 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRW: Efficient Privacy-Preserving Data Reweighting for Enhancing Federated Learning of Language Models
Nov 10, 2025Data duplication within large-scale corpora often impedes large language models' (LLMs) performance and privacy. In privacy-concerned federated learning scenarios, conventional deduplication methods typically rely on trusted third parties to perform uniform deletion, risking loss of informative samples while introducing privacy vulnerabilities. To address these gaps, we propose Federated ReWeighting (FedRW), the first privacy-preserving framework, to the best of our knowledge, that performs soft deduplication via sample reweighting instead of deletion in federated LLM training, without assuming a trusted third party. At its core, FedRW proposes a secure, frequency-aware reweighting protocol through secure multi-party computation, coupled with a parallel orchestration strategy to ensure efficiency and scalability. During training, FedRW utilizes an adaptive reweighting mechanism with global sample frequencies to adjust individual loss contributions, effectively improving generalization and robustness. Empirical results demonstrate that FedRW outperforms the state-of-the-art method by achieving up to 28.78x speedup in preprocessing and approximately 11.42% improvement in perplexity, while offering enhanced security guarantees. FedRW thus establishes a new paradigm for managing duplication in federated LLM training.
Partial Weakly-Supervised Oriented Object Detection
Jul 03, 2025
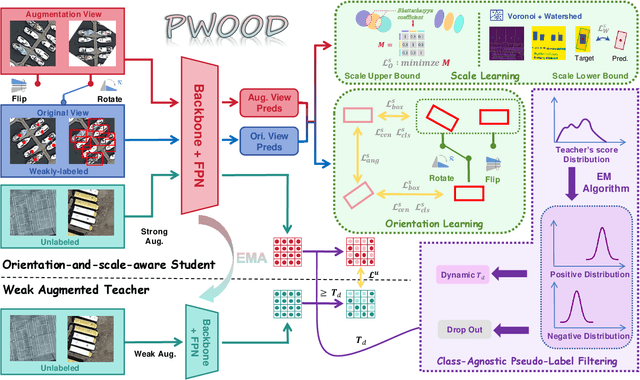


The growing demand for oriented object detection (OOD) across various domains has driven significant research in this area. However, the high cost of dataset annotation remains a major concern. Current mainstream OOD algorithms can be mainly categorized into three types: (1) fully supervised methods using complete oriented bounding box (OBB) annotations, (2) semi-supervised methods using partial OBB annotations, and (3) weakly supervised methods using weak annotations such as horizontal boxes or points. However, these algorithms inevitably increase the cost of models in terms of annotation speed or annotation cost. To address this issue, we propose:(1) the first Partial Weakly-Supervised Oriented Object Detection (PWOOD) framework based on partially weak annotations (horizontal boxes or single points), which can efficiently leverage large amounts of unlabeled data, significantly outperforming weakly supervised algorithms trained with partially weak annotations, also offers a lower cost solution; (2) Orientation-and-Scale-aware Student (OS-Student) model capable of learning orientation and scale information with only a small amount of orientation-agnostic or scale-agnostic weak annotations; and (3) Class-Agnostic Pseudo-Label Filtering strategy (CPF) to reduce the model's sensitivity to static filtering thresholds. Comprehensive experiments on DOTA-v1.0/v1.5/v2.0 and DIOR datasets demonstrate that our PWOOD framework performs comparably to, or even surpasses, traditional semi-supervised algorithms.
When Large Vision-Language Model Meets Large Remote Sensing Imagery: Coarse-to-Fine Text-Guided Token Pruning
Mar 10, 2025Efficient vision-language understanding of large Remote Sensing Images (RSIs) is meaningful but challenging. Current Large Vision-Language Models (LVLMs) typically employ limited pre-defined grids to process images, leading to information loss when handling gigapixel RSIs. Conversely, using unlimited grids significantly increases computational costs. To preserve image details while reducing computational complexity, we propose a text-guided token pruning method with Dynamic Image Pyramid (DIP) integration. Our method introduces: (i) a Region Focus Module (RFM) that leverages text-aware region localization capability to identify critical vision tokens, and (ii) a coarse-to-fine image tile selection and vision token pruning strategy based on DIP, which is guided by RFM outputs and avoids directly processing the entire large imagery. Additionally, existing benchmarks for evaluating LVLMs' perception ability on large RSI suffer from limited question diversity and constrained image sizes. We construct a new benchmark named LRS-VQA, which contains 7,333 QA pairs across 8 categories, with image length up to 27,328 pixels. Our method outperforms existing high-resolution strategies on four datasets using the same data. Moreover, compared to existing token reduction methods, our approach demonstrates higher efficiency under high-resolution settings. Dataset and code are in https://github.com/VisionXLab/LRS-VQA.
