 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich price to pay? Auto-tuning building MPC controller for optimal economic cost
Jan 18, 2025Model predictive control (MPC) controller is considered for temperature management in buildings but its performance heavily depends on hyperparameters. Consequently, MPC necessitates meticulous hyperparameter tuning to attain optimal performance under diverse contracts. However, conventional building controller design is an open-loop process without critical hyperparameter optimization, often leading to suboptimal performance due to unexpected environmental disturbances and modeling errors. Furthermore, these hyperparameters are not adapted to different pricing schemes and may lead to non-economic operations. To address these issues, we propose an efficient performance-oriented building MPC controller tuning method based on a cutting-edge efficient constrained Bayesian optimization algorithm, CONFIG, with global optimality guarantees. We demonstrate that this technique can be applied to efficiently deal with real-world DSM program selection problems under customized black-box constraints and objectives. In this study, a simple MPC controller, which offers the advantages of reduced commissioning costs, enhanced computational efficiency, was optimized to perform on a comparable level to a delicately designed and computationally expensive MPC controller. The results also indicate that with an optimized simple MPC, the monthly electricity cost of a household can be reduced by up to 26.90% compared with the cost when controlled by a basic rule-based controller under the same constraints. Then we compared 12 real electricity contracts in Belgium for a household family with customized black-box occupant comfort constraints. The results indicate a monthly electricity bill saving up to 20.18% when the most economic contract is compared with the worst one, which again illustrates the significance of choosing a proper electricity contract.
Principled Bayesian Optimisation in Collaboration with Human Experts
Oct 14, 2024



Bayesian optimisation for real-world problems is often performed interactively with human experts, and integrating their domain knowledge is key to accelerate the optimisation process. We consider a setup where experts provide advice on the next query point through binary accept/reject recommendations (labels). Experts' labels are often costly, requiring efficient use of their efforts, and can at the same time be unreliable, requiring careful adjustment of the degree to which any expert is trusted. We introduce the first principled approach that provides two key guarantees. (1) Handover guarantee: similar to a no-regret property, we establish a sublinear bound on the cumulative number of experts' binary labels. Initially, multiple labels per query are needed, but the number of expert labels required