 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Early-Onset Colorectal Cancer with Large Language Models
Jun 13, 2025The incidence rate of early-onset colorectal cancer (EoCRC, age < 45) has increased every year, but this population is younger than the recommended age established by national guidelines for cancer screening. In this paper, we applied 10 different machine learning models to predict EoCRC, and compared their performance with advanced large language models (LLM), using patient conditions, lab results, and observations within 6 months of patient journey prior to the CRC diagnoses. We retrospectively identified 1,953 CRC patients from multiple health systems across the United States. The results demonstrated that the fine-tuned LLM achieved an average of 73% sensitivity and 91% specificity.
Mask-conditioned latent diffusion for generating gastrointestinal polyp images
Apr 11, 2023



In order to take advantage of AI solutions in endoscopy diagnostics, we must overcome the issue of limited annotations. These limitations are caused by the high privacy concerns in the medical field and the requirement of getting aid from experts for the time-consuming and costly medical data annotation process. In computer vision, image synthesis has made a significant contribution in recent years as a result of the progress of generative adversarial networks (GANs) and diffusion probabilistic models (DPM). Novel DPMs have outperformed GANs in text, image, and video generation tasks. Therefore, this study proposes a conditional DPM framework to generate synthetic GI polyp images conditioned on given generated segmentation masks. Our experimental results show that our system can generate an unlimited number of high-fidelity synthetic polyp images with the corresponding ground truth masks of polyps. To test the usefulness of the generated data, we trained binary image segmentation models to study the effect of using synthetic data. Results show that the best micro-imagewise IOU of 0.7751 was achieved from DeepLabv3+ when the training data consists of both real data and synthetic data. However, the results reflect that achieving good segmentation performance with synthetic data heavily depends on model architectures.
PolypConnect: Image inpainting for generating realistic gastrointestinal tract images with polyps
May 30, 2022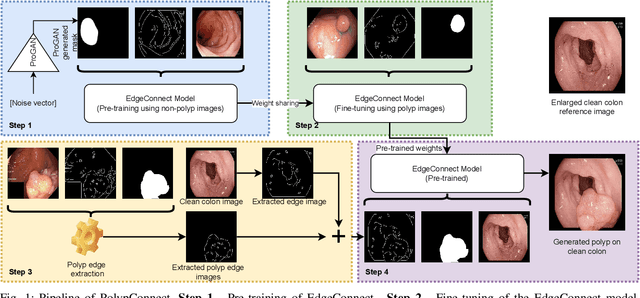

