 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
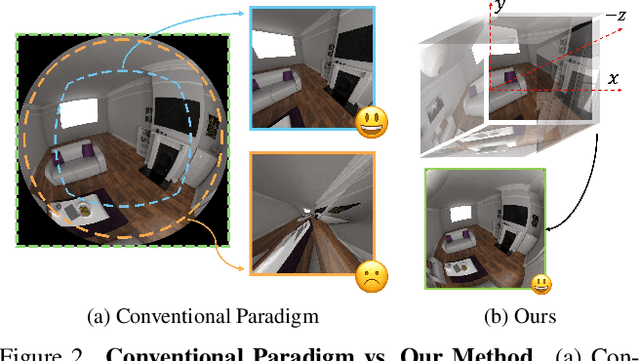
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
Self-Calibrating Gaussian Splatting for Large Field of View Reconstruction
Feb 13, 2025
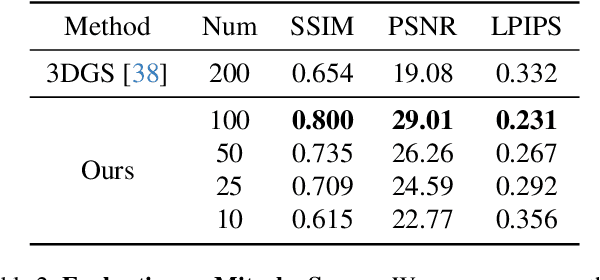
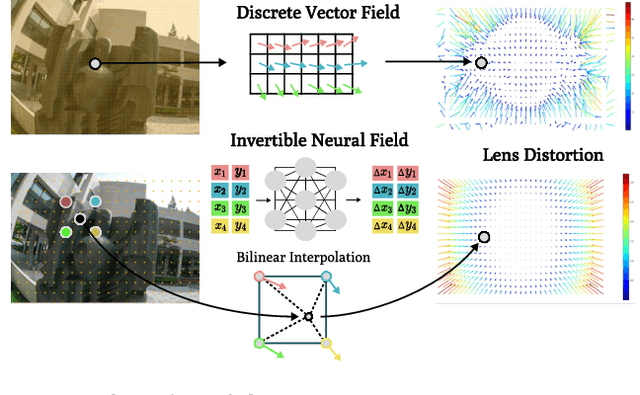
In this paper, we present a self-calibrating framework that jointly optimizes camera parameters, lens distortion and 3D Gaussian representations, enabling accurate and efficient scene reconstruction. In particular, our technique enables high-quality scene reconstruction from Large field-of-view (FOV) imagery taken with wide-angle lenses, allowing the scene to be modeled from a smaller number of images. Our approach introduces a novel method for modeling complex lens distortions using a hybrid network that combines invertible residual networks with explicit grids. This design effectively regularizes the optimization process, achieving greater accuracy than conventional camera models. Additionally, we propose a cubemap-based resampling strategy to support large FOV images without sacrificing resolution or introducing distortion artifacts. Our method is compatible with the fast rasterization of Gaussian Splatting, adaptable to a wide variety of camera lens distortion, and demonstrates state-of-the-art performance on both synthetic and real-world datasets.
