 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Your Mistakes: Tree-like Self-Play for Secure Code LLMs
Jun 02, 2026While Large Language Models (LLMs) excel in code generation, they remain prone to replicating subtle yet critical vulnerabilities endemic to their training data. Current alignment techniques, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), typically apply coarse-grained optimization at the sequence level. This approach often fails to address the localized nature of security flaws, where a single incorrect token choice can compromise an entire program. To bridge this gap, we introduce Tree-like Self-Play (TSP), a framework that reframes secure code generation as a fine-grained sequential decision process. Unlike standard methods that blindly maximize likelihood, TSP constructs a decision tree where the model explores branching trajectories--generating both secure "golden paths" and vulnerable variants. By treating code generation as a self-play game, the model learns to strictly discriminate against its own localized errors. This provides a dense, on-policy learning signal that forces self-correction precisely at the critical decision nodes where vulnerabilities typically emerge. Our experiments demonstrate that TSP fundamentally enhances model reliability. In Python security benchmarks, TSP boosts CodeLlama-7B's pass rate (SPR@1) to 75.8%, significantly outperforming SFT (57.0%) and unstructured self-play baselines. Crucially, TSP induces robust out-of-distribution generalization: the model not only reduces vulnerabilities in unseen categories (CWEs) by 24.5% but also successfully transfers security principles learned from C/C++ to diverse languages, including Python, Go, and JavaScript. This suggests that TSP does not merely memorize patches, but internalizes abstract, language-agnostic security logic.
Unified Graph Prompt Learning via Low-Rank Graph Message Prompting
Apr 13, 2026Graph Data Prompt (GDP), which introduces specific prompts in graph data for efficiently adapting pre-trained GNNs, has become a mainstream approach to graph fine-tuning learning problem. However, existing GDPs have been respectively designed for distinct graph component (e.g., node features, edge features, edge weights) and thus operate within limited prompt spaces for graph data. To the best of our knowledge, it still lacks a unified prompter suitable for targeting all graph components simultaneously. To address this challenge, in this paper, we first propose to reinterpret a wide range of existing GDPs from an aspect of Graph Message Prompt (GMP) paradigm. Based on GMP, we then introduce a novel graph prompt learning approach, termed Low-Rank GMP (LR-GMP), which leverages low-rank prompt representation to achieve an effective and compact graph prompt learning. Unlike traditional GDPs that target distinct graph components separately, LR-GMP concurrently performs prompting on all graph components in a unified manner, thereby achieving significantly superior generalization and robustness on diverse downstream tasks. Extensive experiments on several graph benchmark datasets demonstrate the effectiveness and advantages of our proposed LR-GMP.
A Multi-modal Detection System for Infrastructure-based Freight Signal Priority
Feb 19, 2026Freight vehicles approaching signalized intersections require reliable detection and motion estimation to support infrastructure-based Freight Signal Priority (FSP). Accurate and timely perception of vehicle type, position, and speed is essential for enabling effective priority control strategies. This paper presents the design, deployment, and evaluation of an infrastructure-based multi-modal freight vehicle detection system integrating LiDAR and camera sensors. A hybrid sensing architecture is adopted, consisting of an intersection-mounted subsystem and a midblock subsystem, connected via wireless communication for synchronized data transmission. The perception pipeline incorporates both clustering-based and deep learning-based detection methods with Kalman filter tracking to achieve stable real-time performance. LiDAR measurements are registered into geodetic reference frames to support lane-level localization and consistent vehicle tracking. Field evaluations demonstrate that the system can reliably monitor freight vehicle movements at high spatio-temporal resolution. The design and deployment provide practical insights for developing infrastructure-based sensing systems to support FSP applications.
