 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Prior Lock-in: Why In-Context Learning Fails for Structured Data
Jun 10, 2026Large language models (LLMs) are increasingly used as conditional generators for structured data, relying on in-context learning (ICL) to adapt to new distributions without parameter updates. We investigate the limits of ICL for structured generation under distribution mismatch, using high-cardinality tabular data as a controlled test case, and identify a structural failure mode we term \textit{categorical prior lock-in}: the inability of ICL to update the model's prior over token distributions inherited from pre-training. Across two 7B-parameter open-weight models, ICL improves numerical fidelity with additional examples but exhibits a sharp ceiling on categorical distributions, failing to reproduce rare classes entirely. Parameter-efficient fine-tuning (LoRA) overcomes these limitations but introduces measurable memorization risk and, in some cases, destabilizes structured output generation, highlighting a fundamental trade-off between adaptability and privacy.
PrivFusion: A Privacy-preserving Multi-Agent Framework for Harmonizing Distributed Datasets
May 22, 2026The growing availability of clinical data has increased the use of machine learning, yet centralized data aggregation is often infeasible for sensitive health information. Federated Learning (FL) offers a distributed alternative, but its adoption is limited by substantial heterogeneity across institutional datasets, making harmonization a critical but frequently overlooked prerequisite for multi-site analytics. We introduce PrivFusion, a privacy-preserving multi-agent framework that automates the harmonization of structured datasets prior to federated training. PrivFusion uses agents to analyze local data, cluster semantically similar features across sites, and provide iterative transformation recommendations until alignment is achieved. Evaluation across four heterogeneous COVID-19 datasets demonstrates that PrivFusion effectively and efficiently harmonizes multi-site data while substantially reducing manual effort.
Robust Learning Protocol for Federated Tumor Segmentation Challenge
Dec 16, 2022In this work, we devise robust and efficient learning protocols for orchestrating a Federated Learning (FL) process for the Federated Tumor Segmentation Challenge (FeTS 2022). Enabling FL for FeTS setup is challenging mainly due to data heterogeneity among collaborators and communication cost of training. To tackle these challenges, we propose Robust Learning Protocol (RoLePRO) which is a combination of server-side adaptive optimisation (e.g., server-side Adam) and judicious parameter (weights) aggregation schemes (e.g., adaptive weighted aggregation). RoLePRO takes a two-phase approach, where the first phase consists of vanilla Federated Averaging, while the second phase consists of a judicious aggregation scheme that uses a sophisticated reweighting, all in the presence of an adaptive optimisation algorithm at the server. We draw insights from extensive experimentation to tune learning rates for the two phases.
