 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHNeRV: A Hybrid Neural Representation for Videos
Apr 05, 2023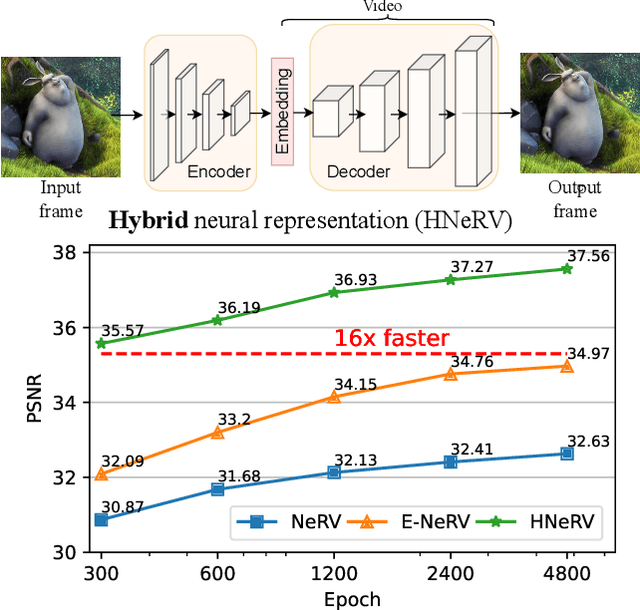
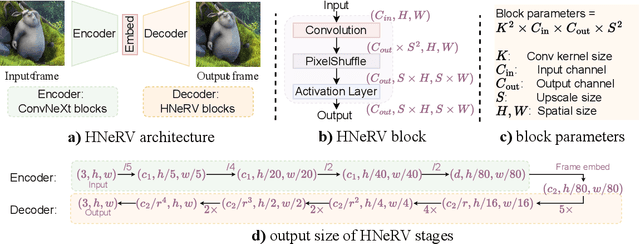

Implicit neural representations store videos as neural networks and have performed well for various vision tasks such as video compression and denoising. With frame index or positional index as input, implicit representations (NeRV, E-NeRV, \etc) reconstruct video from fixed and content-agnostic embeddings. Such embedding largely limits the regression capacity and internal generalization for video interpolation. In this paper, we propose a Hybrid Neural Representation for Videos (HNeRV), where a learnable encoder generates content-adaptive embeddings, which act as the decoder input. Besides the input embedding, we introduce HNeRV blocks, which ensure model parameters are evenly distributed across the entire network, such that higher layers (layers near the output) can have more capacity to store high-resolution content and video details. With content-adaptive embeddings and re-designed architecture, HNeRV outperforms implicit methods in video regression tasks for both reconstruction quality ($+4.7$ PSNR) and convergence speed ($16\times$ faster), and shows better internal generalization. As a simple and efficient video representation, HNeRV also shows decoding advantages for speed, flexibility, and deployment, compared to traditional codecs~(H.264, H.265) and learning-based compression methods. Finally, we explore the effectiveness of HNeRV on downstream tasks such as video compression and video inpainting. We provide project page at https://haochen-rye.github.io/HNeRV, and Code at https://github.com/haochen-rye/HNeRV
CNeRV: Content-adaptive Neural Representation for Visual Data
Nov 18, 2022Compression and reconstruction of visual data have been widely studied in the computer vision community, even before the popularization of deep learning. More recently, some have used deep learning to improve or refine existing pipelines, while others have proposed end-to-end approaches, including autoencoders and implicit neural representations, such as SIREN and NeRV. In this work, we propose Neural Visual Representation with Content-adaptive Embedding (CNeRV), which combines the generalizability of autoencoders with the simplicity and compactness of implicit representation. We introduce a novel content-adaptive embedding that is unified, concise, and internally (within-video) generalizable, that compliments a powerful decoder with a single-layer encoder. We match the performance of NeRV, a state-of-the-art implicit neural representation, on the reconstruction task for frames seen during training while far surpassing for frames that are skipped during training (unseen images). To achieve similar reconstruction quality on unseen images, NeRV needs 120x more time to overfit per-frame due to its lack of internal generalization. With the same latent code length and similar model size, CNeRV outperforms autoencoders on reconstruction of both seen and unseen images. We also show promising results for visual data compression. More details can be found in the project pagehttps://haochen-rye.github.io/CNeRV/
Facing the Hard Problems in FGVC
Jun 24, 2020

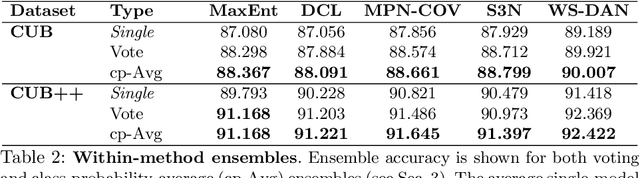
In fine-grained visual categorization (FGVC), there is a near-singular focus in pursuit of attaining state-of-the-art (SOTA) accuracy. This work carefully analyzes the performance of recent SOTA methods, quantitatively, but more importantly, qualitatively. We show that these models universally struggle with certain "hard" images, while also making complementary mistakes. We underscore the importance of such analysis, and demonstrate that combining complementary models can improve accuracy on the popular CUB-200 dataset by over 5%. In addition to detailed analysis and characterization of the errors made by these SOTA methods, we provide a clear set of recommended directions for future FGVC researchers.