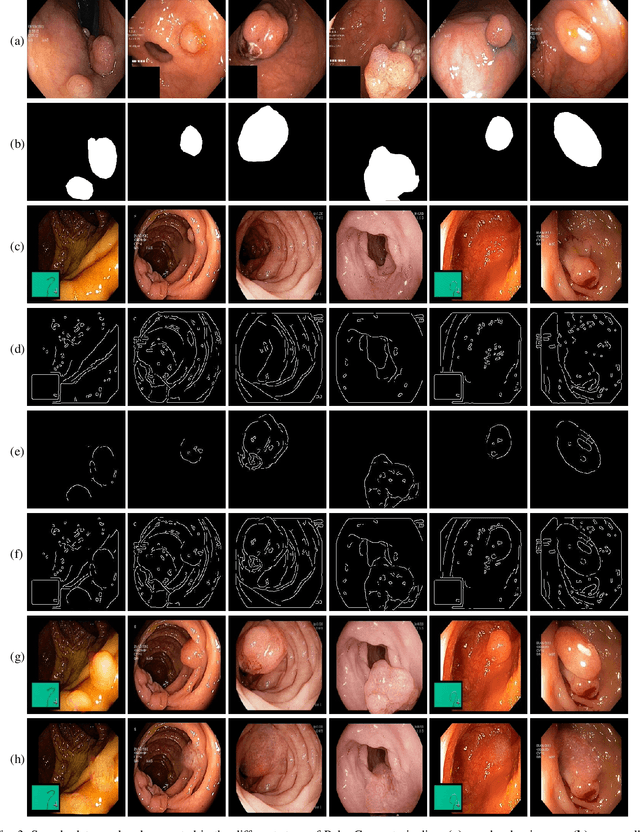

Early identification of a polyp in the lower gastrointestinal (GI) tract can lead to prevention of life-threatening colorectal cancer. Developing computer-aided diagnosis (CAD) systems to detect polyps can improve detection accuracy and efficiency and save the time of the domain experts called endoscopists. Lack of annotated data is a common challenge when building CAD systems. Generating synthetic medical data is an active research area to overcome the problem of having relatively few true positive cases in the medical domain. To be able to efficiently train machine learning (ML) models, which are the core of CAD systems, a considerable amount of data should be used. In this respect, we propose the PolypConnect pipeline, which can convert non-polyp images into polyp images to increase the size of training datasets for training. We present the whole pipeline with quantitative and qualitative evaluations involving endoscopists. The polyp segmentation model trained using synthetic data, and real data shows a 5.1% improvement of mean intersection over union (mIOU), compared to the model trained only using real data. The codes of all the experiments are available on GitHub to reproduce the results.
Visual explanations for polyp detection: How medical doctors assess intrinsic versus extrinsic explanations
Mar 23, 2022
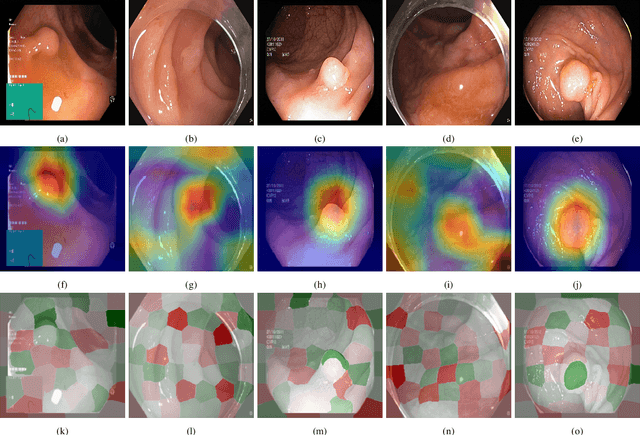

Deep learning has in recent years achieved immense success in all areas of computer vision and has the potential of assisting medical doctors in analyzing visual content for disease and other abnormalities. However, the current state of deep learning is very much a black box, making medical professionals highly skeptical about integrating these methods into clinical practice. Several methods have been proposed in order to shine some light onto these black boxes, but there is no consensus on the opinion of the medical doctors that will consume these explanations. This paper presents a study asking medical doctors about their opinion of current state-of-the-art explainable artificial intelligence methods when applied to a gastrointestinal disease detection use case. We compare two different categories of explanation methods, intrinsic and extrinsic, and gauge their opinion of the current value of these explanations. The results indicate that intrinsic explanations are preferred and that explanation.
Literature-Augmented Clinical Outcome Prediction
Nov 16, 2021

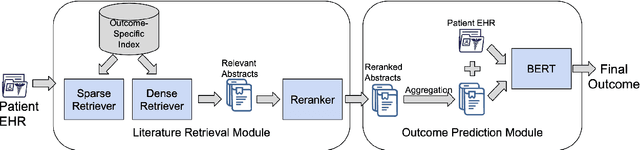

Predictive models for medical outcomes hold great promise for enhancing clinical decision-making. These models are trained on rich patient data such as clinical notes, aggregating many patient signals into an outcome prediction. However, AI-based clinical models have typically been developed in isolation from the prominent paradigm of Evidence Based Medicine (EBM), in which medical decisions are based on explicit evidence from existing literature. In this work, we introduce techniques to help bridge this gap between EBM and AI-based clinical models, and show that these methods can improve predictive accuracy. We propose a novel system that automatically retrieves patient-specific literature based on intensive care (ICU) patient information, aggregates relevant papers and fuses them with internal admission notes to form outcome predictions. Our model is able to substantially boost predictive accuracy on three challenging tasks in comparison to strong recent baselines; for in-hospital mortality, we are able to boost top-10% precision by a large margin of over 25%.
A Search Engine for Discovery of Scientific Challenges and Directions
Sep 10, 2021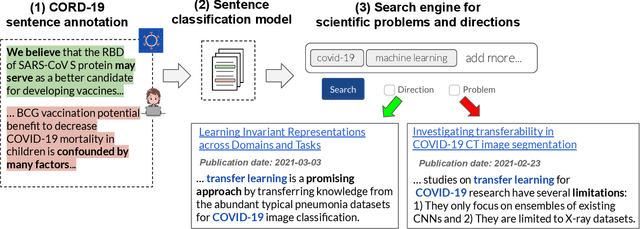