Scene Graph Generation in Large-Size VHR Satellite Imagery: A Large-Scale Dataset and A Context-Aware Approach
Jun 13, 2024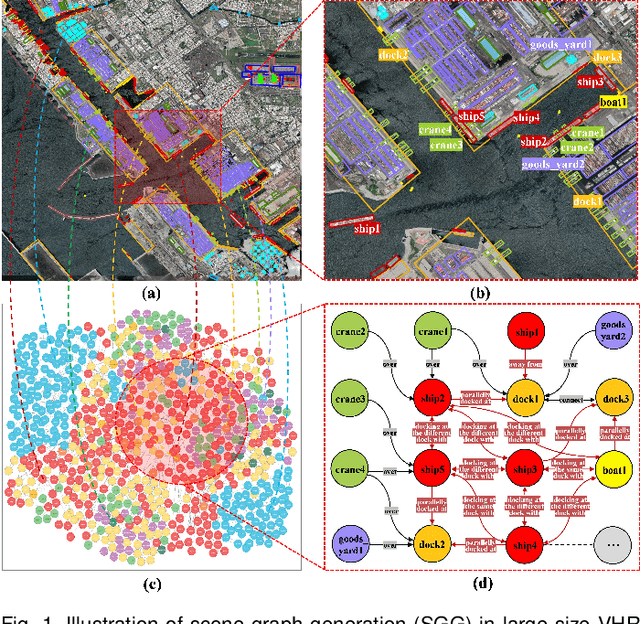
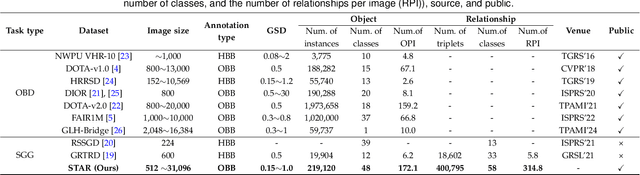
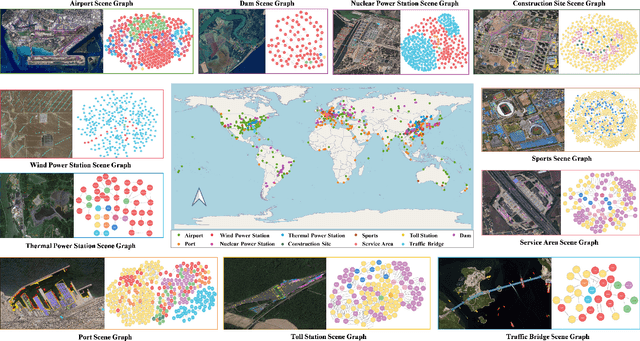
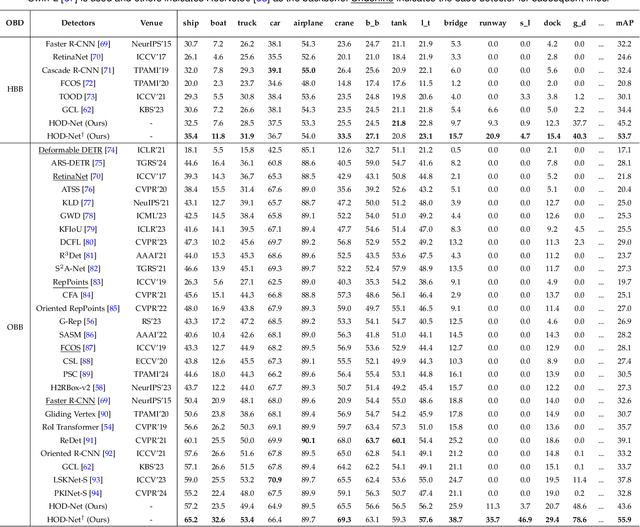
Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting intelligent understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it necessary to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, the lack of SGG datasets with large-size VHR SAI has constrained the advancement of SGG in SAI. Due to the complexity of large-size VHR SAI, mining triplets <subject, relationship, object> in large-size VHR SAI heavily relies on long-range contextual reasoning. Consequently, SGG models designed for small-size natural imagery are not directly applicable to large-size VHR SAI. To address the scarcity of datasets, this paper constructs a large-scale dataset for SGG in large-size VHR SAI with image sizes ranging from 512 x 768 to 27,860 x 31,096 pixels, named RSG, encompassing over 210,000 objects and more than 400,000 triplets. To realize SGG in large-size VHR SAI, we propose a context-aware cascade cognition (CAC) framework to understand SAI at three levels: object detection (OBD), pair pruning and relationship prediction. As a fundamental prerequisite for SGG in large-size SAI, a holistic multi-class object detection network (HOD-Net) that can flexibly integrate multi-scale contexts is proposed. With the consideration that there exist a huge amount of object pairs in large-size SAI but only a minority of object pairs contain meaningful relationships, we design a pair proposal generation (PPG) network via adversarial reconstruction to select high-value pairs. Furthermore, a relationship prediction network with context-aware messaging (RPCM) is proposed to predict the relationship types of these pairs.
