 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Flat to Feeling: A Feasibility and Impact Study on Dynamic Facial Emotions in AI-Generated Avatars
Jun 16, 2025
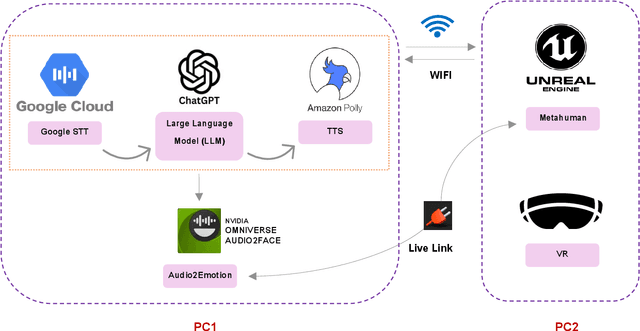

Dynamic facial emotion is essential for believable AI-generated avatars; however, most systems remain visually inert, limiting their utility in high-stakes simulations such as virtual training for investigative interviews with abused children. We introduce and evaluate a real-time architecture fusing Unreal Engine 5 MetaHuman rendering with NVIDIA Omniverse Audio2Face to translate vocal prosody into high-fidelity facial expressions on photorealistic child avatars. We implemented a distributed two-PC setup that decouples language processing and speech synthesis from GPU-intensive rendering, designed to support low-latency interaction in desktop and VR environments. A between-subjects study ($N=70$) using audio+visual and visual-only conditions assessed perceptual impacts as participants rated emotional clarity, facial realism, and empathy for two avatars expressing joy, sadness, and anger. Results demonstrate that avatars could express emotions recognizably, with sadness and joy achieving high identification rates. However, anger recognition significantly dropped without audio, highlighting the importance of congruent vocal cues for high-arousal emotions. Interestingly, removing audio boosted perceived facial realism, suggesting that audiovisual desynchrony remains a key design challenge. These findings confirm the technical feasibility of generating emotionally expressive avatars and provide guidance for improving non-verbal communication in sensitive training simulations.
Comparative Analysis of Audio Feature Extraction for Real-Time Talking Portrait Synthesis
Nov 20, 2024



This paper examines the integration of real-time talking-head generation for interviewer training, focusing on overcoming challenges in Audio Feature Extraction (AFE), which often introduces latency and limits responsiveness in real-time applications. To address these issues, we propose and implement a fully integrated system that replaces conventional AFE models with Open AI's Whisper, leveraging its encoder to optimize processing and improve overall system efficiency. Our evaluation of two open-source real-time models across three different datasets shows that Whisper not only accelerates processing but also improves specific aspects of rendering quality, resulting in more realistic and responsive talking-head interactions. These advancements make the system a more effective tool for immersive, interactive training applications, expanding the potential of AI-driven avatars in interviewer training.
Classifying Dry Eye Disease Patients from Healthy Controls Using Machine Learning and Metabolomics Data
Jun 20, 2024
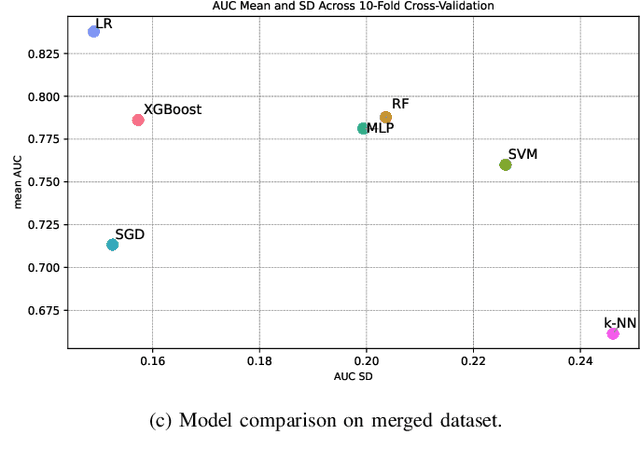
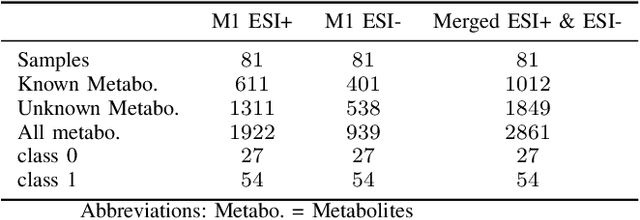

Dry eye disease is a common disorder of the ocular surface, leading patients to seek eye care. Clinical signs and symptoms are currently used to diagnose dry eye disease. Metabolomics, a method for analyzing biological systems, has been found helpful in identifying distinct metabolites in patients and in detecting metabolic profiles that may indicate dry eye disease at early stages. In this study, we explored using machine learning and metabolomics information to identify which cataract patients suffered from dry eye disease. As there is no one-size-fits-all machine learning model for metabolomics data, choosing the most suitable model can significantly affect the quality of predictions and subsequent metabolomics analyses. To address this challenge, we conducted a comparative analysis of nine machine learning models on three metabolomics data sets from cataract patients with and without dry eye disease. The models were evaluated and optimized using nested k-fold cross-validation. To assess the performance of these models, we selected a set of suitable evaluation metrics tailored to the data set's challenges. The logistic regression model overall performed the best, achieving the highest area under the curve score of 0.8378, balanced accuracy of 0.735, Matthew's correlation coefficient of 0.5147, an F1-score of 0.8513, and a specificity of 0.5667. Additionally, following the logistic regression, the XGBoost and Random Forest models also demonstrated good performance.
