 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild
Apr 27, 2022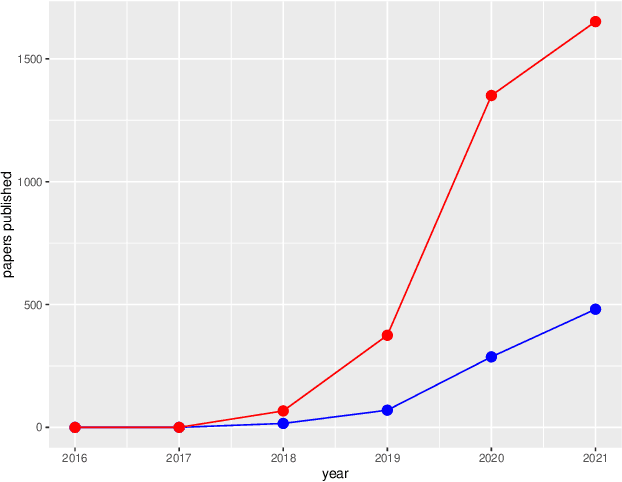
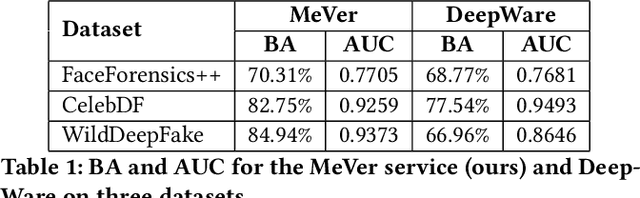
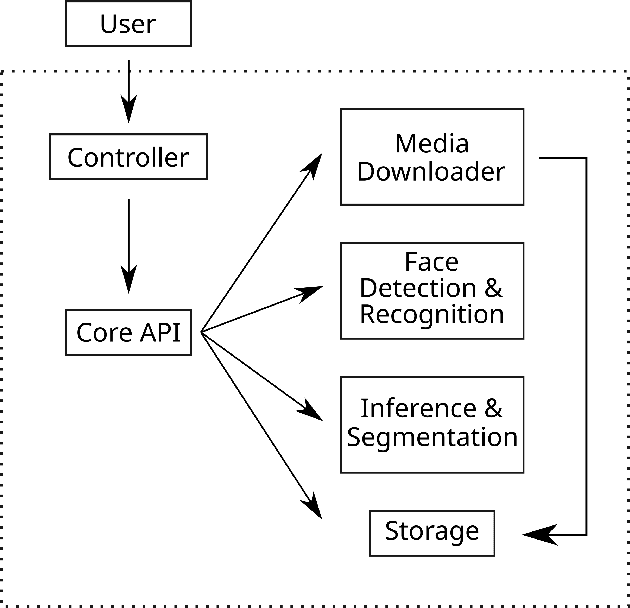
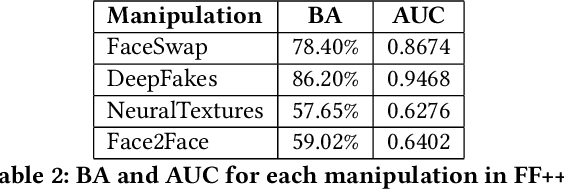
Enabled by recent improvements in generation methodologies, DeepFakes have become mainstream due to their increasingly better visual quality, the increase in easy-to-use generation tools and the rapid dissemination through social media. This fact poses a severe threat to our societies with the potential to erode social cohesion and influence our democracies. To mitigate the threat, numerous DeepFake detection schemes have been introduced in the literature but very few provide a web service that can be used in the wild. In this paper, we introduce the MeVer DeepFake detection service, a web service detecting deep learning manipulations in images and video. We present the design and implementation of the proposed processing pipeline that involves a model ensemble scheme, and we endow the service with a model card for transparency. Experimental results show that our service performs robustly on the three benchmark datasets while being vulnerable to Adversarial Attacks. Finally, we outline our experience and lessons learned when deploying a research system into production in the hopes that it will be useful to other academic and industry teams.
