 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuPLaR : Efficient Latent Compression of LLM Reasoning Chains with Rule-Based Priors From Multi-Step to One-Step
May 10, 2026The Chain-of-Thought (CoT) paradigm, while enhancing the interpretability of Large Language Models (LLMs), is constrained by the inefficiencies and expressive limits of natural language. Latent Chain-of-Thought (latent CoT) reasoning, which operates in a continuous latent space, offers a promising alternative but faces challenges from structural complexities in existing multi-step or multi-model paradigms, such as error propagation and coordination overhead. In this paper, we introduce One-Model One-Step, a novel compression framework for Latent Reasoning with Rule-Based Priors(RuPLaR) to address this challenge. Our method trains an LLM to autonomously generate latent reasoning tokens in a single training stage, guided by rule-based prior probability distributions, thereby eliminating cascaded processes and inter-model dependencies. To ensure reasoning quality, we design a joint training objective that enforces answer consistency via cross-entropy, aligns soft tokens with rule-based priors via KL divergence (the Soft Thinking constraint), and adds a problem-thought semantic alignment constraint in the representation space. Extensive experiments show that our compression framework not only improves accuracy by 11.1% over existing latent CoT methods but also achieves this with minimal token usage, underscoring its effectiveness and extensibility. Code: https://github.com/xiaocen-luo/RuPLaR.
LongFlow: Efficient KV Cache Compression for Reasoning M
Mar 12, 2026Recent reasoning models such as OpenAI-o1 and DeepSeek-R1 have shown strong performance on complex tasks including mathematical reasoning and code generation. However, this performance gain comes with substantially longer output sequences, leading to significantly increased deployment costs. In particular, long outputs require large KV caches, resulting in high memory consumption and severe bandwidth pressure during attention computation. Most existing KV cache optimization methods are designed for long-input, short-output scenarios and are ineffective for the long-output setting of reasoning models. Moreover, importance estimation in prior work is computationally expensive and becomes prohibitive when continuous re-evaluation is required during long generation. To address these challenges, we propose LongFlow, a KV cache compression method with an efficient importance estimation metric derived from an intermediate result of attention computation using only the current query. This design introduces negligible computational overhead and requires no auxiliary storage. We further develop a custom kernel that fuses FlashAttention, importance estimation, and token eviction into a single optimized operator, improving system-level efficiency. Experiments show that LongFlow achieves up to an 11.8 times throughput improvement with 80% KV cache compression with minimal impact on model accuracy.
Accurate KV Cache Quantization with Outlier Tokens Tracing
May 16, 2025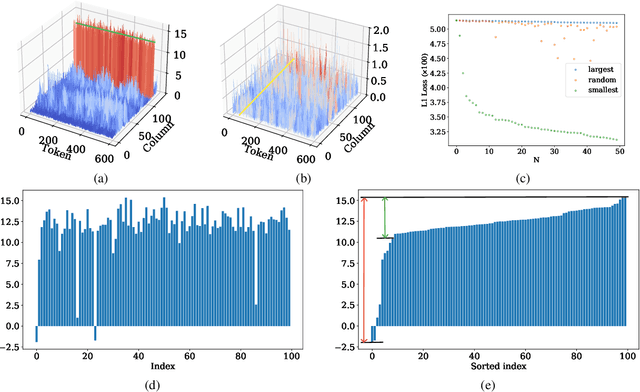
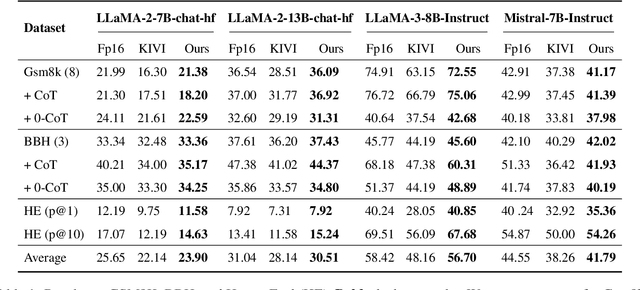


