 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranX-Adapter: Bridging Artifacts and Semantics within MLLMs for Robust AI-generated Image Detection
Feb 25, 2026Rapid advances in AI-generated image (AIGI) technology enable highly realistic synthesis, threatening public information integrity and security. Recent studies have demonstrated that incorporating texture-level artifact features alongside semantic features into multimodal large language models (MLLMs) can enhance their AIGI detection capability. However, our preliminary analyses reveal that artifact features exhibit high intra-feature similarity, leading to an almost uniform attention map after the softmax operation. This phenomenon causes attention dilution, thereby hindering effective fusion between semantic and artifact features. To overcome this limitation, we propose a lightweight fusion adapter, TranX-Adapter, which integrates a Task-aware Optimal-Transport Fusion that leverages the Jensen-Shannon divergence between artifact and semantic prediction probabilities as a cost matrix to transfer artifact information into semantic features, and an X-Fusion that employs cross-attention to transfer semantic information into artifact features. Experiments on standard AIGI detection benchmarks upon several advanced MLLMs, show that our TranX-Adapter brings consistent and significant improvements (up to +6% accuracy).
Retrieval-Augmented Perception: High-Resolution Image Perception Meets Visual RAG
Mar 03, 2025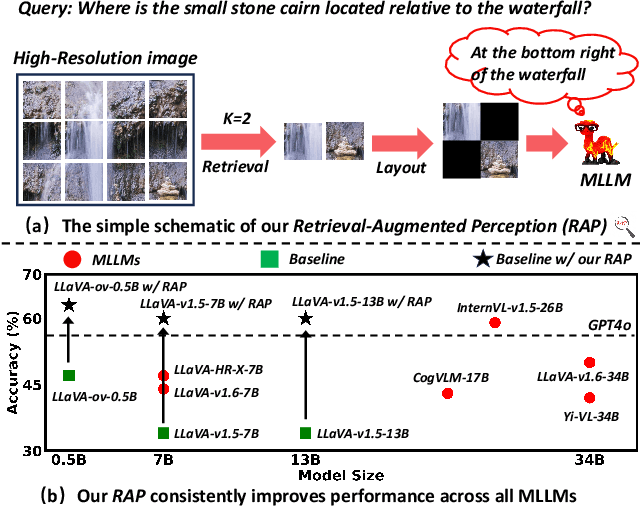
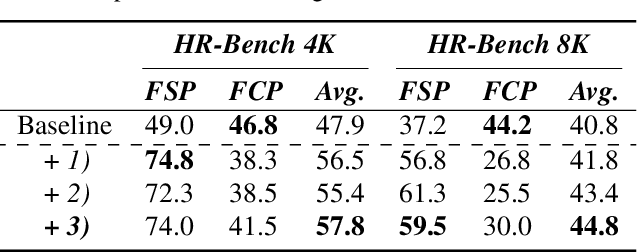
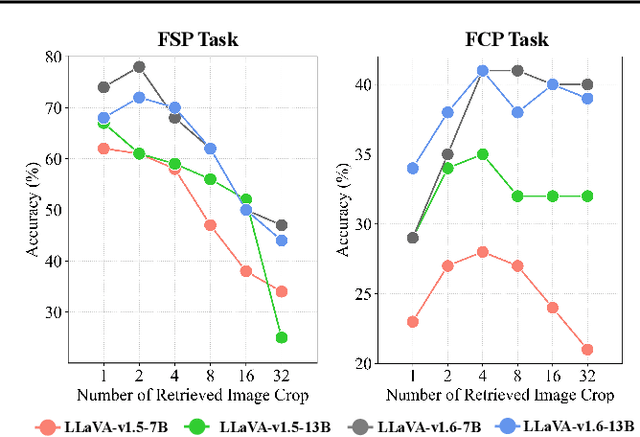
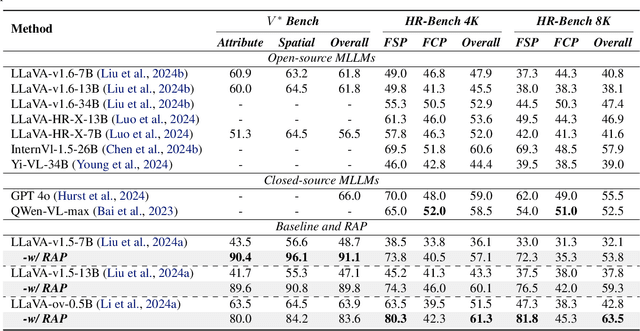
High-resolution (HR) image perception remains a key challenge in multimodal large language models (MLLMs). To overcome the limitations of existing methods, this paper shifts away from prior dedicated heuristic approaches and revisits the most fundamental idea to HR perception by enhancing the long-context capability of MLLMs, driven by recent advances in long-context techniques like retrieval-augmented generation (RAG) for general LLMs. Towards this end, this paper presents the first study exploring the use of RAG to address HR perception challenges. Specifically, we propose Retrieval-Augmented Perception (RAP), a training-free framework that retrieves and fuses relevant image crops while preserving spatial context using the proposed Spatial-Awareness Layout. To accommodate different tasks, the proposed Retrieved-Exploration Search (RE-Search) dynamically selects the optimal number of crops based on model confidence and retrieval scores. Experimental results on HR benchmarks demonstrate the significant effectiveness of RAP, with LLaVA-v1.5-13B achieving a 43% improvement on $V^*$ Bench and 19% on HR-Bench.
Poisoning Attacks and Defenses to Federated Unlearning