asymptotically converges to zero, saving both expert effort and computation time. (2) No-harm guarantee with data-driven trust level adjustment: our adaptive trust level ensures that the convergence rate will not be worse than the one without using advice, even if the advice from experts is adversarial. Unlike existing methods that employ a user-defined function that hand-tunes the trust level adjustment, our approach enables data-driven adjustments. Real-world applications empirically demonstrate that our method not only outperforms existing baselines, but also maintains robustness despite varying labelling accuracy, in tasks of battery design with human experts.
Principled Preferential Bayesian Optimization
Feb 08, 2024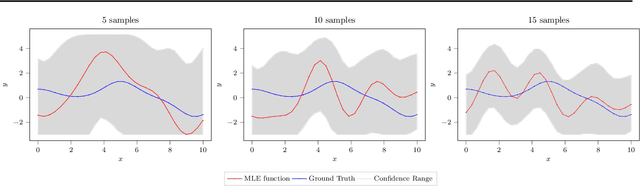
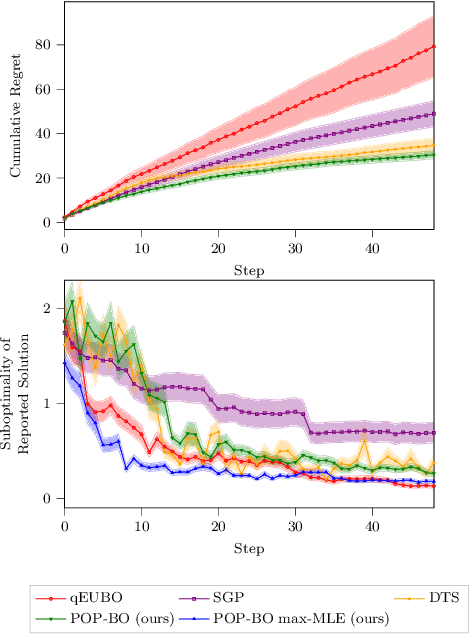
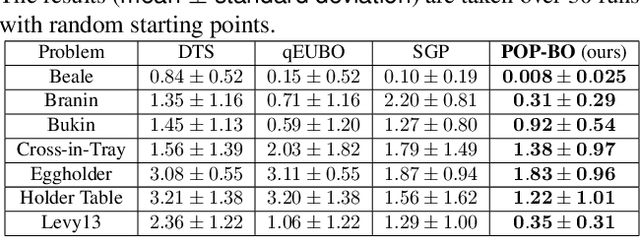
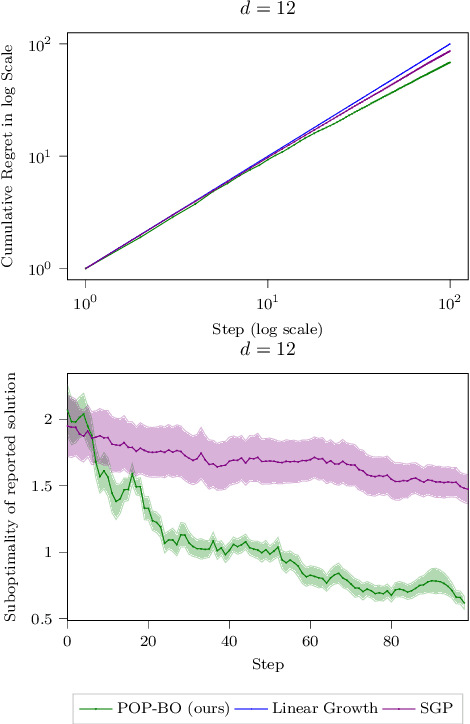
We study the problem of preferential Bayesian optimization (BO), where we aim to optimize a black-box function with only preference feedback over a pair of candidate solutions. Inspired by the likelihood ratio idea, we construct a confidence set of the black-box function using only the preference feedback. An optimistic algorithm with an efficient computational method is then developed to solve the problem, which enjoys an information-theoretic bound on the cumulative regret, a first-of-its-kind for preferential BO. This bound further allows us to design a scheme to report an estimated best solution, with a guaranteed convergence rate. Experimental results on sampled instances from Gaussian processes, standard test functions, and a thermal comfort optimization problem all show that our method stably achieves better or competitive performance as compared to the existing state-of-the-art heuristics, which, however, do not have theoretical guarantees on regret bounds or convergence.
Stable Linear Subspace Identification: A Machine Learning Approach
Nov 20, 2023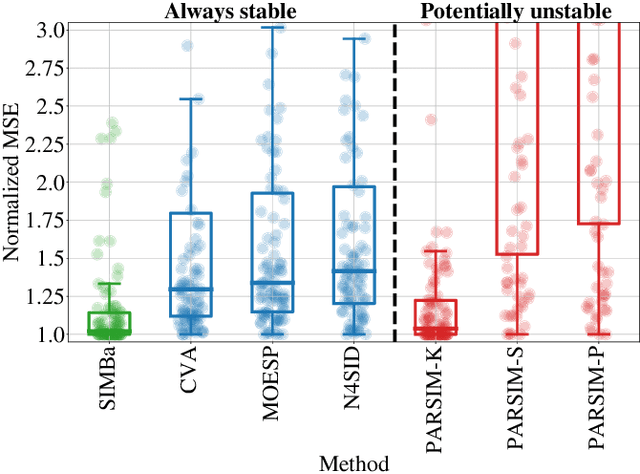
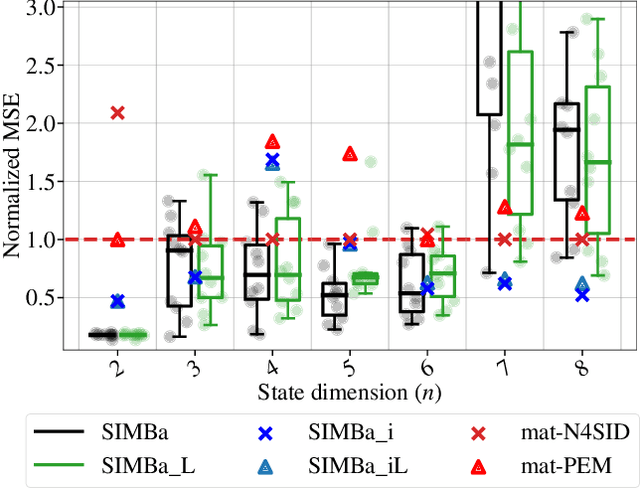
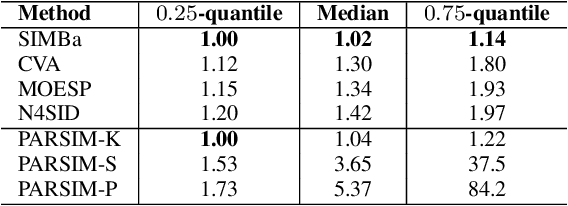
Machine Learning (ML) and linear System Identification (SI) have been historically developed independently. In this paper, we leverage well-established ML tools - especially the automatic differentiation framework - to introduce SIMBa, a family of discrete linear multi-step-ahead state-space SI methods using backpropagation. SIMBa relies on a novel Linear-Matrix-Inequality-based free parametrization of Schur matrices to ensure the stability of the identified model. We show how SIMBa generally outperforms traditional linear state-space SI methods, and sometimes significantly, although at the price of a higher computational burden. This performance gap is particularly remarkable compared to other SI methods with stability guarantees, where the gain is frequently above 25% in our investigations, hinting