The Devil is in the GAN: Defending Deep Generative Models Against Backdoor Attacks
Aug 03, 2021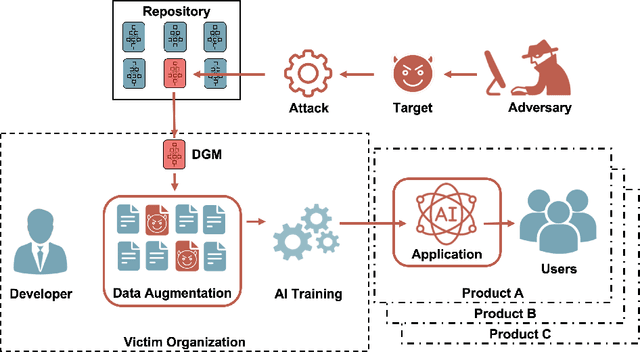
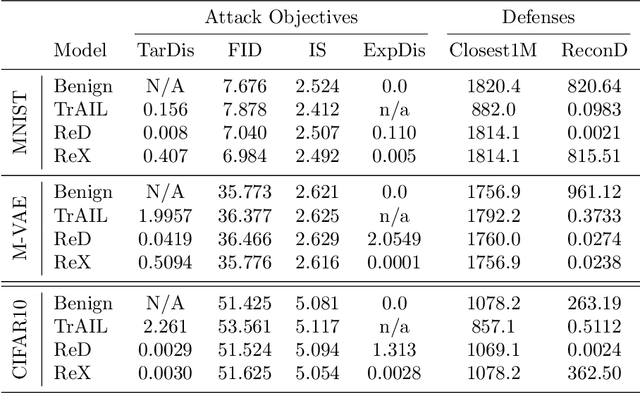
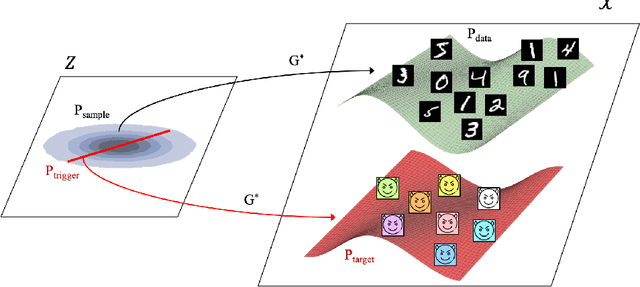
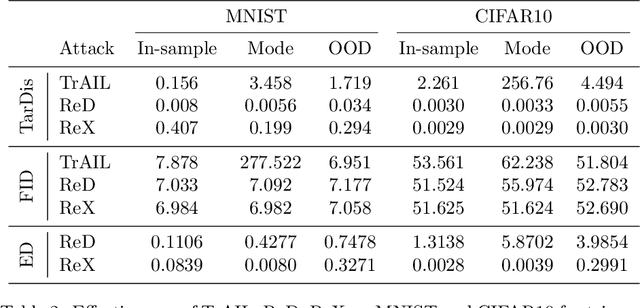
Deep Generative Models (DGMs) allow users to synthesize data from complex, high-dimensional manifolds. Industry applications of DGMs include data augmentation to boost performance of (semi-)supervised machine learning, or to mitigate fairness or privacy concerns. Large-scale DGMs are notoriously hard to train, requiring expert skills, large amounts of data and extensive computational resources. Thus, it can be expected that many enterprises will resort to sourcing pre-trained DGMs from potentially unverified third parties, e.g.~open source model repositories. As we show in this paper, such a deployment scenario poses a new attack surface, which allows adversaries to potentially undermine the integrity of entire machine learning development pipelines in a victim organization. Specifically, we describe novel training-time attacks resulting in corrupted DGMs that synthesize regular data under normal operations and designated target outputs for inputs sampled from a trigger distribution. Depending on the control that the adversary has over the random number generation, this imposes various degrees of risk that harmful data may enter the machine learning development pipelines, potentially causing material or reputational damage to the victim organization. Our attacks are based on adversarial loss functions that combine the dual objectives of attack stealth and fidelity. We show its effectiveness for a variety of DGM architectures (Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs)) and data domains (images, audio). Our experiments show that - even for large-scale industry-grade DGMs - our attack can be mounted with only modest computational efforts. We also investigate the effectiveness of different defensive approaches (based on static/dynamic model and output inspections) and prescribe a practical defense strategy that paves the way for safe usage of DGMs.