Jan 29, 2025


Federated learning allows multiple clients to collaboratively train a global model with the assistance of a server. However, its distributed nature makes it susceptible to poisoning attacks, where malicious clients can compromise the global model by sending harmful local model updates to the server. To unlearn an accurate global model from a poisoned one after identifying malicious clients, federated unlearning has been introduced. Yet, current research on federated unlearning has primarily concentrated on its effectiveness and efficiency, overlooking the security challenges it presents. In this work, we bridge the gap via proposing BadUnlearn, the first poisoning attacks targeting federated unlearning. In BadUnlearn, malicious clients send specifically designed local model updates to the server during the unlearning process, aiming to ensure that the resulting unlearned model remains poisoned. To mitigate these threats, we propose UnlearnGuard, a robust federated unlearning framework that is provably robust against both existing poisoning attacks and our BadUnlearn. The core concept of UnlearnGuard is for the server to estimate the clients' local model updates during the unlearning process and employ a filtering strategy to verify the accuracy of these estimations. Theoretically, we prove that the model unlearned through UnlearnGuard closely resembles one obtained by train-from-scratch. Empirically, we show that BadUnlearn can effectively corrupt existing federated unlearning methods, while UnlearnGuard remains secure against poisoning attacks.
DynamicKV: Task-Aware Adaptive KV Cache Compression for Long Context LLMs
Dec 19, 2024



Efficient KV cache management in LLMs is crucial for long-context tasks like RAG and summarization. Existing KV cache compression methods enforce a fixed pattern, neglecting task-specific characteristics and reducing the retention of essential information. However, we observe distinct activation patterns across layers in various tasks, highlighting the need for adaptive strategies tailored to each task's unique demands. Based on this insight, we propose DynamicKV, a method that dynamically optimizes token retention by adjusting the number of tokens retained at each layer to adapt to the specific task. DynamicKV establishes global and per-layer maximum KV cache budgets, temporarily retaining the maximum budget for the current layer, and periodically updating the KV cache sizes of all preceding layers during inference. Our method retains only 1.7% of the KV cache size while achieving ~85% of the Full KV cache performance on LongBench. Notably, even under extreme compression (0.9%), DynamicKV surpasses state-of-the-art (SOTA) methods by 11% in the Needle-in-a-Haystack test using Mistral-7B-Instruct-v0.2. The code will be released.
