 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
May 20, 2026Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions, potentially distorting effect estimates. We formalize the confounding or selection bias that can arise due to user drift and show how intervention-dependent shifts can inflate or attenuate observed differences in user responses under intervention. To diagnose confounding, we propose using negative control outcomes--attributes that should remain invariant under intervention--to identify distribution shifts across intervention conditions, providing evidence of user drift. To mitigate drift, we study adjusting the persona specification by eliciting additional confounders, finding that targeted, setting-relevant confounders can substantially reduce bias across survey-style and multi-turn agent evaluations.
Sleepless Nights, Sugary Days: Creating Synthetic Users with Health Conditions for Realistic Coaching Agent Interactions
Feb 18, 2025We present an end-to-end framework for generating synthetic users for evaluating interactive agents designed to encourage positive behavior changes, such as in health and lifestyle coaching. The synthetic users are grounded in health and lifestyle conditions, specifically sleep and diabetes management in this study, to ensure realistic interactions with the health coaching agent. Synthetic users are created in two stages: first, structured data are generated grounded in real-world health and lifestyle factors in addition to basic demographics and behavioral attributes; second, full profiles of the synthetic users are developed conditioned on the structured data. Interactions between synthetic users and the coaching agent are simulated using generative agent-based models such as Concordia, or directly by prompting a language model. Using two independently-developed agents for sleep and diabetes coaching as case studies, the validity of this framework is demonstrated by analyzing the coaching agent's understanding of the synthetic users' needs and challenges. Finally, through multiple blinded evaluations of user-coach interactions by human experts, we demonstrate that our synthetic users with health and behavioral attributes more accurately portray real human users with the same attributes, compared to generic synthetic users not grounded in such attributes. The proposed framework lays the foundation for efficient development of conversational agents through extensive, realistic, and grounded simulated interactions.
Evaluating unsupervised disentangled representation learning for genomic discovery and disease risk prediction
Jul 17, 2023High-dimensional clinical data have become invaluable resources for genetic studies, due to their accessibility in biobank-scale datasets and the development of high performance modeling techniques especially using deep learning. Recent work has shown that low dimensional embeddings of these clinical data learned by variational autoencoders (VAE) can be used for genome-wide association studies and polygenic risk prediction. In this work, we consider multiple unsupervised learning methods for learning disentangled representations, namely autoencoders, VAE, beta-VAE, and FactorVAE, in the context of genetic association studies. Using spirograms from UK Biobank as a running example, we observed improvements in the number of genome-wide significant loci, heritability, and performance of polygenic risk scores for asthma and chronic obstructive pulmonary disease by using FactorVAE or beta-VAE, compared to standard VAE or non-variational autoencoders. FactorVAEs performed effectively across multiple values of the regularization hyperparameter, while beta-VAEs were much more sensitive to the hyperparameter values.
SLOE: A Faster Method for Statistical Inference in High-Dimensional Logistic Regression
Mar 23, 2021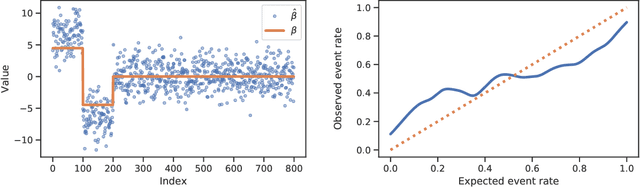
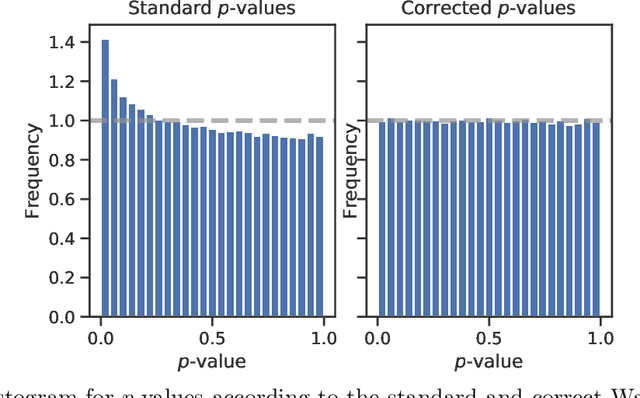
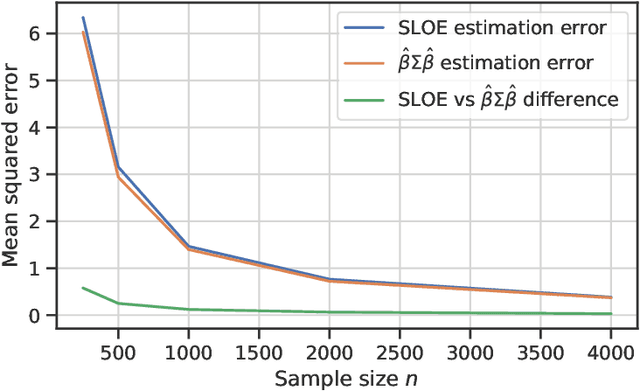

Logistic regression remains one of the most widely used tools in applied statistics, machine learning and data science. Practical datasets often have a substantial number of features $d$ relative to the sample size $n$. In these cases, the logistic regression maximum likelihood estimator (MLE) is biased, and its standard large-sample approximation is poor. In this paper, we develop an improved method for debiasing predictions and estimating frequentist uncertainty for such datasets. We build on recent work characterizing the asymptotic statistical behavior of the MLE in the regime where the aspect ratio $d / n$, instead of the number of features $d$, remains fixed as $n$ grows. In principle, this approximation facilitates bias and uncertainty corrections, but in practice, these corrections require an estimate of the signal strength of the predictors. Our main contribution is SLOE, an estimator of the signal strength with convergence guarantees that reduces the computation time of estimation and inference by orders of magnitude. The bias correction that this facilitates also reduces the variance of the predictions, yielding narrower confidence intervals with higher (valid) coverage of the true underlying probabilities and parameters. We provide an open source package for this method, available at https://github.com/google-research/sloe-logistic.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020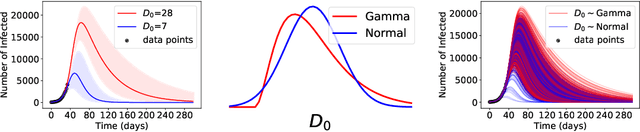


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.