 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Perception: High-Resolution Image Perception Meets Visual RAG
Paper and Code
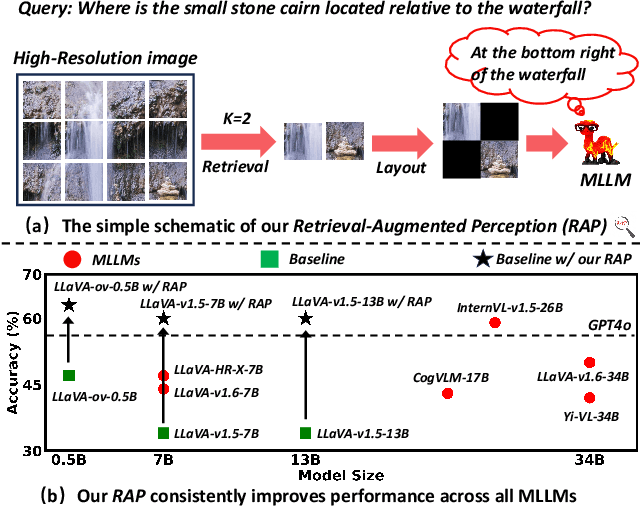
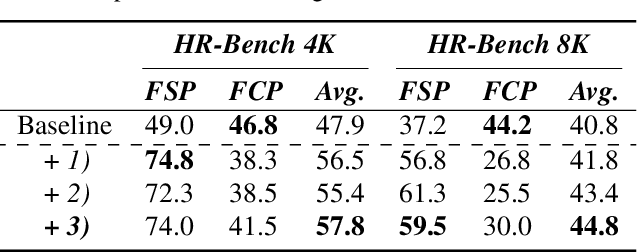
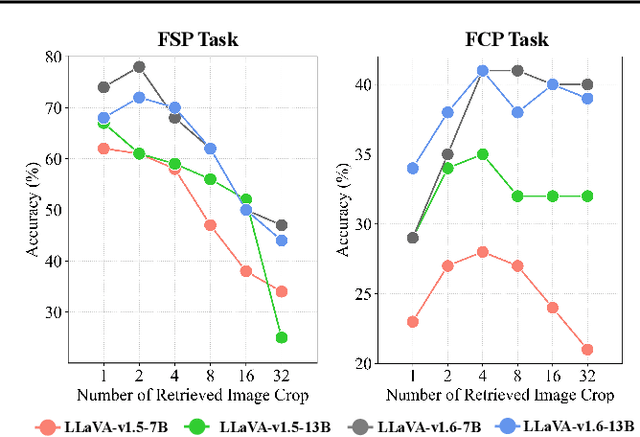
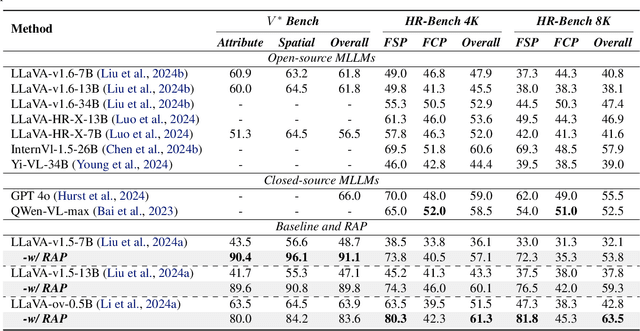
High-resolution (HR) image perception remains a key challenge in multimodal large language models (MLLMs). To overcome the limitations of existing methods, this paper shifts away from prior dedicated heuristic approaches and revisits the most fundamental idea to HR perception by enhancing the long-context capability of MLLMs, driven by recent advances in long-context techniques like retrieval-augmented generation (RAG) for general LLMs. Towards this end, this paper presents the first study exploring the use of RAG to address HR perception challenges. Specifically, we propose Retrieval-Augmented Perception (RAP), a training-free framework that retrieves and fuses relevant image crops while preserving spatial context using the proposed Spatial-Awareness Layout. To accommodate different tasks, the proposed Retrieved-Exploration Search (RE-Search) dynamically selects the optimal number of crops based on model confidence and retrieval scores. Experimental results on HR benchmarks demonstrate the significant effectiveness of RAP, with LLaVA-v1.5-13B achieving a 43% improvement on $V^*$ Bench and 19% on HR-Bench.