Towards Robust Multimodal Sentiment Analysis with Incomplete Data
Sep 30, 2024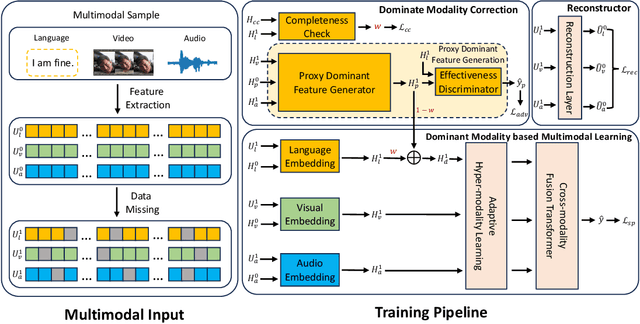
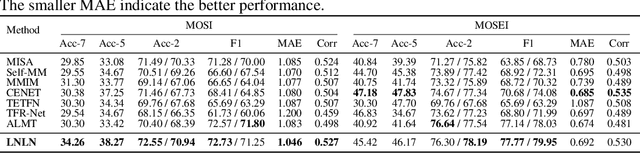
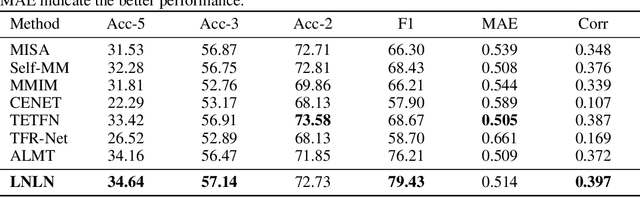
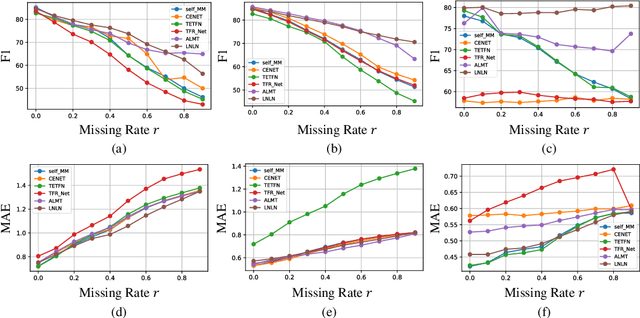
The field of Multimodal Sentiment Analysis (MSA) has recently witnessed an emerging direction seeking to tackle the issue of data incompleteness. Recognizing that the language modality typically contains dense sentiment information, we consider it as the dominant modality and present an innovative Language-dominated Noise-resistant Learning Network (LNLN) to achieve robust MSA. The proposed LNLN features a dominant modality correction (DMC) module and dominant modality based multimodal learning (DMML) module, which enhances the model's robustness across various noise scenarios by ensuring the quality of dominant modality representations. Aside from the methodical design, we perform comprehensive experiments under random data missing scenarios, utilizing diverse and meaningful settings on several popular datasets (\textit{e.g.,} MOSI, MOSEI, and SIMS), providing additional uniformity, transparency, and fairness compared to existing evaluations in the literature. Empirically, LNLN consistently outperforms existing baselines, demonstrating superior performance across these challenging and extensive evaluation metrics.
Divide, Conquer and Combine: A Training-Free Framework for High-Resolution Image Perception in Multimodal Large Language Models
Aug 28, 2024



Multimodal large language models (MLLMs) have experienced significant advancements recently, but still struggle to recognize and interpret intricate details in high-resolution (HR) images effectively. While state-of-the-art (SOTA) MLLMs claim to process images at 4K resolution, existing MLLM benchmarks only support up to 2K, leaving the capabilities of SOTA models on true HR images largely untested. Furthermore, existing methods for enhancing HR image perception in MLLMs rely on computationally expensive visual instruction tuning. To address these limitations, we introduce HR-Bench, the first deliberately designed benchmark to rigorously evaluate MLLM performance on 4K&8K images. Through extensive experiments, we demonstrate that while downsampling HR images leads to vision information loss, leveraging complementary modalities, e.g., text, can effectively compensate for this loss. Building upon this insight, we propose Divide, Conquer and Combine (DC$^2$), a novel training-free framework for enhancing MLLM perception of HR images. DC$^2$ follows a three-staged approach: 1) Divide: recursively partitioning the HR image into patches and merging similar patches to minimize computational overhead, 2) Conquer: leveraging the MLLM to generate accurate textual descriptions for each image patch, and 3) Combine: utilizing the generated text descriptions to enhance the MLLM's understanding of the overall HR image. Extensive experiments show that: 1) the SOTA MLLM achieves 63% accuracy, which is markedly lower than the 87% accuracy achieved by humans on HR-Bench; 2) our DC$^2$ brings consistent and significant improvements (a relative increase of +6% on HR-Bench and +8% on general multimodal benchmarks). The benchmark and code will be released to facilitate the multimodal R&D community.