SinGAN-Seg: Synthetic Training Data Generation for Medical Image Segmentation
Jun 29, 2021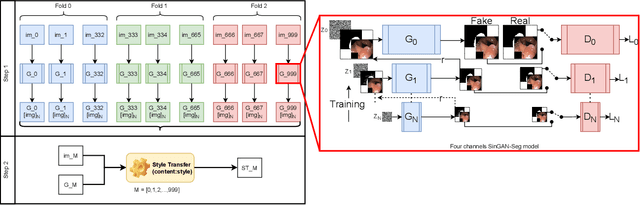
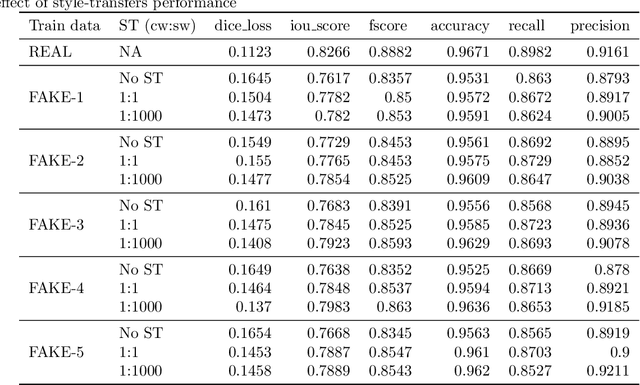
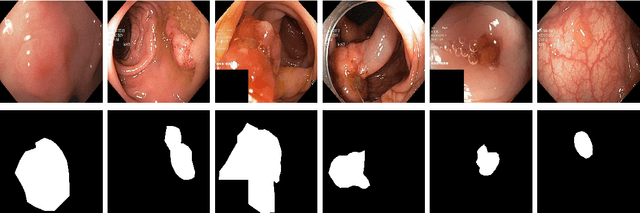
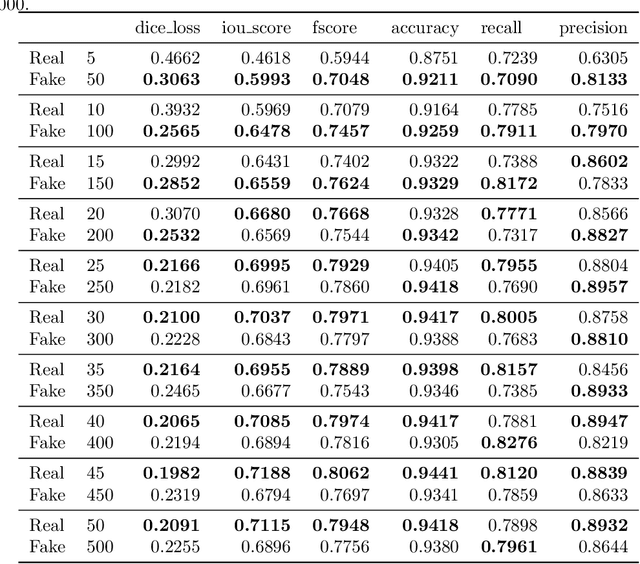
Processing medical data to find abnormalities is a time-consuming and costly task, requiring tremendous efforts from medical experts. Therefore, Ai has become a popular tool for the automatic processing of medical data, acting as a supportive tool for doctors. AI tools highly depend on data for training the models. However, there are several constraints to access to large amounts of medical data to train machine learning algorithms in the medical domain, e.g., due to privacy concerns and the costly, time-consuming medical data annotation process. To address this, in this paper we present a novel synthetic data generation pipeline called SinGAN-Seg to produce synthetic medical data with the corresponding annotated ground truth masks. We show that these synthetic data generation pipelines can be used as an alternative to bypass privacy concerns and as an alternative way to produce artificial segmentation datasets with corresponding ground truth masks to avoid the tedious medical data annotation process. As a proof of concept, we used an open polyp segmentation dataset. By training UNet++ using both the real polyp segmentation dataset and the corresponding synthetic dataset generated from the SinGAN-Seg pipeline, we show that the synthetic data can achieve a very close performance to the real data when the real segmentation datasets are large enough. In addition, we show that synthetic data generated from the SinGAN-Seg pipeline improving the performance of segmentation algorithms when the training dataset is very small. Since our SinGAN-Seg pipeline is applicable for any medical dataset, this pipeline can be used with any other segmentation datasets.
