 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

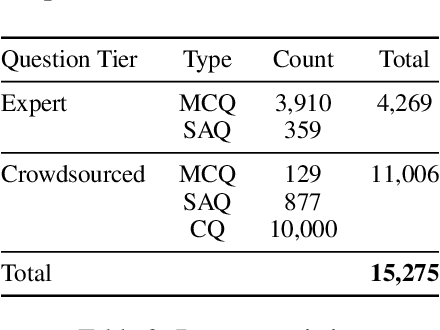

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
Contextual Evaluation of Large Language Models for Classifying Tropical and Infectious Diseases
Sep 13, 2024While large language models (LLMs) have shown promise for medical question answering, there is limited work focused on tropical and infectious disease-specific exploration. We build on an opensource tropical and infectious diseases (TRINDs) dataset, expanding it to include demographic and semantic clinical and consumer augmentations yielding 11000+ prompts. We evaluate LLM performance on these, comparing generalist and medical LLMs, as well as LLM outcomes to human experts. We demonstrate through systematic experimentation, the benefit of contextual information such as demographics, location, gender, risk factors for optimal LLM response. Finally we develop a prototype of TRINDs-LM, a research tool that provides a playground to navigate how context impacts LLM outputs for health.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
The Case for Globalizing Fairness: A Mixed Methods Study on Colonialism, AI, and Health in Africa
Mar 11, 2024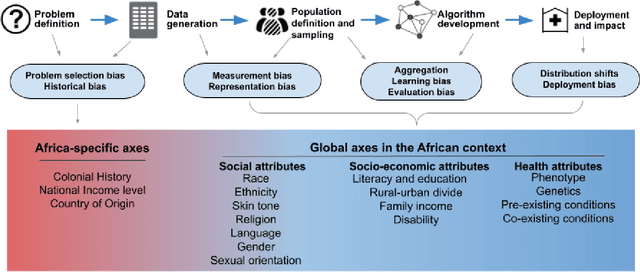
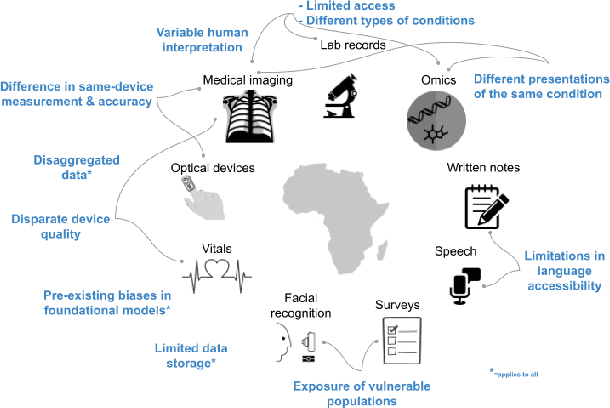
With growing application of machine learning (ML) technologies in healthcare, there have been calls for developing techniques to understand and mitigate biases these systems may exhibit. Fair-ness considerations in the development of ML-based solutions for health have particular implications for Africa, which already faces inequitable power imbalances between the Global North and South.This paper seeks to explore fairness for global health, with Africa as a case study. We conduct a scoping review to propose axes of disparities for fairness consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. We then conduct qualitative research studies with 672 general population study participants and 28 experts inML, health, and policy focused on Africa to obtain corroborative evidence on the proposed axes of disparities. Our analysis focuses on colonialism as the attribute of interest and examines the interplay between artificial intelligence (AI), health, and colonialism. Among the pre-identified attributes, we found that colonial history, country of origin, and national income level were specific axes of disparities that participants believed would cause an AI system to be biased.However, there was also divergence of opinion between experts and general population participants. Whereas experts generally expressed a shared view about the relevance of colonial history for the development and implementation of AI technologies in Africa, the majority of the general population participants surveyed did not think there was a direct link between AI and colonialism. Based on these findings, we provide practical recommendations for developing fairness-aware ML solutions for health in Africa.