Point2RBox-v2: Rethinking Point-supervised Oriented Object Detection with Spatial Layout Among Instances
Feb 07, 2025



With the rapidly increasing demand for oriented object detection (OOD), recent research involving weakly-supervised detectors for learning OOD from point annotations has gained great attention. In this paper, we rethink this challenging task setting with the layout among instances and present Point2RBox-v2. At the core are three principles: 1) Gaussian overlap loss. It learns an upper bound for each instance by treating objects as 2D Gaussian distributions and minimizing their overlap. 2) Voronoi watershed loss. It learns a lower bound for each instance through watershed on Voronoi tessellation. 3) Consistency loss. It learns the size/rotation variation between two output sets with respect to an input image and its augmented view. Supplemented by a few devised techniques, e.g. edge loss and copy-paste, the detector is further enhanced. To our best knowledge, Point2RBox-v2 is the first approach to explore the spatial layout among instances for learning point-supervised OOD. Our solution is elegant and lightweight, yet it is expected to give a competitive performance especially in densely packed scenes: 62.61%/86.15%/34.71% on DOTA/HRSC/FAIR1M. Code is available at https://github.com/VisionXLab/point2rbox-v2.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
PointOBB-v2: Towards Simpler, Faster, and Stronger Single Point Supervised Oriented Object Detection
Oct 10, 2024



Single point supervised oriented object detection has gained attention and made initial progress within the community. Diverse from those approaches relying on one-shot samples or powerful pretrained models (e.g. SAM), PointOBB has shown promise due to its prior-free feature. In this paper, we propose PointOBB-v2, a simpler, faster, and stronger method to generate pseudo rotated boxes from points without relying on any other prior. Specifically, we first generate a Class Probability Map (CPM) by training the network with non-uniform positive and negative sampling. We show that the CPM is able to learn the approximate object regions and their contours. Then, Principal Component Analysis (PCA) is applied to accurately estimate the orientation and the boundary of objects. By further incorporating a separation mechanism, we resolve the confusion caused by the overlapping on the CPM, enabling its operation in high-density scenarios. Extensive comparisons demonstrate that our method achieves a training speed 15.58x faster and an accuracy improvement of 11.60%/25.15%/21.19% on the DOTA-v1.0/v1.5/v2.0 datasets compared to the previous state-of-the-art, PointOBB. This significantly advances the cutting edge of single point supervised oriented detection in the modular track.
SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding
