 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned to the Object, not to the Image: A Unified Pose-aligned Representation for Fine-grained Recognition
Paper and Code
Sep 11, 2018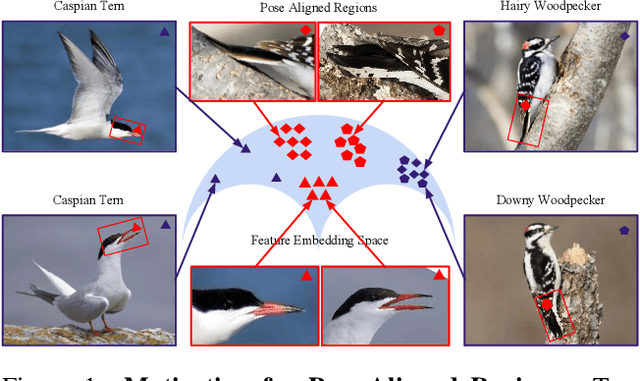
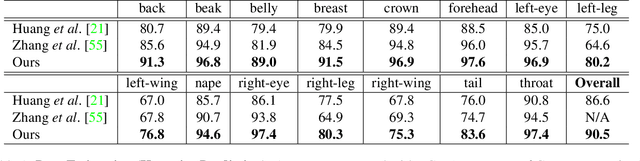


Dramatic appearance variation due to pose constitutes a great challenge in fine-grained recognition, one which recent methods using attention mechanisms or second-order statistics fail to adequately address. Modern CNNs typically lack an explicit understanding of object pose and are instead confused by entangled pose and appearance. In this paper, we propose a unified object representation built from a hierarchy of pose-aligned regions. Rather than representing an object by regions aligned to image axes, the proposed representation characterizes appearance relative to the object's pose using pose-aligned patches whose features are robust to variations in pose, scale and rotation. We propose an algorithm that performs pose estimation and forms the unified object representation as the concatenation of hierarchical pose-aligned regions features, which is then fed into a classification network. The proposed algorithm surpasses the performance of other approaches, increasing the state-of-the-art by nearly 2% on the widely-used CUB-200 dataset and by more than 8% on the much larger NABirds dataset. The effectiveness of this paradigm relative to competing methods suggests the critical importance of disentangling pose and appearance for continued progress in fine-grained recognition.