 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Paper and Code



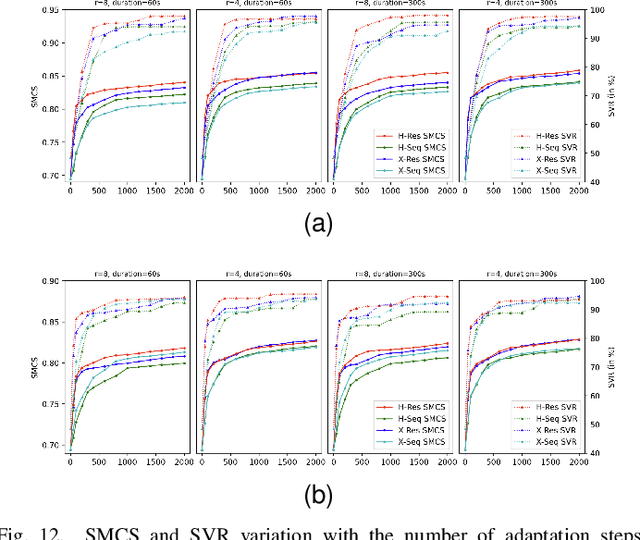
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as "instant" and "fine-grained" adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.