Jun 14, 2024Remote Sensing Large Multi-Modal Models (RSLMMs) are developing rapidly and showcase significant capabilities in remote sensing imagery (RSI) comprehension. However, due to the limitations of existing datasets, RSLMMs have shortcomings in understanding the rich semantic relations among objects in complex remote sensing scenes. To unlock RSLMMs' complex comprehension ability, we propose a large-scale instruction tuning dataset FIT-RS, containing 1,800,851 instruction samples. FIT-RS covers common interpretation tasks and innovatively introduces several complex comprehension tasks of escalating difficulty, ranging from relation reasoning to image-level scene graph generation. Based on FIT-RS, we build the FIT-RSFG benchmark. Furthermore, we establish a new benchmark to evaluate the fine-grained relation comprehension capabilities of LMMs, named FIT-RSRC. Based on combined instruction data, we propose SkySenseGPT, which achieves outstanding performance on both public datasets and FIT-RSFG, surpassing existing RSLMMs. We hope the FIT-RS dataset can enhance the relation comprehension capability of RSLMMs and provide a large-scale fine-grained data source for the remote sensing community. The dataset will be available at https://github.com/Luo-Z13/SkySenseGPT
Scene Graph Generation in Large-Size VHR Satellite Imagery: A Large-Scale Dataset and A Context-Aware Approach
Jun 13, 2024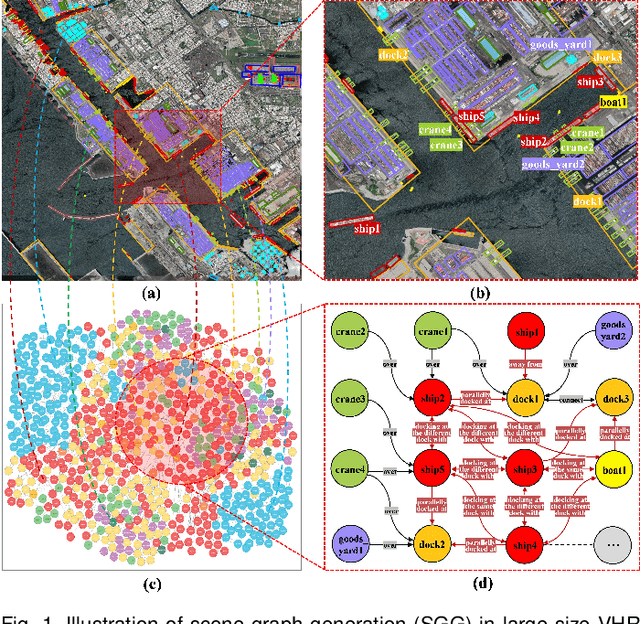
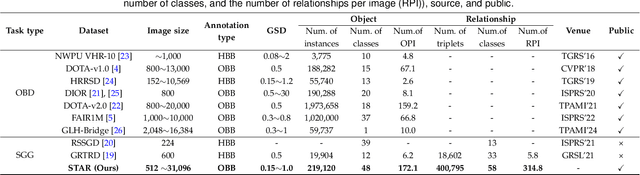
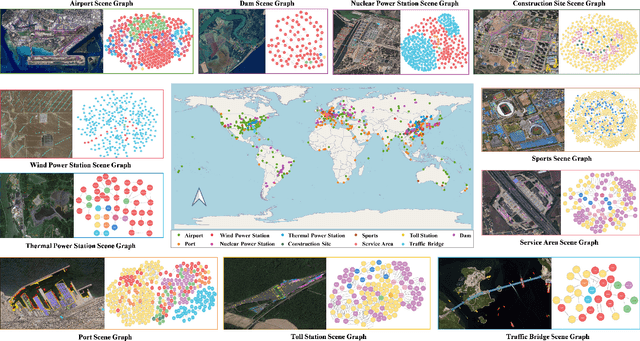
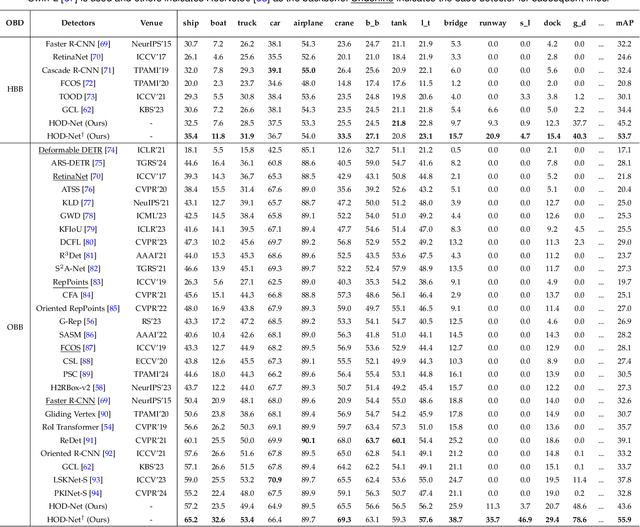
Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting intelligent understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it necessary to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, the lack of SGG datasets with large-size VHR SAI has constrained the advancement of SGG in SAI. Due to the complexity of large-size VHR SAI, mining triplets <subject, relationship, object> in large-size VHR SAI heavily relies on long-range contextual reasoning. Consequently, SGG models designed for small-size natural imagery are not directly applicable to large-size VHR SAI. To address the scarcity of datasets, this paper constructs a large-scale dataset for SGG in large-size VHR SAI with image sizes ranging from 512 x 768 to 27,860 x 31,096 pixels, named RSG, encompassing over 210,000 objects and more than 400,000 triplets. To realize SGG in large-size VHR SAI, we propose a context-aware cascade cognition (CAC) framework to understand SAI at three levels: object detection (OBD), pair pruning and relationship prediction. As a fundamental prerequisite for SGG in large-size SAI, a holistic multi-class object detection network (HOD-Net) that can flexibly integrate multi-scale contexts is proposed. With the consideration that there exist a huge amount of object pairs in large-size SAI but only a minority of object pairs contain meaningful relationships, we design a pair proposal generation (PPG) network via adversarial reconstruction to select high-value pairs. Furthermore, a relationship prediction network with context-aware messaging (RPCM) is proposed to predict the relationship types of these pairs.