at SIMBa's ability to simultaneously achieve state-of-the-art fitting performance and enforce stability. Interestingly, these observations hold for a wide variety of input-output systems and on both simulated and real-world data, showcasing the flexibility of the proposed approach. We postulate that this new SI paradigm presents a great extension potential to identify structured nonlinear models from data, and we hence open-source SIMBa on https://github.com/Cemempamoi/simba.
Multi-Agent Bayesian Optimization with Coupled Black-Box and Affine Constraints
Oct 02, 2023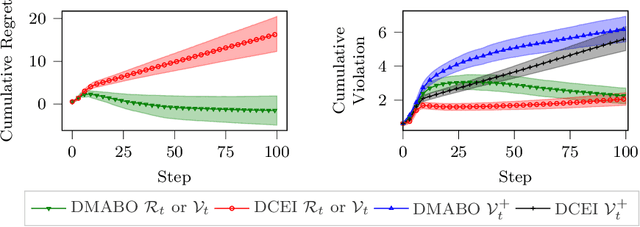
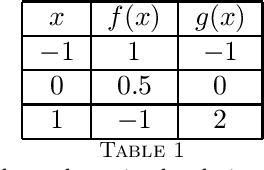
This paper studies the problem of distributed multi-agent Bayesian optimization with both coupled black-box constraints and known affine constraints. A primal-dual distributed algorithm is proposed that achieves similar regret/violation bounds as those in the single-agent case for the black-box objective and constraint functions. Additionally, the algorithm guarantees an $\mathcal{O}(N\sqrt{T})$ bound on the cumulative violation for the known affine constraints, where $N$ is the number of agents. Hence, it is ensured that the average of the samples satisfies the affine constraints up to the error $\mathcal{O}({N}/{\sqrt{T}})$. Furthermore, we characterize certain conditions under which our algorithm can bound a stronger metric of cumulative violation and provide best-iterate convergence without affine constraint. The method is then applied to both sampled instances from Gaussian processes and a real-world optimal power allocation problem for wireless communication; the results show that our method simultaneously provides close-to-optimal performance and maintains minor violations on average, corroborating our theoretical analysis.
Bayesian Optimization of Expensive Nested Grey-Box Functions
Jun 08, 2023



We consider the problem of optimizing a grey-box objective function, i.e., nested function composed of both black-box and white-box functions. A general formulation for such grey-box problems is given, which covers the existing grey-box optimization formulations as special cases. We then design an optimism-driven algorithm to solve it. Under certain regularity assumptions, our algorithm achieves similar regret bound as that for the standard black-box Bayesian optimization algorithm, up to a constant multiplicative term depending on the Lipschitz constants of the functions considered. We further extend our method to the constrained case and discuss several special cases. For the commonly used kernel functions, the regret bounds allow us to derive a convergence rate to the optimal solution. Experimental results show that our grey-box optimization method empirically improves the speed of finding the global optimal solution significantly, as compared to the standard black-box optimization algorithm.