Diffprivlib: The IBM Differential Privacy Library
Jul 04, 2019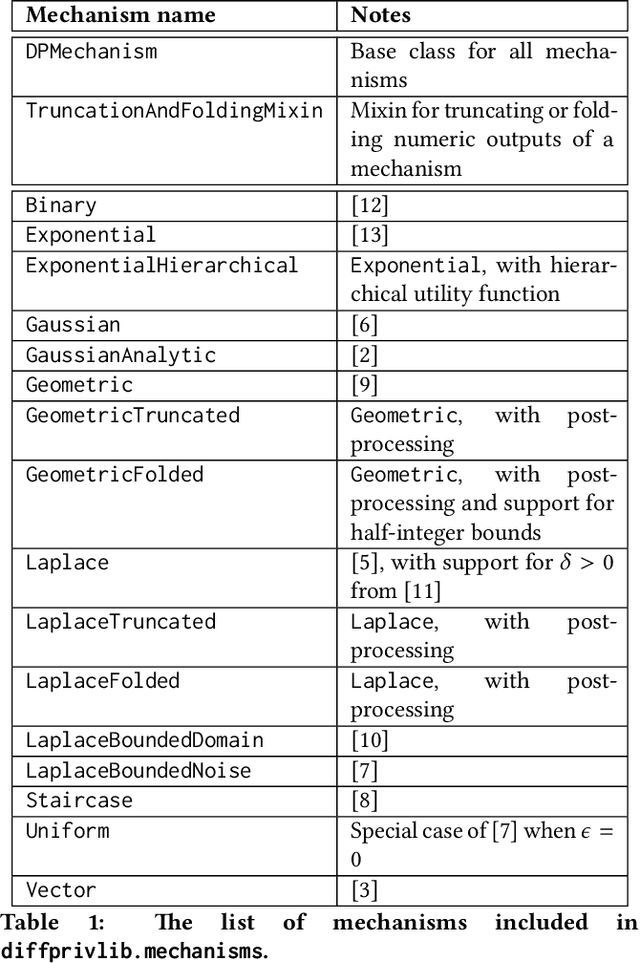
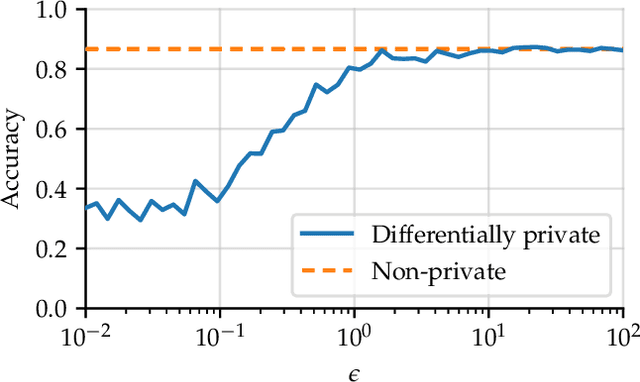
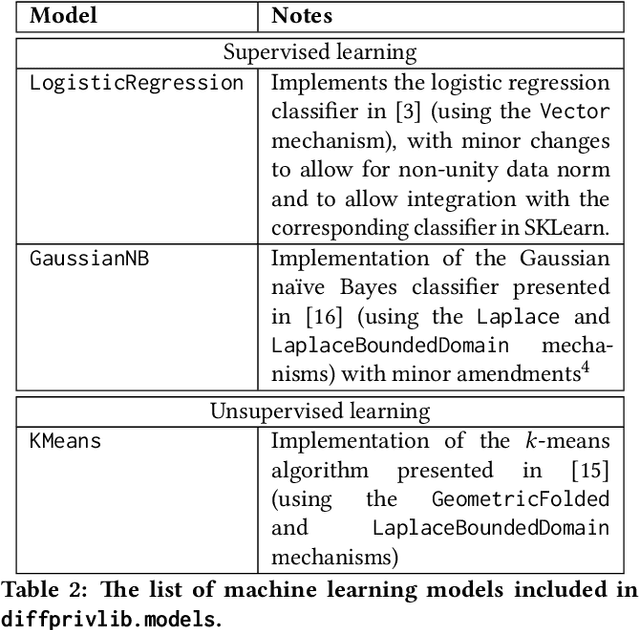
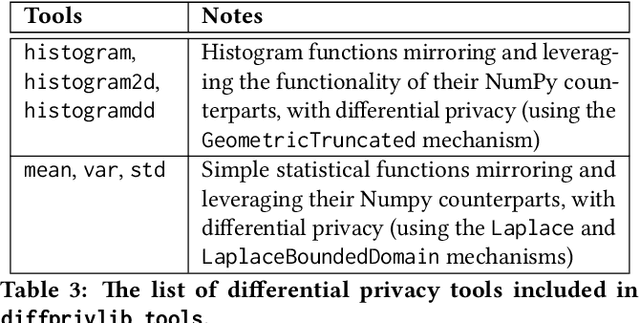
Since its conception in 2006, differential privacy has emerged as the de-facto standard in data privacy, owing to its robust mathematical guarantees, generalised applicability and rich body of literature. Over the years, researchers have studied differential privacy and its applicability to an ever-widening field of topics. Mechanisms have been created to optimise the process of achieving differential privacy, for various data types and scenarios. Until this work however, all previous work on differential privacy has been conducted on a ad-hoc basis, without a single, unifying codebase to implement results. In this work, we present the IBM Differential Privacy Library, a general purpose, open source library for investigating, experimenting and developing differential privacy applications in the Python programming language. The library includes a host of mechanisms, the building blocks of differential privacy, alongside a number of applications to machine learning and other data analytics tasks. Simplicity and accessibility has been prioritised in developing the library, making it suitable to a wide audience of users, from those using the library for their first investigations in data privacy, to the privacy experts looking to contribute their own models and mechanisms for others to use.
OntoSeg: a Novel Approach to Text Segmentation using Ontological Similarity
Nov 26, 2015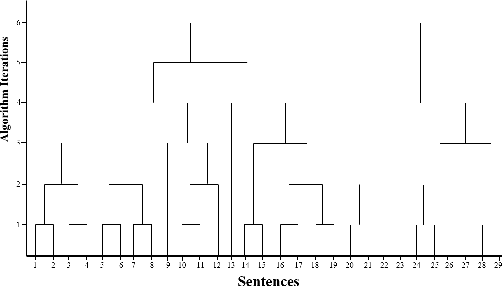