The impressive capabilities of Large Language Models (LLMs) come at the cost of substantial computational resources during deployment. While KV Cache can significantly reduce recomputation during inference, it also introduces additional memory overhead. KV Cache quantization presents a promising solution, striking a good balance between memory usage and accuracy. Previous research has shown that the Keys are distributed by channel, while the Values are distributed by token. Consequently, the common practice is to apply channel-wise quantization to the Keys and token-wise quantization to the Values. However, our further investigation reveals that a small subset of unusual tokens exhibit unique characteristics that deviate from this pattern, which can substantially impact quantization accuracy. To address this, we develop a simple yet effective method to identify these tokens accurately during the decoding process and exclude them from quantization as outlier tokens, significantly improving overall accuracy. Extensive experiments show that our method achieves significant accuracy improvements under 2-bit quantization and can deliver a 6.4 times reduction in memory usage and a 2.3 times increase in throughput.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024

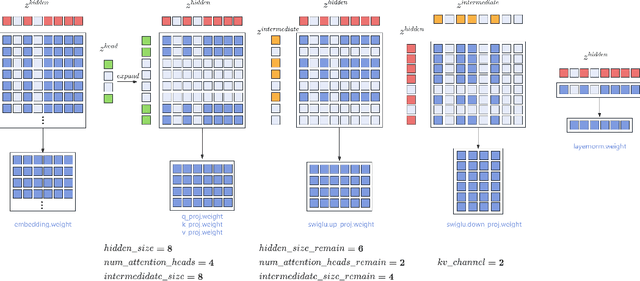
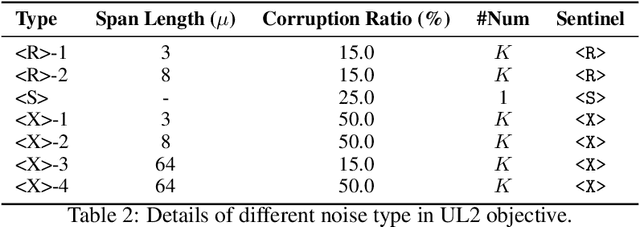
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
Chinese grammatical error correction based on knowledge distillation
Aug 05, 2022

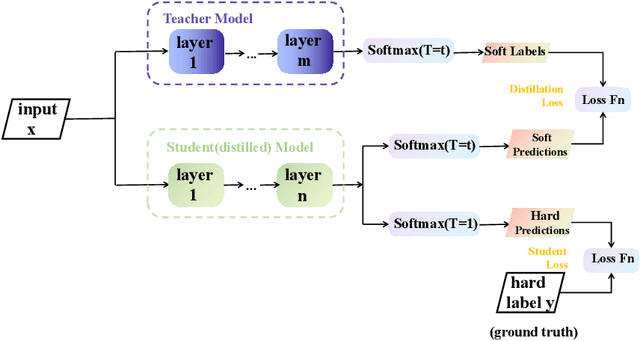
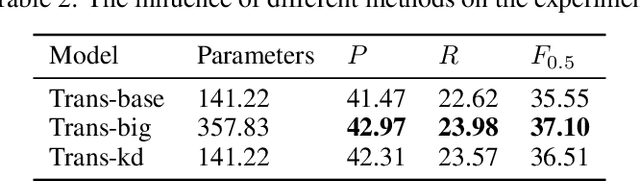
In view of the poor robustness of existing Chinese grammatical error correction models on attack test sets and large model parameters, this paper uses the method of knowledge distillation to compress model parameters and improve the anti-attack ability of the model. In terms of data, the attack test set is constructed by integrating the disturbance into the standard evaluation data set, and the model robustness is evaluated by the attack test set. The experimental results show that the distilled small model can ensure the performance and improve the training speed under the condition of reducing the number of model parameters, and achieve the optimal effect on the attack test set, and the robustness is significantly improved.