 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Multimodal Sentiment Analysis with Incomplete Data
Paper and Code
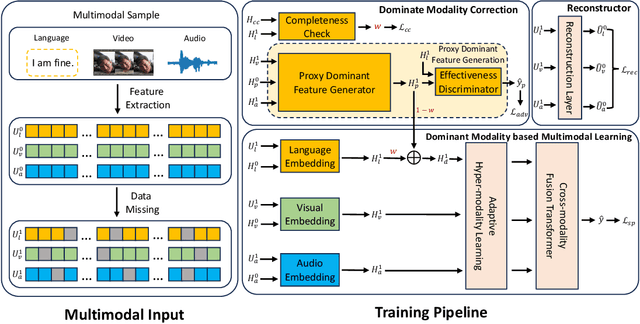
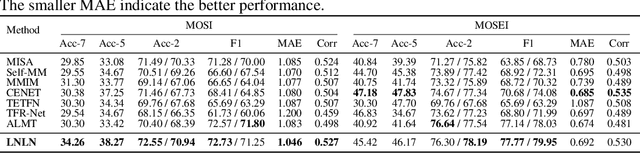
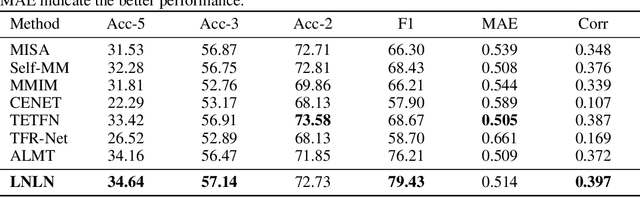
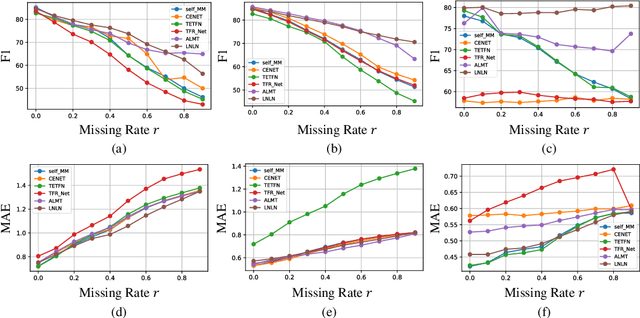
The field of Multimodal Sentiment Analysis (MSA) has recently witnessed an emerging direction seeking to tackle the issue of data incompleteness. Recognizing that the language modality typically contains dense sentiment information, we consider it as the dominant modality and present an innovative Language-dominated Noise-resistant Learning Network (LNLN) to achieve robust MSA. The proposed LNLN features a dominant modality correction (DMC) module and dominant modality based multimodal learning (DMML) module, which enhances the model's robustness across various noise scenarios by ensuring the quality of dominant modality representations. Aside from the methodical design, we perform comprehensive experiments under random data missing scenarios, utilizing diverse and meaningful settings on several popular datasets (\textit{e.g.,} MOSI, MOSEI, and SIMS), providing additional uniformity, transparency, and fairness compared to existing evaluations in the literature. Empirically, LNLN consistently outperforms existing baselines, demonstrating superior performance across these challenging and extensive evaluation metrics.