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
Dec 21, 2023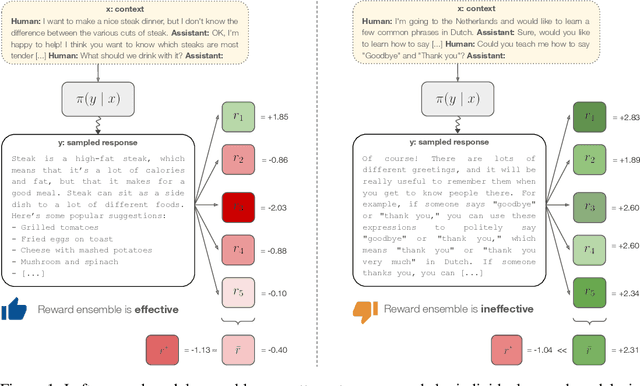

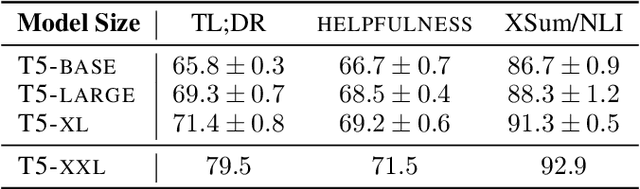
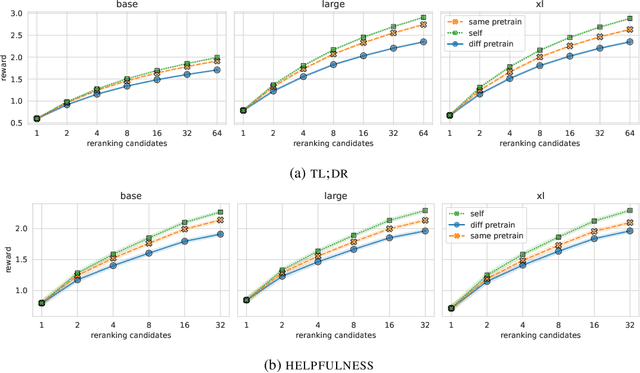
Reward models play a key role in aligning language model applications towards human preferences. However, this setup creates an incentive for the language model to exploit errors in the reward model to achieve high estimated reward, a phenomenon often termed \emph{reward hacking}. A natural mitigation is to train an ensemble of reward models, aggregating over model outputs to obtain a more robust reward estimate. We explore the application of reward ensembles to alignment at both training time (through reinforcement learning) and inference time (through reranking). First, we show that reward models are \emph{underspecified}: reward models that perform similarly in-distribution can yield very different rewards when used in alignment, due to distribution shift. Second, underspecification results in overoptimization, where alignment to one reward model does not improve reward as measured by another reward model trained on the same data. Third, overoptimization is mitigated by the use of reward ensembles, and ensembles that vary by their \emph{pretraining} seeds lead to better generalization than ensembles that differ only by their \emph{fine-tuning} seeds, with both outperforming individual reward models. However, even pretrain reward ensembles do not eliminate reward hacking: we show several qualitative reward hacking phenomena that are not mitigated by ensembling because all reward models in the ensemble exhibit similar error patterns.
Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering
Sep 29, 2023



Prompting and in-context learning (ICL) have become efficient learning paradigms for large language models (LLMs). However, LLMs suffer from prompt brittleness and various bias factors in the prompt, including but not limited to the formatting, the choice verbalizers, and the ICL examples. To address this problem that results in unexpected performance degradation, calibration methods have been developed to mitigate the effects of these biases while recovering LLM performance. In this work, we first conduct a systematic analysis of the existing calibration methods, where we both provide a unified view and reveal the failure cases. Inspired by these analyses, we propose Batch Calibration (BC), a simple yet intuitive method that controls the contextual bias from the batched input, unifies various prior approaches, and effectively addresses the aforementioned issues. BC is zero-shot, inference-only, and incurs negligible additional costs. In the few-shot setup, we further extend BC to allow it to learn the contextual bias from labeled data. We validate the effectiveness of BC with PaLM 2-(S, M, L) and CLIP models and demonstrate state-of-the-art performance over previous calibration baselines across more than 10 natural language understanding and image classification tasks.
