Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese grammatical error correction based on knowledge distillation
Paper and Code
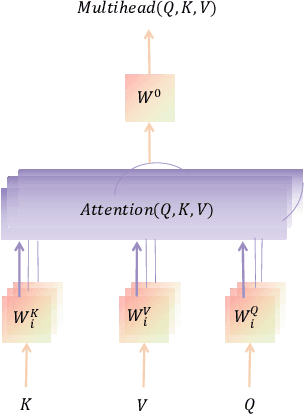

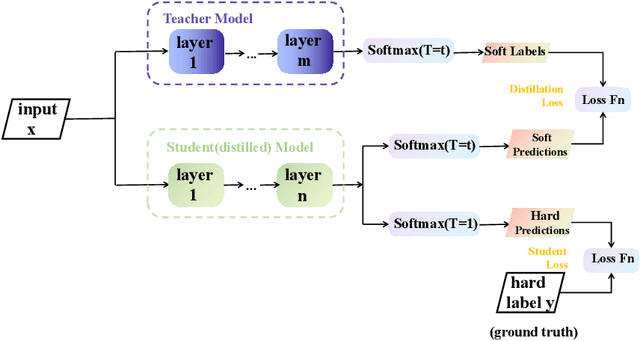
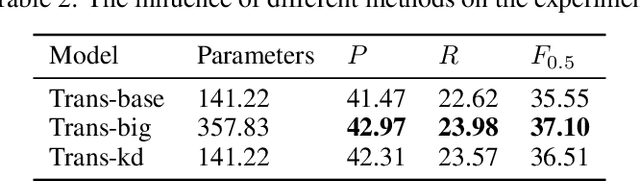
In view of the poor robustness of existing Chinese grammatical error correction models on attack test sets and large model parameters, this paper uses the method of knowledge distillation to compress model parameters and improve the anti-attack ability of the model. In terms of data, the attack test set is constructed by integrating the disturbance into the standard evaluation data set, and the model robustness is evaluated by the attack test set. The experimental results show that the distilled small model can ensure the performance and improve the training speed under the condition of reducing the number of model parameters, and achieve the optimal effect on the attack test set, and the robustness is significantly improved.
* The paper need to withdrawn due to my advisor's request. And we will
submit a new one after we modify it and translate it into English to make the
paper be read more widely.
View paper on