 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fractal Pre-training
Oct 06, 2021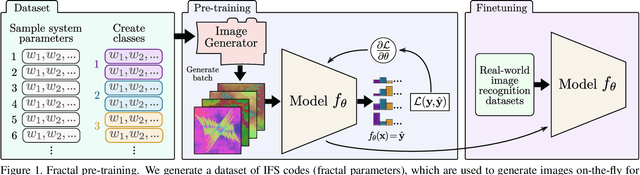



The deep neural networks used in modern computer vision systems require enormous image datasets to train them. These carefully-curated datasets typically have a million or more images, across a thousand or more distinct categories. The process of creating and curating such a dataset is a monumental undertaking, demanding extensive effort and labelling expense and necessitating careful navigation of technical and social issues such as label accuracy, copyright ownership, and content bias. What if we had a way to harness the power of large image datasets but with few or none of the major issues and concerns currently faced? This paper extends the recent work of Kataoka et. al. (2020), proposing an improved pre-training dataset based on dynamically-generated fractal images. Challenging issues with large-scale image datasets become points of elegance for fractal pre-training: perfect label accuracy at zero cost; no need to store/transmit large image archives; no privacy/demographic bias/concerns of inappropriate content, as no humans are pictured; limitless supply and diversity of images; and the images are free/open-source. Perhaps surprisingly, avoiding these difficulties imposes only a small penalty in performance. Leveraging a newly-proposed pre-training task -- multi-instance prediction -- our experiments demonstrate that fine-tuning a network pre-trained using fractals attains 92.7-98.1\% of the accuracy of an ImageNet pre-trained network.
Fair Comparison: Quantifying Variance in Resultsfor Fine-grained Visual Categorization
Sep 08, 2021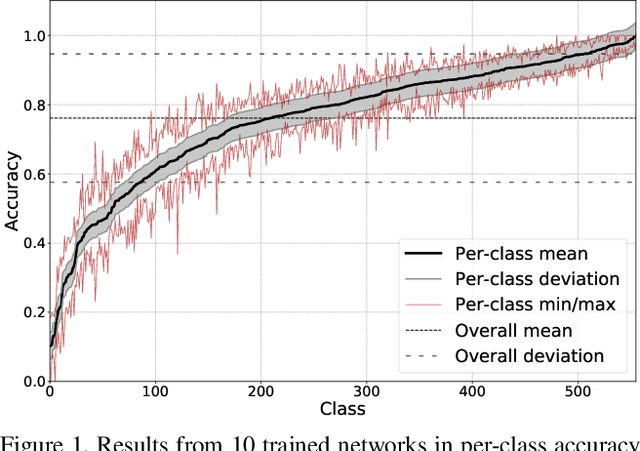
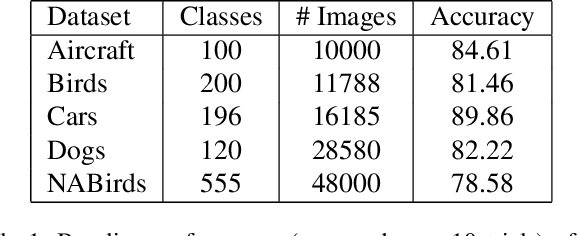


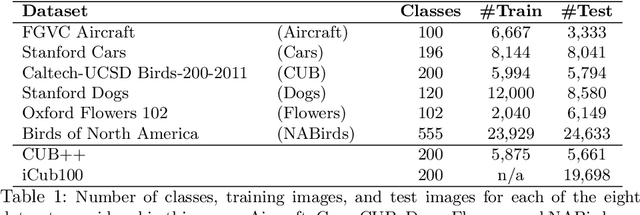
For the task of image classification, researchers work arduously to develop the next state-of-the-art (SOTA) model, each bench-marking their own performance against that of their predecessors and of their peers. Unfortunately, the metric used most frequently to describe a model's performance, average categorization accuracy, is often used in isolation. As the number of classes increases, such as in fine-grained visual categorization (FGVC), the amount of information conveyed by average accuracy alone dwindles. While its most glaring weakness is its failure to describe the model's performance on a class-by-class basis, average accuracy also fails to describe how performance may vary from one trained model of the same architecture, on the same dataset, to another (both averaged across all categories and at the per-class level). We first demonstrate the magnitude of these variations across models and across class distributions based on attributes of the data, comparing results on different visual domains and different per-class image distributions, including long-tailed distributions and few-shot subsets. We then analyze the impact various FGVC methods have on overall and per-class variance. From this analysis, we both highlight the importance of reporting and comparing methods based on information beyond overall accuracy, as well as point out techniques that mitigate variance in FGVC results.
* Accepted at WACV 2021; 8 pages text, 2 pages bib, 12 figures
Facing the Hard Problems in FGVC
Jun 24, 2020

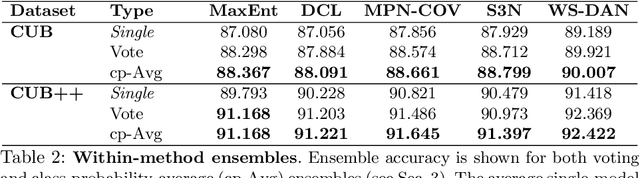
In fine-grained visual categorization (FGVC), there is a near-singular focus in pursuit of attaining state-of-the-art (SOTA) accuracy. This work carefully analyzes the performance of recent SOTA methods, quantitatively, but more importantly, qualitatively. We show that these models universally struggle with certain "hard" images, while also making complementary mistakes. We underscore the importance of such analysis, and demonstrate that combining complementary models can improve accuracy on the popular CUB-200 dataset by over 5%. In addition to detailed analysis and characterization of the errors made by these SOTA methods, we provide a clear set of recommended directions for future FGVC researchers.
Neural Network Interpretation via Fine Grained Textual Summarization
Sep 06, 2018
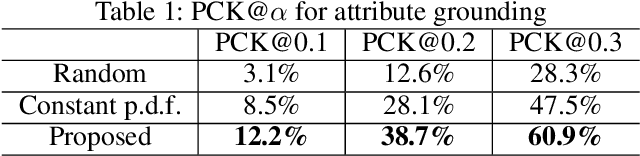
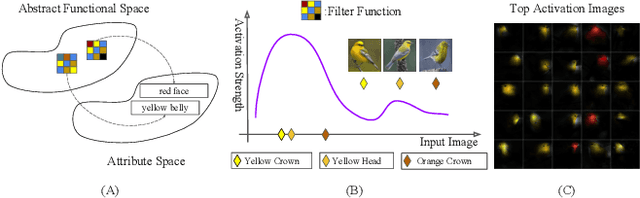

Current visualization based network interpretation methodssuffer from lacking semantic-level information. In this paper, we introduce the novel task of interpreting classification models using fine grained textual summarization. Along with the label prediction, the network will generate a sentence explaining its decision. Constructing a fully annotated dataset of filter|text pairs is unrealistic because of image to filter response function complexity. We instead propose a weakly-supervised learning algorithm leveraging off-the-shelf image caption annotations. Central to our algorithm is the filter-level attribute probability density function (p.d.f.), learned as a conditional probability through Bayesian inference with the input image and its feature map as latent variables. We show our algorithm faithfully reflects the features learned by the model using rigorous applications like attribute based image retrieval and unsupervised text grounding. We further show that the textual summarization process can help in understanding network failure patterns and can provide clues for further improvements.