Learning to Holistically Detect Bridges from Large-Size VHR Remote Sensing Imagery
Dec 05, 2023



Bridge detection in remote sensing images (RSIs) plays a crucial role in various applications, but it poses unique challenges compared to the detection of other objects. In RSIs, bridges exhibit considerable variations in terms of their spatial scales and aspect ratios. Therefore, to ensure the visibility and integrity of bridges, it is essential to perform holistic bridge detection in large-size very-high-resolution (VHR) RSIs. However, the lack of datasets with large-size VHR RSIs limits the deep learning algorithms' performance on bridge detection. Due to the limitation of GPU memory in tackling large-size images, deep learning-based object detection methods commonly adopt the cropping strategy, which inevitably results in label fragmentation and discontinuous prediction. To ameliorate the scarcity of datasets, this paper proposes a large-scale dataset named GLH-Bridge comprising 6,000 VHR RSIs sampled from diverse geographic locations across the globe. These images encompass a wide range of sizes, varying from 2,048*2,048 to 16,38*16,384 pixels, and collectively feature 59,737 bridges. Furthermore, we present an efficient network for holistic bridge detection (HBD-Net) in large-size RSIs. The HBD-Net presents a separate detector-based feature fusion (SDFF) architecture and is optimized via a shape-sensitive sample re-weighting (SSRW) strategy. Based on the proposed GLH-Bridge dataset, we establish a bridge detection benchmark including the OBB and HBB tasks, and validate the effectiveness of the proposed HBD-Net. Additionally, cross-dataset generalization experiments on two publicly available datasets illustrate the strong generalization capability of the GLH-Bridge dataset.
PointOBB: Learning Oriented Object Detection via Single Point Supervision
Nov 23, 2023
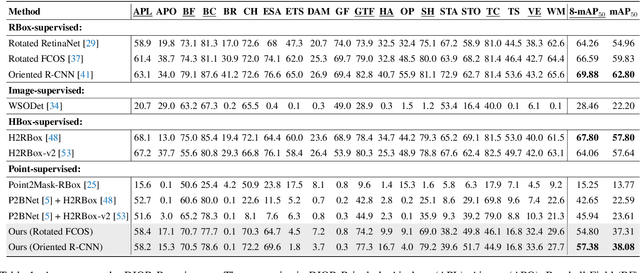
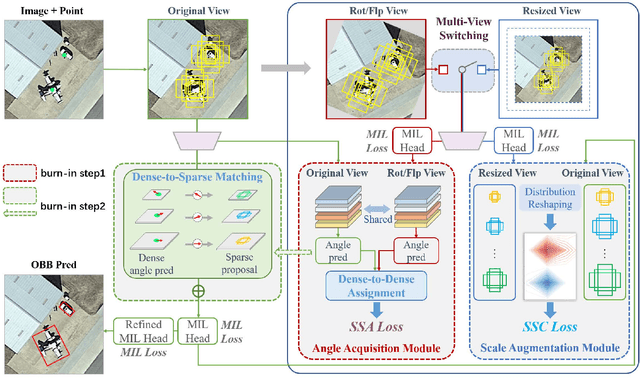
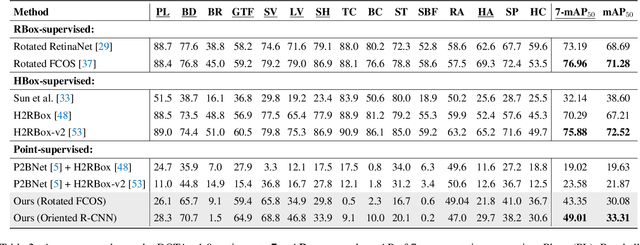
Single point-supervised object detection is gaining attention due to its cost-effectiveness. However, existing approaches focus on generating horizontal bounding boxes (HBBs) while ignoring oriented bounding boxes (OBBs) commonly used for objects in aerial images. This paper proposes PointOBB, the first single Point-based OBB generation method, for oriented object detection. PointOBB operates through the collaborative utilization of three distinctive views: an original view, a resized view, and a rotated/flipped (rot/flp) view. Upon the original view, we leverage the resized and rot/flp views to build a scale augmentation module and an angle acquisition module, respectively. In the former module, a Scale-Sensitive Consistency (SSC) loss is designed to enhance the deep network's ability to perceive the object scale. For accurate object angle predictions, the latter module incorporates self-supervised learning to predict angles, which is associated with a scale-guided Dense-to-Sparse (DS) matching strategy for aggregating dense angles corresponding to sparse objects. The resized and rot/flp views are switched using a progressive multi-view switching strategy during training to achieve coupled optimization of scale and angle. Experimental results on the DIOR-R and DOTA-v1.0 datasets demonstrate that PointOBB achieves promising performance, and significantly outperforms potential point-supervised baselines.