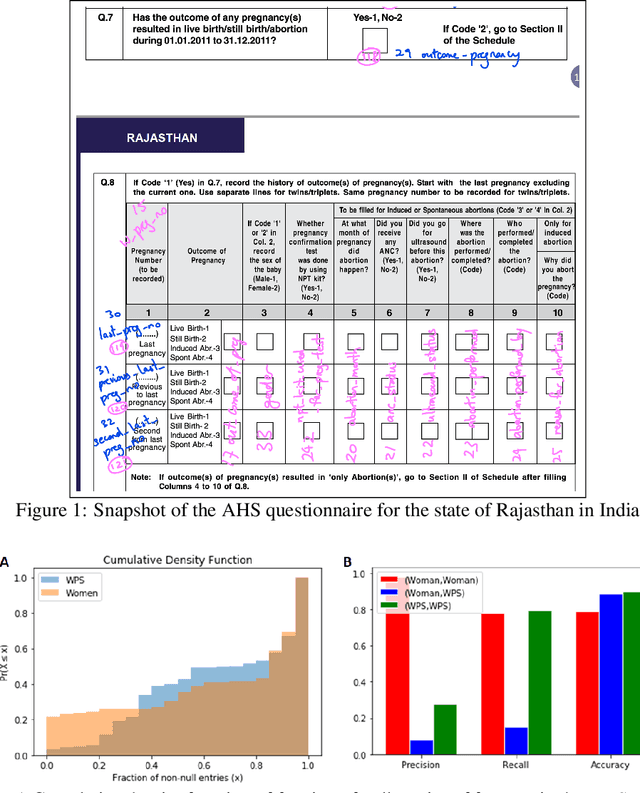
Artificial intelligence (AI) has evolved considerably in the last few years. While applications of AI is now becoming more common in fields like retail and marketing, application of AI in solving problems related to developing countries is still an emerging topic. Specially, AI applications in resource-poor settings remains relatively nascent. There is a huge scope of AI being used in such settings. For example, researchers have started exploring AI applications to reduce poverty and deliver a broad range of critical public services. However, despite many promising use cases, there are many dataset related challenges that one has to overcome in such projects. These challenges often take the form of missing data, incorrectly collected data and improperly labeled variables, among other factors. As a result, we can often end up using data that is not representative of the problem we are trying to solve. In this case study, we explore the challenges of using such an open dataset from India, to predict an important health outcome. We highlight how the use of AI without proper understanding of reporting metrics can lead to erroneous conclusions.