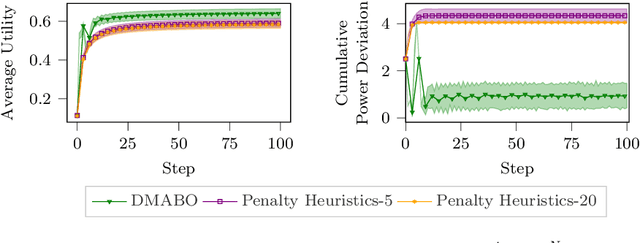
Primal-Dual Contextual Bayesian Optimization for Control System Online Optimization with Time-Average Constraints
Apr 12, 2023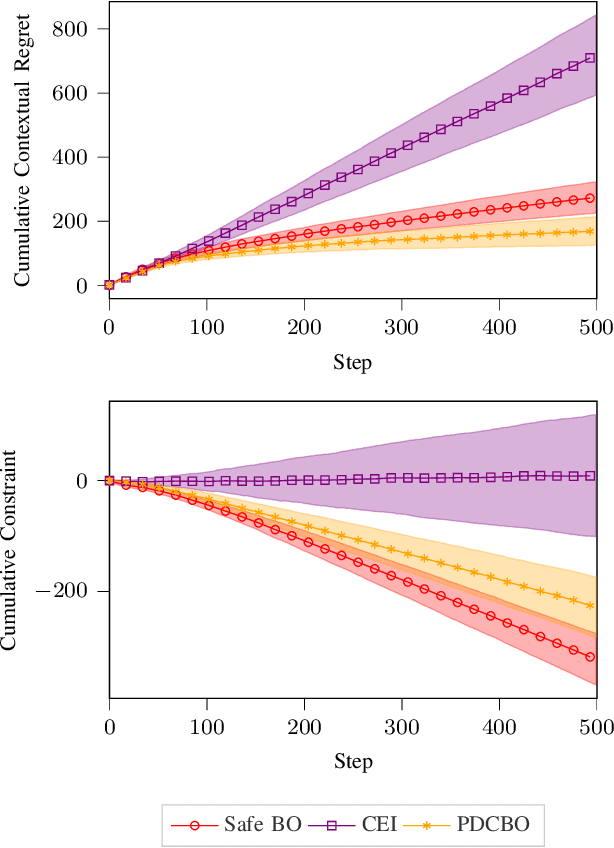
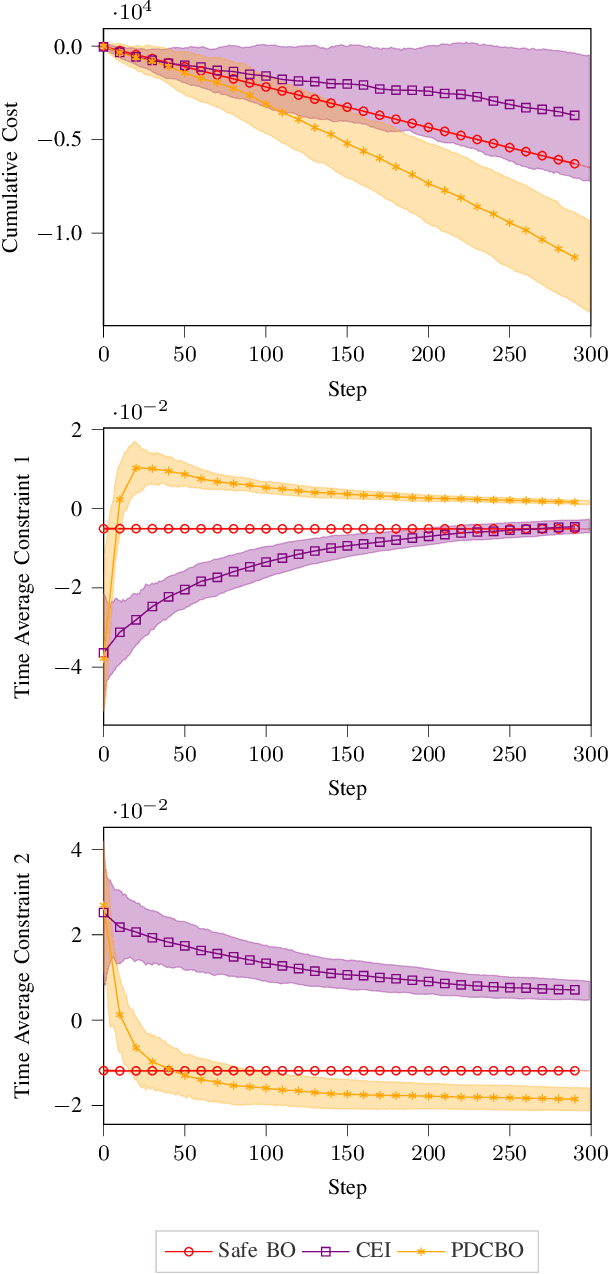
This paper studies the problem of online performance optimization of constrained closed-loop control systems, where both the objective and the constraints are unknown black-box functions affected by exogenous time-varying contextual disturbances. A primal-dual contextual Bayesian optimization algorithm is proposed that achieves sublinear cumulative regret with respect to the dynamic optimal solution under certain regularity conditions. Furthermore, the algorithm achieves zero time-average constraint violation, ensuring that the average value of the constraint function satisfies the desired constraint. The method is applied to both sampled instances from Gaussian processes and a continuous stirred tank reactor parameter tuning problem; simulation results show that the method simultaneously provides close-to-optimal performance and maintains constraint feasibility on average. This contrasts current state-of-the-art methods, which either suffer from large cumulative regret or severe constraint violations for the case studies presented.
Efficient Reinforcement Learning (ERL): Targeted Exploration Through Action Saturation
Nov 30, 2022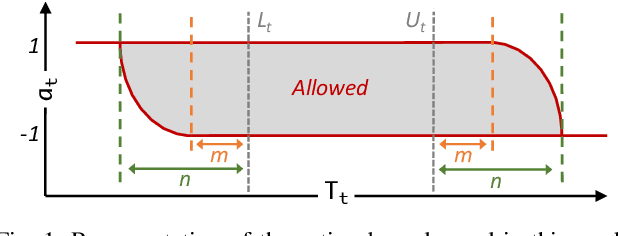



Reinforcement Learning (RL) generally suffers from poor sample complexity, mostly due to the need to exhaustively explore the state space to find good policies. On the other hand, we postulate that expert knowledge of the system to control often allows us to design simple rules we expect good policies to follow at all times. In this work, we hence propose a simple yet effective