 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Early-Onset Colorectal Cancer with Large Language Models
Jun 13, 2025The incidence rate of early-onset colorectal cancer (EoCRC, age < 45) has increased every year, but this population is younger than the recommended age established by national guidelines for cancer screening. In this paper, we applied 10 different machine learning models to predict EoCRC, and compared their performance with advanced large language models (LLM), using patient conditions, lab results, and observations within 6 months of patient journey prior to the CRC diagnoses. We retrospectively identified 1,953 CRC patients from multiple health systems across the United States. The results demonstrated that the fine-tuned LLM achieved an average of 73% sensitivity and 91% specificity.
Event-based clinical findings extraction from radiology reports with pre-trained language model
Dec 27, 2021


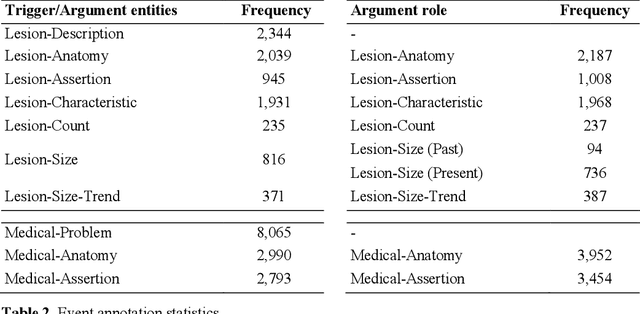
Radiology reports contain a diverse and rich set of clinical abnormalities documented by radiologists during their interpretation of the images. Comprehensive semantic representations of radiological findings would enable a wide range of secondary use applications to support diagnosis, triage, outcomes prediction, and clinical research. In this paper, we present a new corpus of radiology reports annotated with clinical findings. Our annotation schema captures detailed representations of pathologic findings that are observable on imaging ("lesions") and other types of clinical problems ("medical problems"). The schema used an event-based representation to capture fine-grained details, including assertion, anatomy, characteristics, size, count, etc. Our gold standard corpus contained a total of 500 annotated computed tomography (CT) reports. We extracted triggers and argument entities using two state-of-the-art deep learning architectures, including BERT. We then predicted the linkages between trigger and argument entities (referred to as argument roles) using a BERT-based relation extraction model. We achieved the best extraction performance using a BERT model pre-trained on 3 million radiology reports from our institution: 90.9%-93.4% F1 for finding triggers 72.0%-85.6% F1 for arguments roles. To assess model generalizability, we used an external validation set randomly sampled from the MIMIC Chest X-ray (MIMIC-CXR) database. The extraction performance on this validation set was 95.6% for finding triggers and 79.1%-89.7% for argument roles, demonstrating that the model generalized well to the cross-institutional data with a different imaging modality. We extracted the finding events from all the radiology reports in the MIMIC-CXR database and provided the extractions to the research community.
Automatic Assignment of Radiology Examination Protocols Using Pre-trained Language Models with Knowledge Distillation
Sep 01, 2020