ROG: Retrieval-Augmented LLM Reasoning for Complex First-Order Queries over Knowledge Graphs
Feb 02, 2026Answering first-order logic (FOL) queries over incomplete knowledge graphs (KGs) is difficult, especially for complex query structures that compose projection, intersection, union, and negation. We propose ROG, a retrieval-augmented framework that combines query-aware neighborhood retrieval with large language model (LLM) chain-of-thought reasoning. ROG decomposes a multi-operator query into a sequence of single-operator sub-queries and grounds each step in compact, query-relevant neighborhood evidence. Intermediate answer sets are cached and reused across steps, improving consistency on deep reasoning chains. This design reduces compounding errors and yields more robust inference on complex and negation-heavy queries. Overall, ROG provides a practical alternative to embedding-based logical reasoning by replacing learned operators with retrieval-grounded, step-wise inference. Experiments on standard KG reasoning benchmarks show consistent gains over strong embedding-based baselines, with the largest improvements on high-complexity and negation-heavy query types.
Robust Graph Fine-Tuning with Adversarial Graph Prompting
Jan 01, 2026Parameter-Efficient Fine-Tuning (PEFT) method has emerged as a dominant paradigm for adapting pre-trained GNN models to downstream tasks. However, existing PEFT methods usually exhibit significant vulnerability to various noise and attacks on graph topology and node attributes/features. To address this issue, for the first time, we propose integrating adversarial learning into graph prompting and develop a novel Adversarial Graph Prompting (AGP) framework to achieve robust graph fine-tuning. Our AGP has two key aspects. First, we propose the general problem formulation of AGP as a min-max optimization problem and develop an alternating optimization scheme to solve it. For inner maximization, we propose Joint Projected Gradient Descent (JointPGD) algorithm to generate strong adversarial noise. For outer minimization, we employ a simple yet effective module to learn the optimal node prompts to counteract the adversarial noise. Second, we demonstrate that the proposed AGP can theoretically address both graph topology and node noise. This confirms the versatility and robustness of our AGP fine-tuning method across various graph noise. Note that, the proposed AGP is a general method that can be integrated with various pre-trained GNN models to enhance their robustness on the downstream tasks. Extensive experiments on multiple benchmark tasks validate the robustness and effectiveness of AGP method compared to state-of-the-art methods.
A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
Dec 22, 2025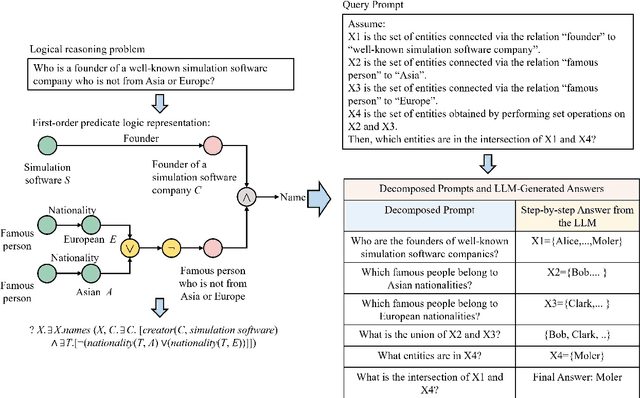
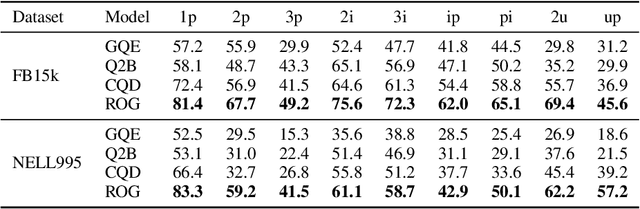
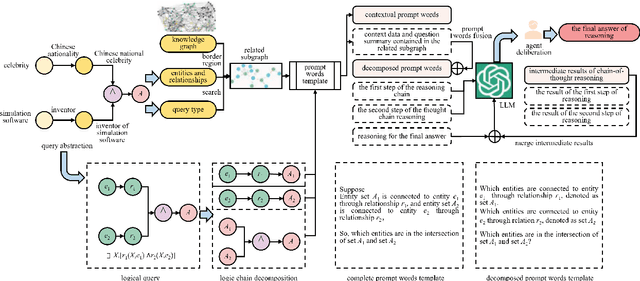
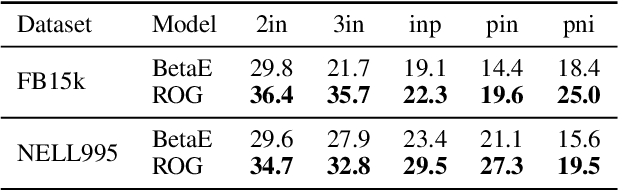