DIP: Differentiable Interreflection-aware Physics-based Inverse Rendering
Dec 09, 2022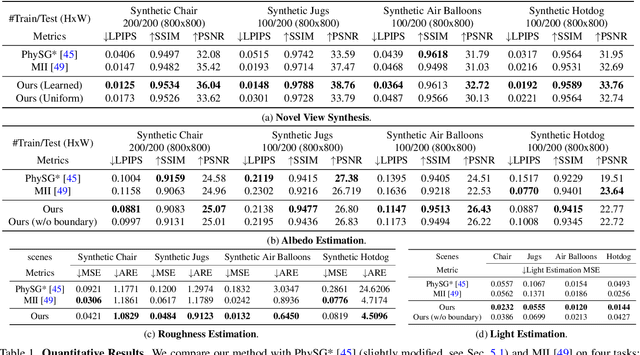
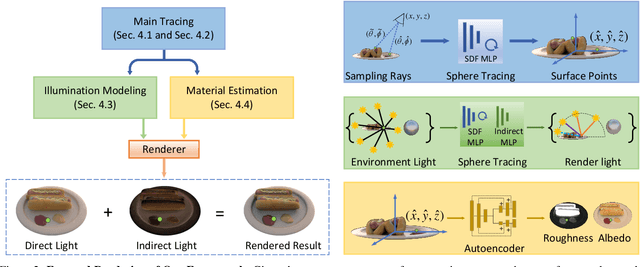
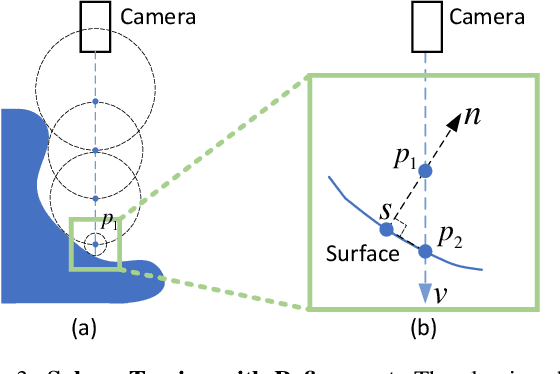
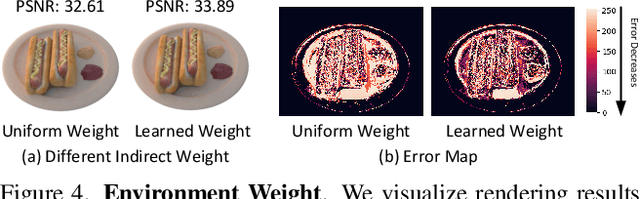
We present a physics-based inverse rendering method that learns the illumination, geometry, and materials of a scene from posed multi-view RGB images. To model the illumination of a scene, existing inverse rendering works either completely ignore the indirect illumination or model it by coarse approximations, leading to sub-optimal illumination, geometry, and material prediction of the scene. In this work, we propose a physics-based illumination model that explicitly traces the incoming indirect lights at each surface point based on interreflection, followed by estimating each identified indirect light through an efficient neural network. Furthermore, we utilize the Leibniz's integral rule to resolve non-differentiability in the proposed illumination model caused by one type of environment light -- the tangent lights. As a result, the proposed interreflection-aware illumination model can be learned end-to-end together with geometry and materials estimation. As a side product, our physics-based inverse rendering model also facilitates flexible and realistic material editing as well as relighting. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed method performs favorably against existing inverse rendering methods on novel view synthesis and inverse rendering.