Fine-Grained Scene Graph Generation via Sample-Level Bias Prediction
Jul 27, 2024



Scene Graph Generation (SGG) aims to explore the relationships between objects in images and obtain scene summary graphs, thereby better serving downstream tasks. However, the long-tailed problem has adversely affected the scene graph's quality. The predictions are dominated by coarse-grained relationships, lacking more informative fine-grained ones. The union region of one object pair (i.e., one sample) contains rich and dedicated contextual information, enabling the prediction of the sample-specific bias for refining the original relationship prediction. Therefore, we propose a novel Sample-Level Bias Prediction (SBP) method for fine-grained SGG (SBG). Firstly, we train a classic SGG model and construct a correction bias set by calculating the margin between the ground truth label and the predicted label with one classic SGG model. Then, we devise a Bias-Oriented Generative Adversarial Network (BGAN) that learns to predict the constructed correction biases, which can be utilized to correct the original predictions from coarse-grained relationships to fine-grained ones. The extensive experimental results on VG, GQA, and VG-1800 datasets demonstrate that our SBG outperforms the state-of-the-art methods in terms of Average@K across three mainstream SGG models: Motif, VCtree, and Transformer. Compared to dataset-level correction methods on VG, SBG shows a significant average improvement of 5.6%, 3.9%, and 3.2% on Average@K for tasks PredCls, SGCls, and SGDet, respectively. The code will be available at https://github.com/Zhuzi24/SBG.
GLOBE: A High-quality English Corpus with Global Accents for Zero-shot Speaker Adaptive Text-to-Speech
Jun 21, 2024



This paper introduces GLOBE, a high-quality English corpus with worldwide accents, specifically designed to address the limitations of current zero-shot speaker adaptive Text-to-Speech (TTS) systems that exhibit poor generalizability in adapting to speakers with accents. Compared to commonly used English corpora, such as LibriTTS and VCTK, GLOBE is unique in its inclusion of utterances from 23,519 speakers and covers 164 accents worldwide, along with detailed metadata for these speakers. Compared to its original corpus, i.e., Common Voice, GLOBE significantly improves the quality of the speech data through rigorous filtering and enhancement processes, while also populating all missing speaker metadata. The final curated GLOBE corpus includes 535 hours of speech data at a 24 kHz sampling rate. Our benchmark results indicate that the speaker adaptive TTS model trained on the GLOBE corpus can synthesize speech with better speaker similarity and comparable naturalness than that trained on other popular corpora. We will release GLOBE publicly after acceptance. The GLOBE dataset is available at https://globecorpus.github.io/.