Reasoning over knowledge graphs (KGs) with first-order logic (FOL) queries is challenging due to the inherent incompleteness of real-world KGs and the compositional complexity of logical query structures. Most existing methods rely on embedding entities and relations into continuous geometric spaces and answer queries via differentiable set operations. While effective for simple query patterns, these approaches often struggle to generalize to complex queries involving multiple operators, deeper reasoning chains, or heterogeneous KG schemas. We propose ROG (Reasoning Over knowledge Graphs with large language models), an ensemble-style framework that combines query-aware KG neighborhood retrieval with large language model (LLM)-based chain-of-thought reasoning. ROG decomposes complex FOL queries into sequences of simpler sub-queries, retrieves compact, query-relevant subgraphs as contextual evidence, and performs step-by-step logical inference using an LLM, avoiding the need for task-specific embedding optimization. Experiments on standard KG reasoning benchmarks demonstrate that ROG consistently outperforms strong embedding-based baselines in terms of mean reciprocal rank (MRR), with particularly notable gains on high-complexity query types. These results suggest that integrating structured KG retrieval with LLM-driven logical reasoning offers a robust and effective alternative for complex KG reasoning tasks.
Self-Correction Makes LLMs Better Parsers
Apr 19, 2025Large language models (LLMs) have achieved remarkable success across various natural language processing (NLP) tasks. However, recent studies suggest that they still face challenges in performing fundamental NLP tasks essential for deep language understanding, particularly syntactic parsing. In this paper, we conduct an in-depth analysis of LLM parsing capabilities, delving into the specific shortcomings of their parsing results. We find that LLMs may stem from limitations to fully leverage grammar rules in existing treebanks, which restricts their capability to generate valid syntactic structures. To help LLMs acquire knowledge without additional training, we propose a self-correction method that leverages grammar rules from existing treebanks to guide LLMs in correcting previous errors. Specifically, we automatically detect potential errors and dynamically search for relevant rules, offering hints and examples to guide LLMs in making corrections themselves. Experimental results on three datasets with various LLMs, demonstrate that our method significantly improves performance in both in-domain and cross-domain settings on the English and Chinese datasets.
PDB: Not All Drivers Are the Same -- A Personalized Dataset for Understanding Driving Behavior
Mar 09, 2025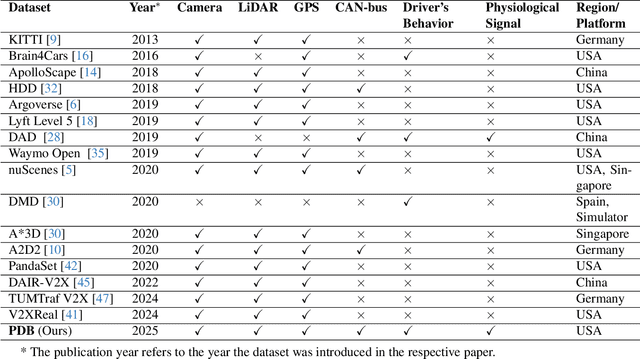
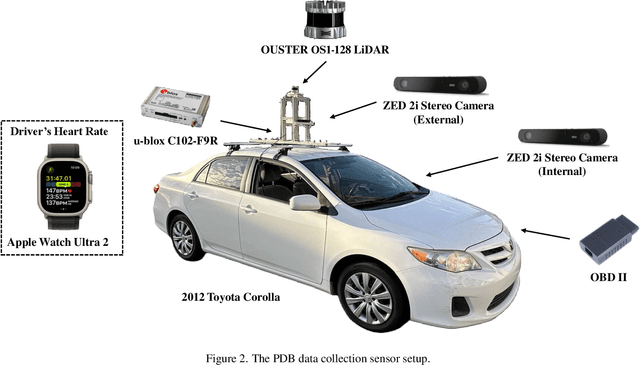
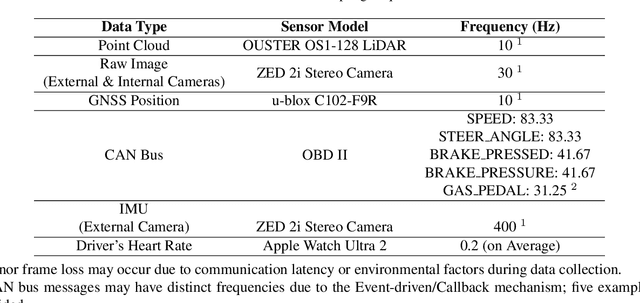
Driving behavior is inherently personal, influenced by individual habits, decision-making styles, and physiological states. However, most existing datasets treat all drivers as homogeneous, overlooking driver-specific variability. To address this gap, we introduce the Personalized Driving Behavior (PDB) dataset, a multi-modal dataset designed to capture personalization in driving behavior under naturalistic driving conditions. Unlike conventional datasets, PDB minimizes external influences by maintaining consistent routes, vehicles, and lighting conditions across sessions. It includes sources from 128-line LiDAR, front-facing camera video, GNSS, 9-axis IMU, CAN bus data (throttle, brake, steering angle), and