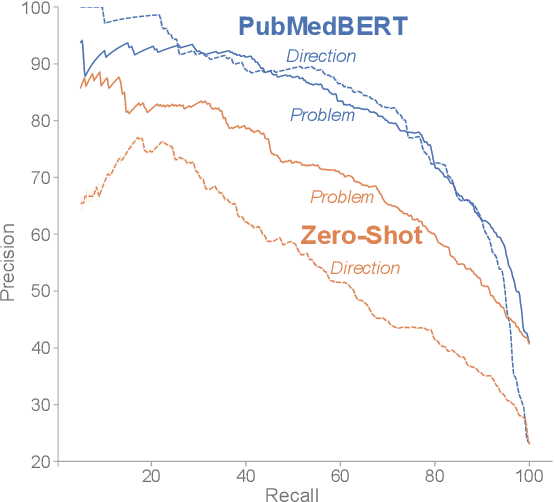
Keeping track of scientific challenges, advances and emerging directions is a fundamental part of research. However, researchers face a flood of papers that hinders discovery of important knowledge. In biomedicine, this directly impacts human lives. To address this problem, we present a novel task of extraction and search of scientific challenges and directions, to facilitate rapid knowledge discovery. We construct and release an expert-annotated corpus of texts sampled from full-length papers, labeled with novel semantic categories that generalize across many types of challenges and directions. We focus on a large corpus of interdisciplinary work relating to the COVID-19 pandemic, ranging from biomedicine to areas such as AI and economics. We apply a model trained on our data to identify challenges and directions across the corpus and build a dedicated search engine. In experiments with 19 researchers and clinicians using our system, we outperform a popular scientific search engine in assisting knowledge discovery. Finally, we show that models trained on our resource generalize to the wider biomedical domain and to AI papers, highlighting its broad utility. We make our data, model and search engine publicly available. https://challenges.apps.allenai.org/
SinGAN-Seg: Synthetic Training Data Generation for Medical Image Segmentation
Jun 29, 2021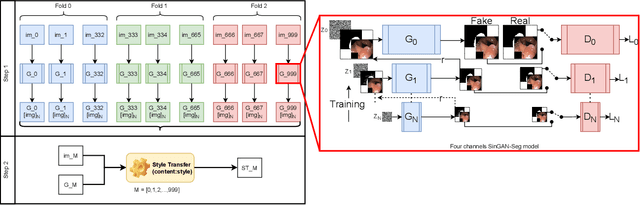
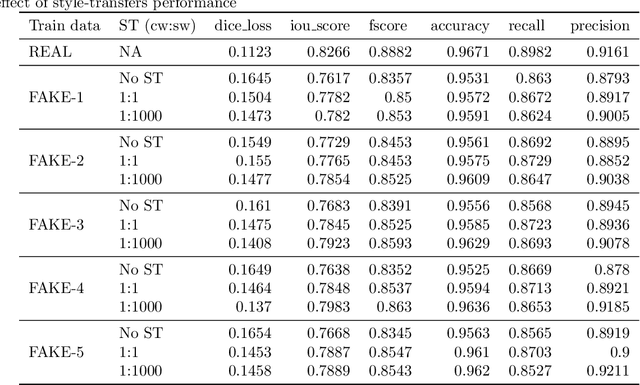
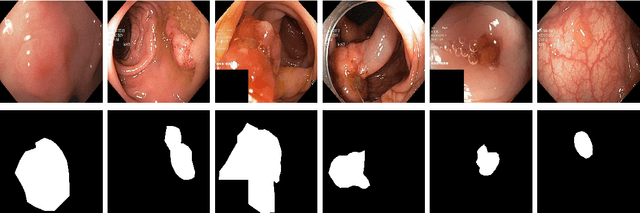
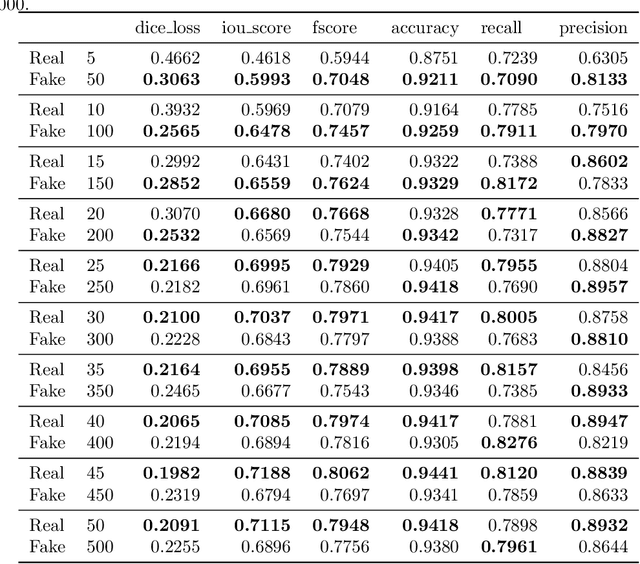
Processing medical data to find abnormalities is a time-consuming and costly task, requiring tremendous efforts from medical experts. Therefore, Ai has become a popular tool for the automatic processing of medical data, acting as a supportive tool for doctors. AI tools highly depend on data for training the models. However, there are several constraints to access to large amounts of medical data to train machine learning algorithms in the medical domain, e.g., due to privacy concerns and the costly, time-consuming medical data annotation process. To address this, in this paper we present a novel synthetic data generation pipeline called SinGAN-Seg to produce synthetic medical data with the corresponding annotated ground truth masks. We show that these synthetic data generation pipelines can be used as an alternative to bypass privacy concerns and as an alternative way to produce artificial segmentation datasets with corresponding ground truth masks to avoid the tedious medical data annotation process. As a proof of concept, we used an open polyp segmentation dataset. By training UNet++ using both the real polyp segmentation dataset and the corresponding synthetic dataset generated from the SinGAN-Seg pipeline, we show that the synthetic data can achieve a very close performance to the real data when the real segmentation datasets are large enough. In addition, we show that synthetic data generated from the SinGAN-Seg pipeline improving the performance of segmentation algorithms when the training dataset is very small. Since our SinGAN-Seg pipeline is applicable for any medical dataset, this pipeline can be used with any other segmentation datasets.
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020