Diffprivlib: The IBM Differential Privacy Library
Jul 04, 2019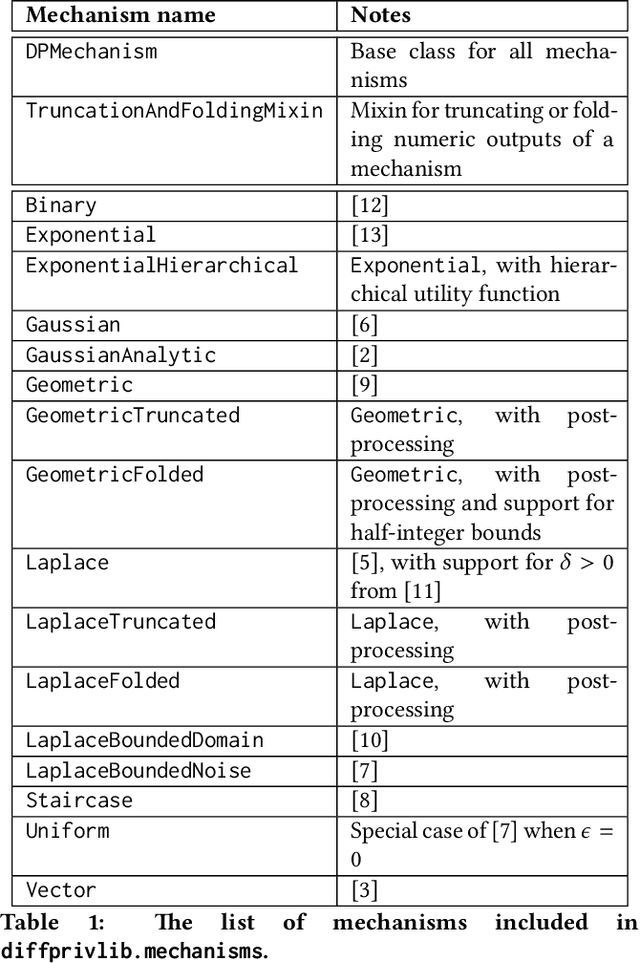
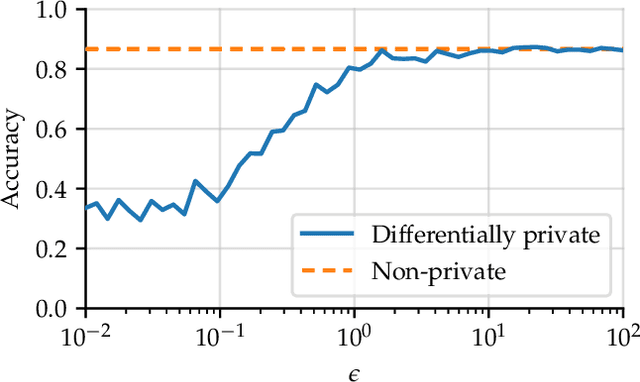
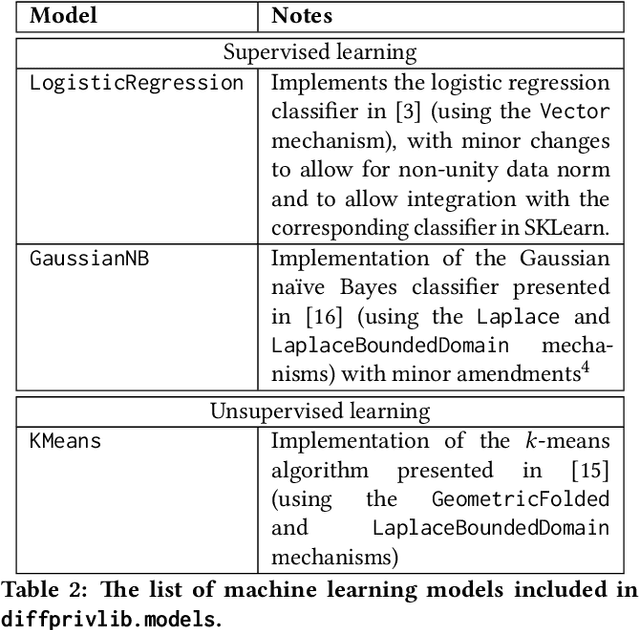
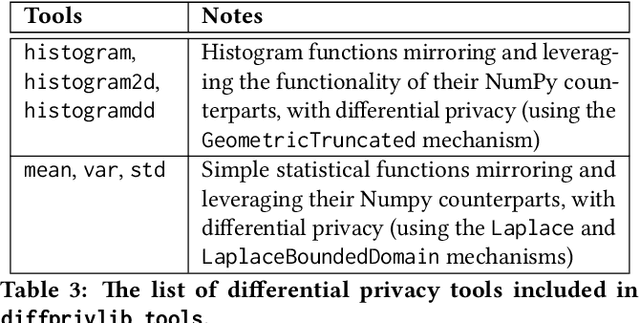
Since its conception in 2006, differential privacy has emerged as the de-facto standard in data privacy, owing to its robust mathematical guarantees, generalised applicability and rich body of literature. Over the years, researchers have studied differential privacy and its applicability to an ever-widening field of topics. Mechanisms have been created to optimise the process of achieving differential privacy, for various data types and scenarios. Until this work however, all previous work on differential privacy has been conducted on a ad-hoc basis, without a single, unifying codebase to implement results. In this work, we present the IBM Differential Privacy Library, a general purpose, open source library for investigating, experimenting and developing differential privacy applications in the Python programming language. The library includes a host of mechanisms, the building blocks of differential privacy, alongside a number of applications to machine learning and other data analytics tasks. Simplicity and accessibility has been prioritised in developing the library, making it suitable to a wide audience of users, from those using the library for their first investigations in data privacy, to the privacy experts looking to contribute their own models and mechanisms for others to use.
Predicting User Engagement in Twitter with Collaborative Ranking
Dec 26, 2014
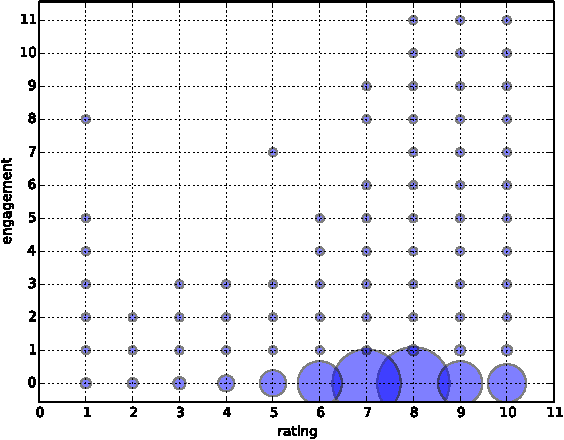

Collaborative Filtering (CF) is a core component of popular web-based services such as Amazon, YouTube, Netflix, and Twitter. Most applications use CF to recommend a small set of items to the user. For instance, YouTube presents to a user a list of top-n videos she would likely watch next based on her rating and viewing history. Current methods of CF evaluation have been focused on assessing the quality of a predicted rating or the ranking performance for top-n recommended items. However, restricting the recommender system evaluation to these two aspects is rather limiting and neglects other dimensions that could better characterize a well-perceived recommendation. In this paper, instead of optimizing rating or top-n recommendation, we focus on the task of predicting which items generate the highest user engagement. In particular, we use Twitter as our testbed and cast the problem as a Collaborative Ranking task where the rich features extracted from the metadata of the tweets help to complement the transaction information limited to user ids, item ids, ratings and timestamps. We learn a scoring function that directly optimizes the user engagement in terms of nDCG@10 on the predicted ranking. Experiments conducted on an extended version of the MovieTweetings dataset, released as part of the RecSys Challenge 2014, show the effectiveness of our approach.
* RecSysChallenge'14 at RecSys 2014, October 10, 2014, Foster City, CA, USA