driver-specific signals such as facial video and heart rate. The dataset features 12 participants, approximately 270,000 LiDAR frames, 1.6 million images, and 6.6 TB of raw sensor data. The processed trajectory dataset consists of 1,669 segments, each spanning 10 seconds with a 0.2-second interval. By explicitly capturing drivers' behavior, PDB serves as a unique resource for human factor analysis, driver identification, and personalized mobility applications, contributing to the development of human-centric intelligent transportation systems.
Graph Edge Representation via Tensor Product Graph Convolutional Representation
Jun 21, 2024


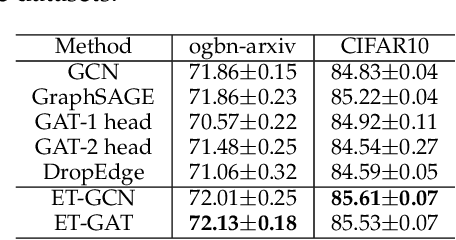
Graph Convolutional Networks (GCNs) have been widely studied. The core of GCNs is the definition of convolution operators on graphs. However, existing Graph Convolution (GC) operators are mainly defined on adjacency matrix and node features and generally focus on obtaining effective node embeddings which cannot be utilized to address the graphs with (high-dimensional) edge features. To address this problem, by leveraging tensor contraction representation and tensor product graph diffusion theories, this paper analogously defines an effective convolution operator on graphs with edge features which is named as Tensor Product Graph Convolution (TPGC). The proposed TPGC aims to obtain effective edge embeddings. It provides a complementary model to traditional graph convolutions (GCs) to address the more general graph data analysis with both node and edge features. Experimental results on several graph learning tasks demonstrate the effectiveness of the proposed TPGC.
A Unified Graph Selective Prompt Learning for Graph Neural Networks
Jun 15, 2024In recent years, graph prompt learning/tuning has garnered increasing attention in adapting pre-trained models for graph representation learning. As a kind of universal graph prompt learning method, Graph Prompt Feature (GPF) has achieved remarkable success in adapting pre-trained models for Graph Neural Networks (GNNs). By fixing the parameters of a pre-trained GNN model, the aim of GPF is to modify the input graph data by adding some (learnable) prompt vectors into graph node features to better align with the downstream tasks on the smaller dataset. However, existing GPFs generally suffer from two main limitations. First, GPFs generally focus on node prompt learning which ignore the prompting for graph edges. Second, existing GPFs generally conduct the prompt learning on all nodes equally which fails to capture the importances of different nodes and may perform sensitively w.r.t noisy nodes in aligning with the downstream tasks. To address these issues, in this paper, we propose a new unified Graph Selective Prompt Feature learning (GSPF) for GNN fine-tuning. The proposed GSPF integrates the prompt learning on both graph node and edge together, which thus provides a unified prompt model for the graph data. Moreover, it conducts prompt learning selectively on nodes and edges by concentrating on the important nodes and edges for prompting which thus make our model be more reliable and compact. Experimental results on many benchmark datasets demonstrate the effectiveness and advantages of the proposed GSPF method.