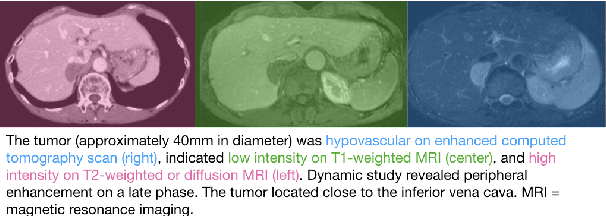
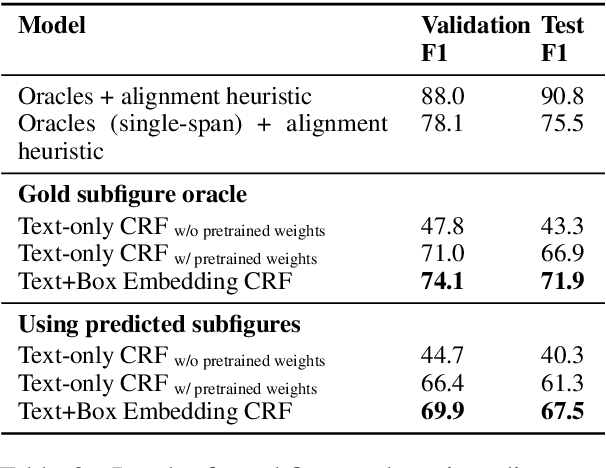
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.