 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Classifying Dry Eye Disease Patients from Healthy Controls Using Machine Learning and Metabolomics Data
Jun 20, 2024
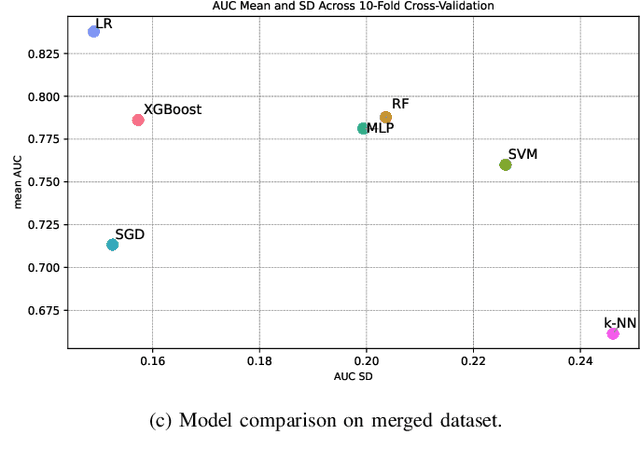
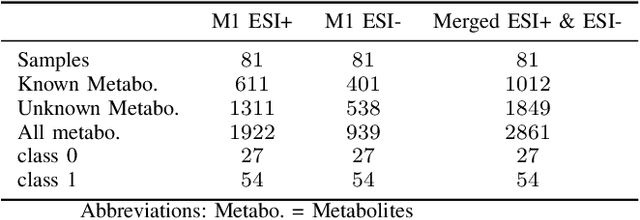

Dry eye disease is a common disorder of the ocular surface, leading patients to seek eye care. Clinical signs and symptoms are currently used to diagnose dry eye disease. Metabolomics, a method for analyzing biological systems, has been found helpful in identifying distinct metabolites in patients and in detecting metabolic profiles that may indicate dry eye disease at early stages. In this study, we explored using machine learning and metabolomics information to identify which cataract patients suffered from dry eye disease. As there is no one-size-fits-all machine learning model for metabolomics data, choosing the most suitable model can significantly affect the quality of predictions and subsequent metabolomics analyses. To address this challenge, we conducted a comparative analysis of nine machine learning models on three metabolomics data sets from cataract patients with and without dry eye disease. The models were evaluated and optimized using nested k-fold cross-validation. To assess the performance of these models, we selected a set of suitable evaluation metrics tailored to the data set's challenges. The logistic regression model overall performed the best, achieving the highest area under the curve score of 0.8378, balanced accuracy of 0.735, Matthew's correlation coefficient of 0.5147, an F1-score of 0.8513, and a specificity of 0.5667. Additionally, following the logistic regression, the XGBoost and Random Forest models also demonstrated good performance.
Principle Components Analysis based frameworks for efficient missing data imputation algorithms
May 30, 2022
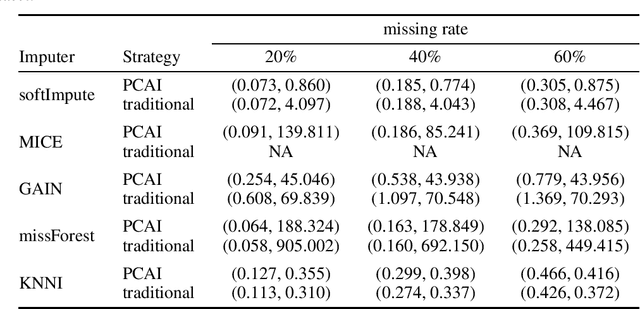
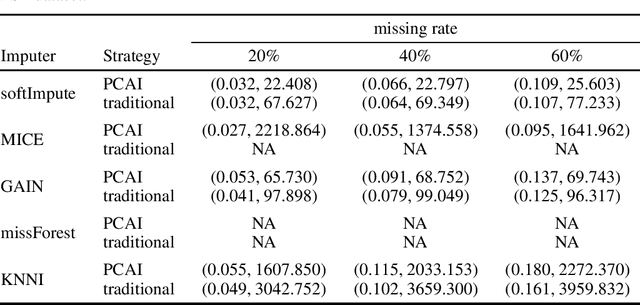
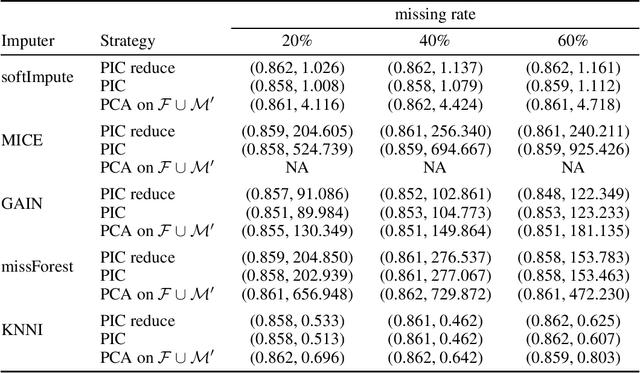
Missing data is a commonly occurring problem in practice, and imputation, i.e., filling the missing entries of the data, is a popular way to deal with this problem. This motivates multiple works on imputation to deal with missing data of various types and dimensions. However, for high-dimensional datasets, these imputation methods can be computationally expensive. Therefore, in this work, we propose Principle Component Analysis Imputation (PCAI), a simple framework based on Principle Component Analysis (PCA) to speed up the imputation process of many available imputation techniques. Next, based on PCAI, we propose PCA Imputation - Classification (PIC), an imputation-dimension reduction-classification framework to deal with missing data classification problems where it is desirable to reduce the dimensions before training a classification model. Our experiments show that the proposed frameworks can be utilized with various imputation algorithms and improve the imputation speed significantly. Interestingly, the frameworks aid imputation methods that rely on many parameters by reducing the dimension of the data and hence, reducing the number of parameters needed to be estimated. Moreover, they not only can achieve compatible mean square error/higher classification accuracy compared to the traditional imputation style on the original missing dataset but many times deliver even better results. In addition, the frameworks also help to tackle the memory issue that many imputation approaches have by reducing the number of features.