Selecting radiology examination protocol is a repetitive, error-prone, and time-consuming process. In this paper, we present a deep learning approach to automatically assign protocols to computer tomography examinations, by pre-training a domain-specific BERT model ($BERT_{rad}$). To handle the high data imbalance across exam protocols, we used a knowledge distillation approach that up-sampled the minority classes through data augmentation. We compared classification performance of the described approach with the statistical n-gram models using Support Vector Machine (SVM) and Random Forest (RF) classifiers, as well as the Google's $BERT_{base}$ model. SVM and RF achieved macro-averaged F1 scores of 0.45 and 0.6 while $BERT_{base}$ and $BERT_{rad}$ achieved 0.61 and 0.63. Knowledge distillation improved overall performance on the minority classes, achieving a F1 score of 0.66. Additionally, by choosing the optimal threshold, the BERT models could classify over 50% of test samples within 5% error rate and potentially alleviate half of radiologist protocoling workload.
UW-BHI at MEDIQA 2019: An Analysis of Representation Methods for Medical Natural Language Inference
Jul 09, 2019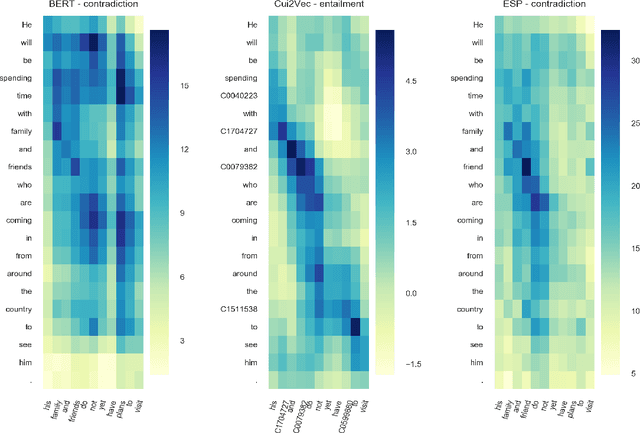
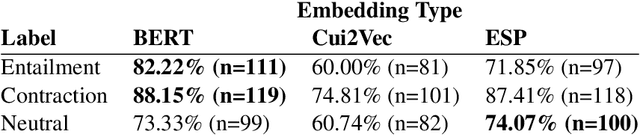
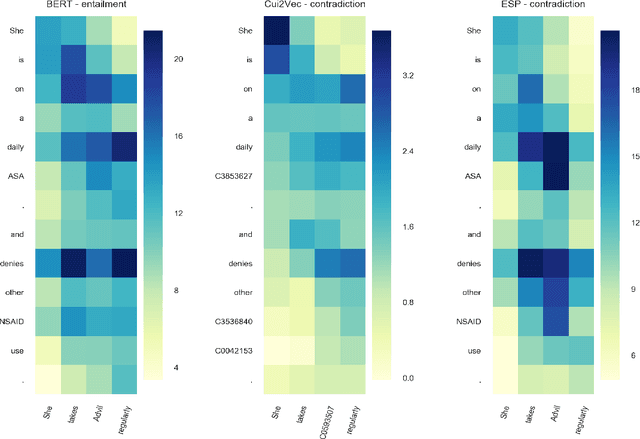

Recent advances in distributed language modeling have led to large performance increases on a variety of natural language processing (NLP) tasks. However, it is not well understood how these methods may be augmented by knowledge-based approaches. This paper compares the performance and internal representation of an Enhanced Sequential Inference Model (ESIM) between three experimental conditions based on the representation method: Bidirectional Encoder Representations from Transformers (BERT), Embeddings of Semantic Predications (ESP), or Cui2Vec. The methods were evaluated on the Medical Natural Language Inference (MedNLI) subtask of the MEDIQA 2019 shared task. This task relied heavily on semantic understanding and thus served as a suitable evaluation set for the comparison of these representation methods.
Extraction and Analysis of Clinically Important Follow-up Recommendations in a Large Radiology Dataset
May 14, 2019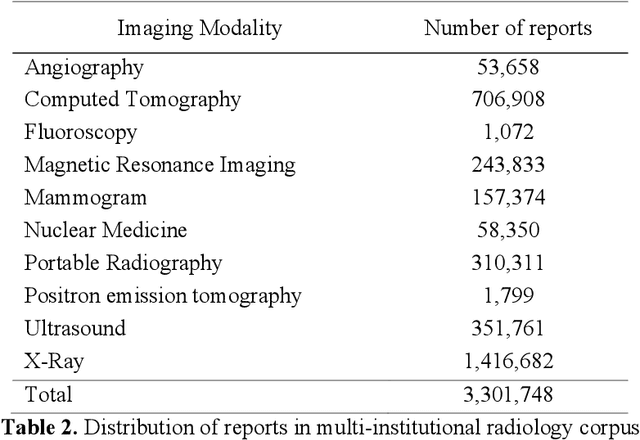



Communication of follow-up recommendations when abnormalities are identified on imaging studies is prone to error. In this paper, we present a natural language processing approach based on deep learning to automatically identify clinically important recommendations in radiology reports. Our approach first identifies the recommendation sentences and then extracts reason, test, and time frame of the identified recommendations. To train our extraction models, we created a corpus of 567 radiology reports annotated for recommendation information. Our extraction models achieved 0.92 f-score for recommendation sentence, 0.65 f-score for reason, 0.73 f-score for test, and 0.84 f-score for time frame. We applied the extraction models to a set of over 3.3 million radiology reports and analyzed the adherence of follow-up recommendations.