modification of continuous actor-critic RL frameworks to incorporate such prior knowledge in the learned policies and constrain them to regions of the state space that are deemed interesting, thereby significantly accelerating their convergence. Concretely, we saturate the actions chosen by the agent if they do not comply with our intuition and, critically, modify the gradient update step of the policy to ensure the learning process does not suffer from the saturation step. On a room temperature control simulation case study, these modifications allow agents to converge to well-performing policies up to one order of magnitude faster than classical RL agents while retaining good final performance.
CONFIG: Constrained Efficient Global Optimization for Closed-Loop Control System Optimization with Unmodeled Constraints
Nov 21, 2022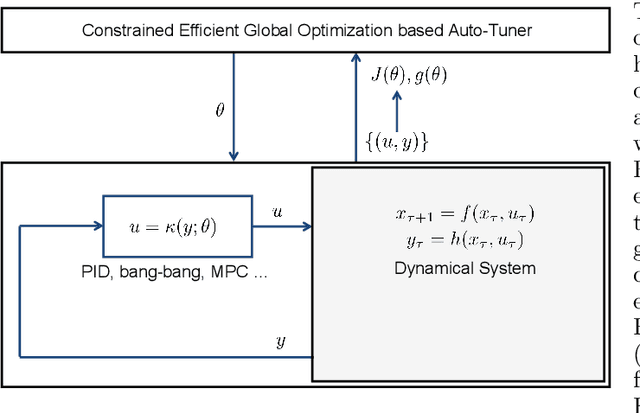
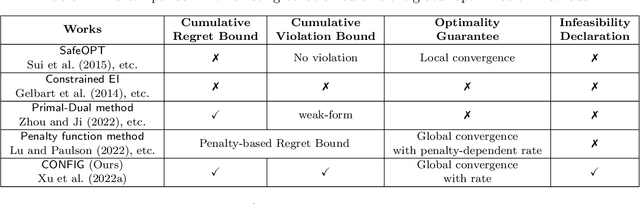
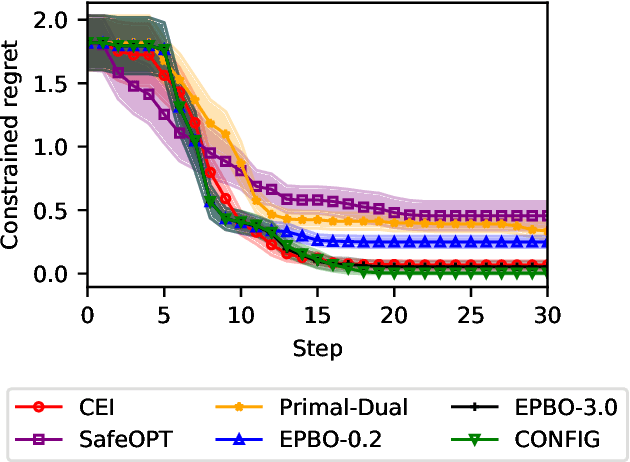
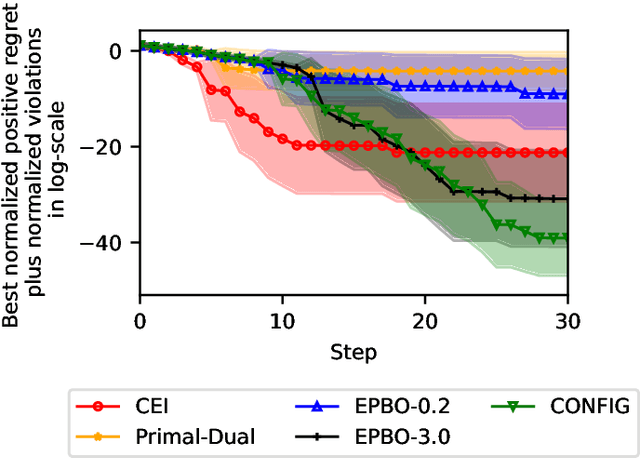
In this paper, the CONFIG algorithm, a simple and provably efficient constrained global optimization algorithm, is applied to optimize the closed-loop control performance of an unknown system with unmodeled constraints. Existing Gaussian process based closed-loop optimization methods, either can only guarantee local convergence (e.g., SafeOPT), or have no known optimality guarantee (e.g., constrained expected improvement) at all, whereas the recently introduced CONFIG algorithm has been proven to enjoy a theoretical global optimality guarantee. In this study, we demonstrate the effectiveness of CONFIG algorithm in the applications. The algorithm is first applied to an artificial numerical benchmark problem to corroborate its effectiveness. It is then applied to a classical constrained steady-state optimization problem