An Improved Person Re-identification Method by light-weight convolutional neural network
Aug 21, 2020
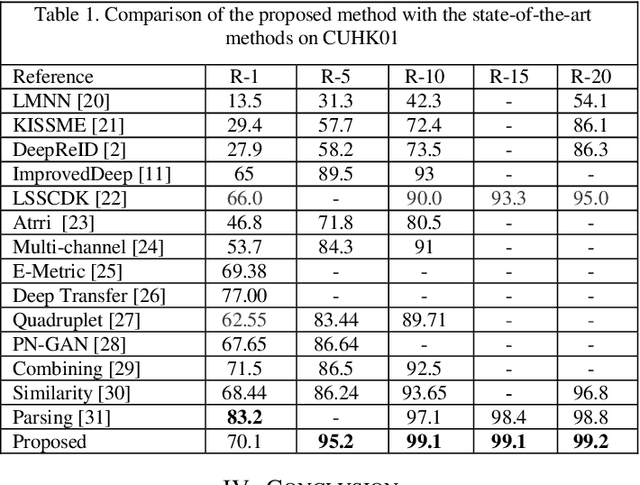
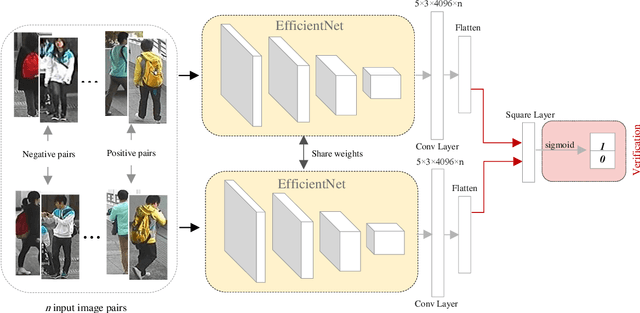
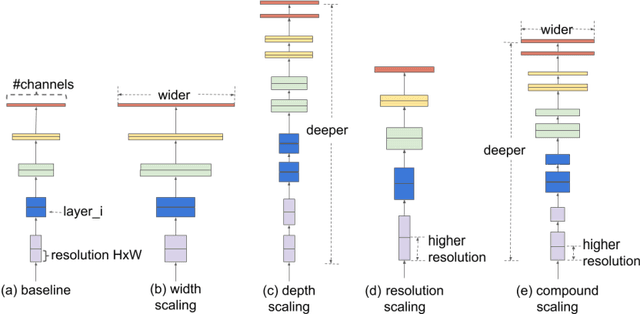
Person Re-identification is defined as a recognizing process where the person is observed by non-overlapping cameras at different places. In the last decade, the rise in the applications and importance of Person Re-identification for surveillance systems popularized this subject in different areas of computer vision. Person Re-identification is faced with challenges such as low resolution, varying poses, illumination, background clutter, and occlusion, which could affect the result of recognizing process. The present paper aims to improve Person Re-identification using transfer learning and application of verification loss function within the framework of Siamese network. The Siamese network receives image pairs as inputs and extract their features via a pre-trained model. EfficientNet was employed to obtain discriminative features and reduce the demands for data. The advantages of verification loss were used in the network learning. Experiments showed that the proposed model performs better than state-of-the-art methods on the CUHK01 dataset. For example, rank5 accuracies are 95.2% (+5.7) for the CUHK01 datasets. It also achieved an acceptable percentage in Rank 1. Because of the small size of the pre-trained model parameters, learning speeds up and there will be a need for less hardware and data.