Hierarchical Memory Learning for Fine-Grained Scene Graph Generation
Mar 23, 2022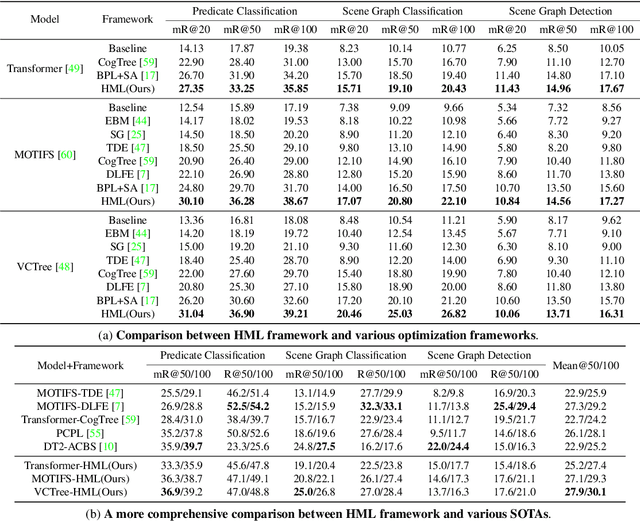
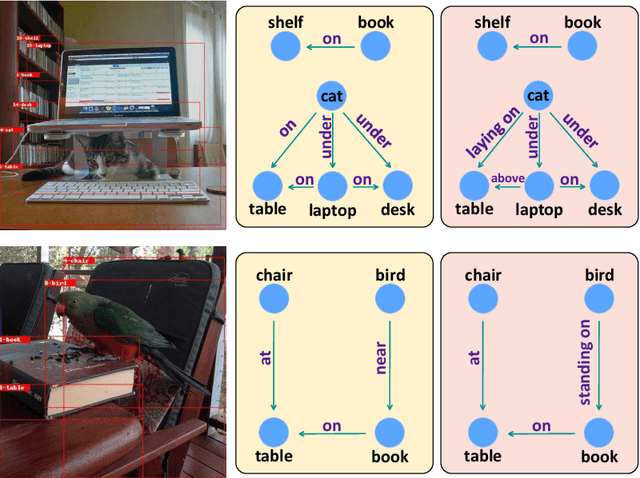
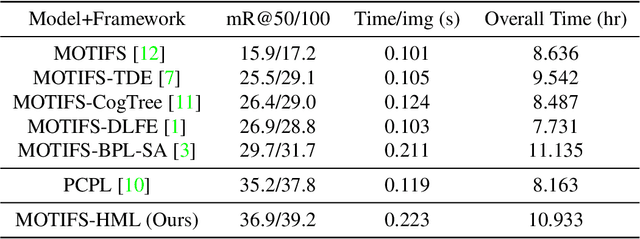
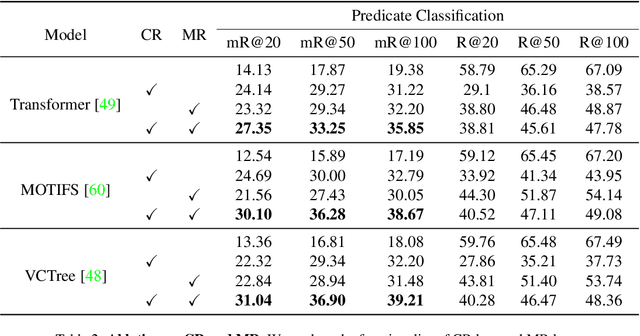
As far as Scene Graph Generation (SGG), coarse and fine predicates mix in the dataset due to the crowd-sourced labeling, and the long-tail problem is also pronounced. Given this tricky situation, many existing SGG methods treat the predicates equally and learn the model under the supervision of mixed-granularity predicates in one stage, leading to relatively coarse predictions. In order to alleviate the negative impact of the suboptimum mixed-granularity annotation and long-tail effect problems, this paper proposes a novel Hierarchical Memory Learning (HML) framework to learn the model from simple to complex, which is similar to the human beings' hierarchical memory learning process. After the autonomous partition of coarse and fine predicates, the model is first trained on the coarse predicates and then learns the fine predicates. In order to realize this hierarchical learning pattern, this paper, for the first time, formulates the HML framework using the new Concept Reconstruction (CR) and Model Reconstruction (MR) constraints. It is worth noticing that the HML framework can be taken as one general optimization strategy to improve various SGG models, and significant improvement can be achieved on the SGG benchmark (i.e., Visual Genome).