of a continuous stirred-tank reactor. Simulation results show that our CONFIG algorithm can achieve performance competitive with the popular CEI (Constrained Expected Improvement) algorithm, which has no known optimality guarantee. As such, the CONFIG algorithm offers a new tool, with both a provable global optimality guarantee and competitive empirical performance, to optimize the closed-loop control performance for a system with soft unmodeled constraints. Last, but not least, the open-source code is available as a python package to facilitate future applications.
Physically Consistent Neural ODEs for Learning Multi-Physics Systems
Nov 11, 2022Despite the immense success of neural networks in modeling system dynamics from data, they often remain physics-agnostic black boxes. In the particular case of physical systems, they might consequently make physically inconsistent predictions, which makes them unreliable in practice. In this paper, we leverage the framework of Irreversible port-Hamiltonian Systems (IPHS), which can describe most multi-physics systems, and rely on Neural Ordinary Differential Equations (NODEs) to learn their parameters from data. Since IPHS models are consistent with the first and second principles of thermodynamics by design, so are the proposed Physically Consistent NODEs (PC-NODEs). Furthermore, the NODE training procedure allows us to seamlessly incorporate prior knowledge of the system properties in the learned dynamics. We demonstrate the effectiveness of the proposed method by learning the thermodynamics of a building from the real-world measurements and the dynamics of a simulated gas-piston system. Thanks to the modularity and flexibility of the IPHS framework, PC-NODEs can be extended to learn physically consistent models of multi-physics distributed systems.