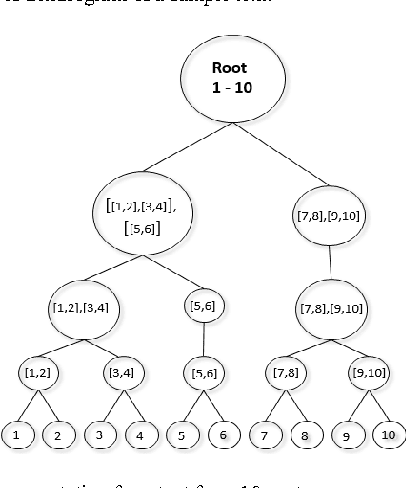

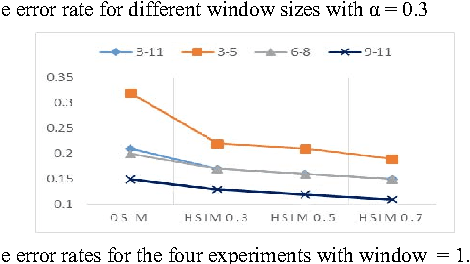
Text segmentation (TS) aims at dividing long text into coherent segments which reflect the subtopic structure of the text. It is beneficial to many natural language processing tasks, such as Information Retrieval (IR) and document summarisation. Current approaches to text segmentation are similar in that they all use word-frequency metrics to measure the similarity between two regions of text, so that a document is segmented based on the lexical cohesion between its words. Various NLP tasks are now moving towards the semantic web and ontologies, such as ontology-based IR systems, to capture the conceptualizations associated with user needs and contents. Text segmentation based on lexical cohesion between words is hence not sufficient anymore for such tasks. This paper proposes OntoSeg, a novel approach to text segmentation based on the ontological similarity between text blocks. The proposed method uses ontological similarity to explore conceptual relations between text segments and a Hierarchical Agglomerative Clustering (HAC) algorithm to represent the text as a tree-like hierarchy that is conceptually structured. The rich structure of the created tree further allows the segmentation of text in a linear fashion at various levels of granularity. The proposed method was evaluated on a wellknown dataset, and the results show that using ontological similarity in text segmentation is very promising. Also we enhance the proposed method by combining ontological similarity with lexical similarity and the results show an enhancement of the segmentation quality.