Scene Graph Generation in Large-Size VHR Satellite Imagery: A Large-Scale Dataset and A Context-Aware Approach
Jun 13, 2024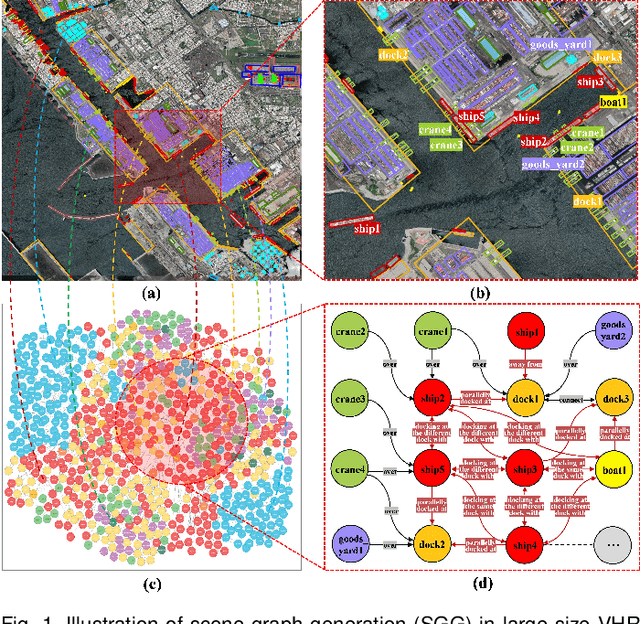
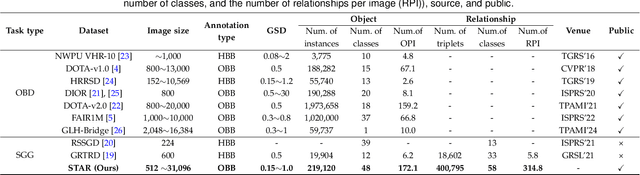
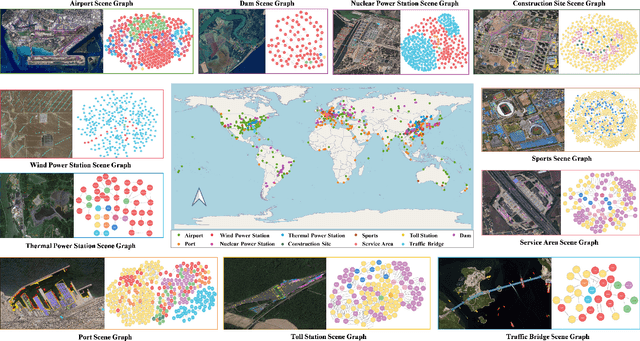
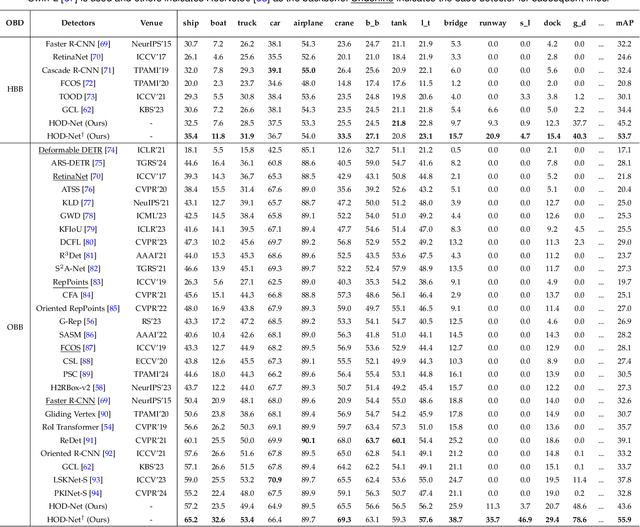
Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting intelligent understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it necessary to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, the lack of SGG datasets with large-size VHR SAI has constrained the advancement of SGG in SAI. Due to the complexity of large-size VHR SAI, mining triplets <subject, relationship, object> in large-size VHR SAI heavily relies on long-range contextual reasoning. Consequently, SGG models designed for small-size natural imagery are not directly applicable to large-size VHR SAI. To address the scarcity of datasets, this paper constructs a large-scale dataset for SGG in large-size VHR SAI with image sizes ranging from 512 x 768 to 27,860 x 31,096 pixels, named RSG, encompassing over 210,000 objects and more than 400,000 triplets. To realize SGG in large-size VHR SAI, we propose a context-aware cascade cognition (CAC) framework to understand SAI at three levels: object detection (OBD), pair pruning and relationship prediction. As a fundamental prerequisite for SGG in large-size SAI, a holistic multi-class object detection network (HOD-Net) that can flexibly integrate multi-scale contexts is proposed. With the consideration that there exist a huge amount of object pairs in large-size SAI but only a minority of object pairs contain meaningful relationships, we design a pair proposal generation (PPG) network via adversarial reconstruction to select high-value pairs. Furthermore, a relationship prediction network with context-aware messaging (RPCM) is proposed to predict the relationship types of these pairs.
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Apr 28, 2024


Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as "instant" and "fine-grained" adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
* 15 pages, 13 figures. Copyright has been transferred to IEEE