 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Approach to Personalize Type-based Facet Ranking for POI Suggestion
May 10, 2021


Faceted Search Systems (FSS) have become one of the main search interfaces used in vertical search systems, offering users meaningful facets to refine their search query and narrow down the results quickly to find the intended search target. This work focuses on the problem of ranking type-based facets. In a structured information space, type-based facets (t-facets) indicate the category to which each object belongs. When they belong to a large multi-level taxonomy, it is desirable to rank them separately before ranking other facet groups. This helps the searcher in filtering the results according to their type first. This also makes it easier to rank the rest of the facets once the type of the intended search target is selected. Existing research employs the same ranking methods for different facet groups. In this research, we propose a two-step approach to personalize t-facet ranking. The first step assigns a relevance score to each individual leaf-node t-facet. The score is generated using probabilistic models and it reflects t-facet relevance to the query and the user profile. In the second step, this score is used to re-order and select the sub-tree to present to the user. We investigate the usefulness of the proposed method to a Point Of Interest (POI) suggestion task. Our evaluation aims at capturing the user effort required to fulfil her search needs by using the ranked facets. The proposed approach achieved better results than other existing personalized baselines.
OntoSeg: a Novel Approach to Text Segmentation using Ontological Similarity
Nov 26, 2015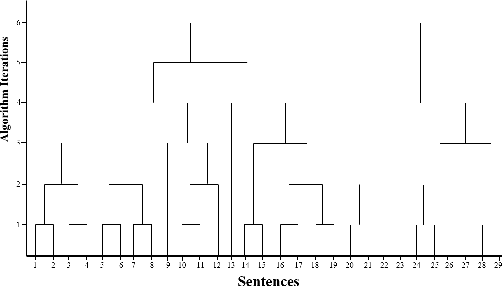
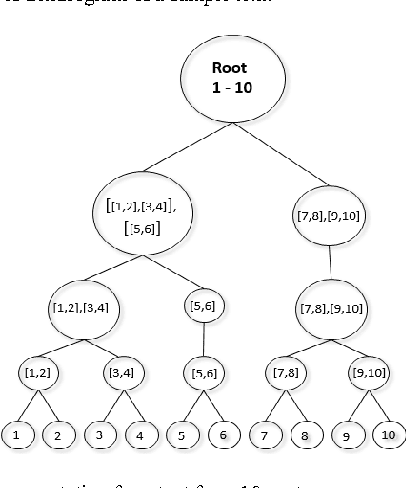

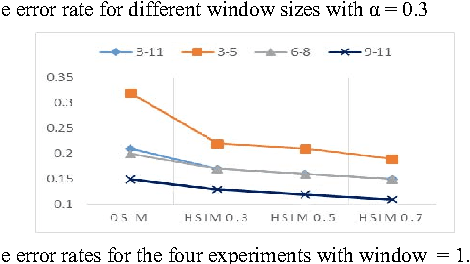
Text segmentation (TS) aims at dividing long text into coherent segments which reflect the subtopic structure of the text. It is beneficial to many natural language processing tasks, such as Information Retrieval (IR) and document summarisation. Current approaches to text segmentation are similar in that they all use word-frequency metrics to measure the similarity between two regions of text, so that a document is segmented based on the lexical cohesion between its words. Various NLP tasks are now moving towards the semantic web and ontologies, such as ontology-based IR systems, to capture the conceptualizations associated with user needs and contents. Text segmentation based on lexical cohesion between words is hence not sufficient anymore for such tasks. This paper proposes OntoSeg, a novel approach to text segmentation based on the ontological similarity between text blocks. The proposed method uses ontological similarity to explore conceptual relations between text segments and a Hierarchical Agglomerative Clustering (HAC) algorithm to represent the text as a tree-like hierarchy that is conceptually structured. The rich structure of the created tree further allows the segmentation of text in a linear fashion at various levels of granularity. The proposed method was evaluated on a wellknown dataset, and the results show that using ontological similarity in text segmentation is very promising. Also we enhance the proposed method by combining ontological similarity with lexical similarity and the results show an enhancement of the segmentation quality.