STUDY: Socially Aware Temporally Casual Decoder Recommender Systems
Jun 02, 2023With the overwhelming amount of data available both on and offline today, recommender systems have become much needed to help users find items tailored to their interests. When social network information exists there are methods that utilize this information to make better recommendations, however the methods are often clunky with complex architectures and training procedures. Furthermore many of the existing methods utilize graph neural networks which are notoriously difficult to train. To address this, we propose Socially-aware Temporally caUsal Decoder recommender sYstems (STUDY). STUDY does joint inference over groups of users who are adjacent in the social network graph using a single forward pass of a modified transformer decoder network. We test our method in a school-based educational content setting, using classroom structure to define social networks. Our method outperforms both social and sequential methods while maintaining the design simplicity of a single homogeneous network that models all interactions in the data. We also carry out ablation studies to understand the drivers of our performance gains and find that our model depends on leveraging a social network structure that effectively models the similarities in user behavior.
Globalizing Fairness Attributes in Machine Learning: A Case Study on Health in Africa
Apr 05, 2023With growing machine learning (ML) applications in healthcare, there have been calls for fairness in ML to understand and mitigate ethical concerns these systems may pose. Fairness has implications for global health in Africa, which already has inequitable power imbalances between the Global North and South. This paper seeks to explore fairness for global health, with Africa as a case study. We propose fairness attributes for consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. This work serves as a basis and call for action for furthering research into fairness in global health.
Longitudinal Modeling of Multiple Sclerosis using Continuous Time Models
Feb 15, 2023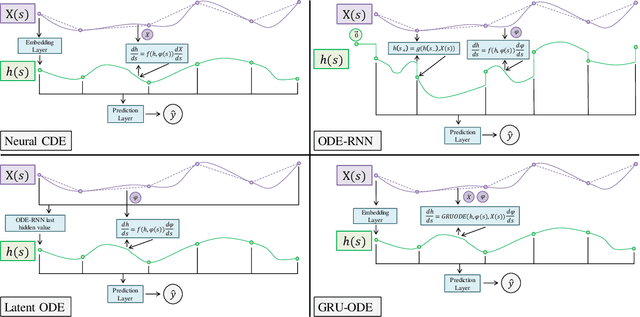
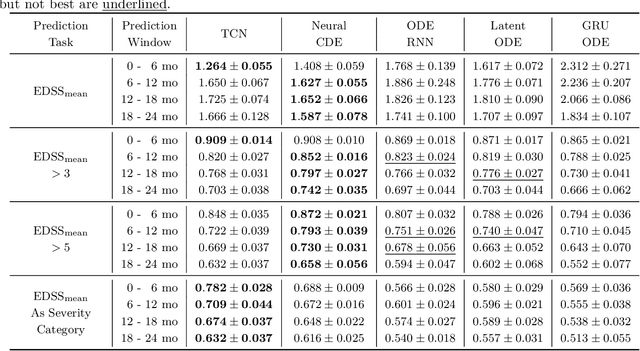
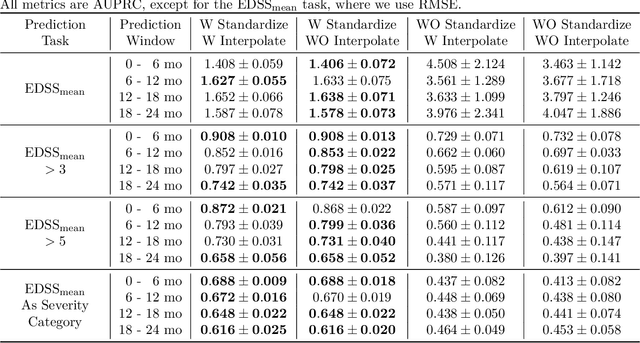
Multiple sclerosis is a disease that affects the brain and spinal cord, it can lead to severe disability and has no known cure. The majority of prior work in machine learning for multiple sclerosis has been centered around using Magnetic Resonance Imaging scans or laboratory tests; these modalities are both expensive to acquire and can be unreliable. In a recent paper it was shown that disease progression can be predicted effectively using performance outcome measures (POMs) and demographic data. In our work we extend on this to focus on the modeling side, using continuous time models on POMs and demographic data to predict progression. We evaluate four continuous time models using a publicly available multiple sclerosis dataset. We find that continuous models are often able to outperform discrete time models. We also carry out an extensive ablation to discover the sources of performance gains, we find that standardizing existing features leads to a larger performance increase than interpolating missing features.