 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Components for Neural Network Initialization
Jan 31, 2025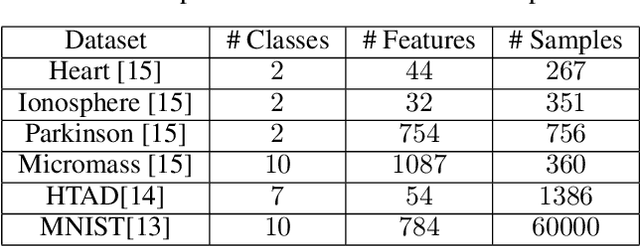
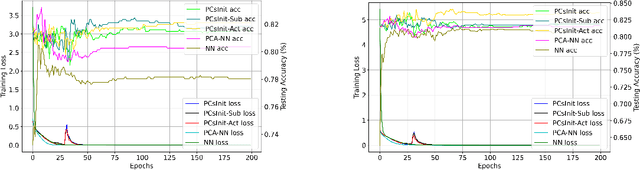
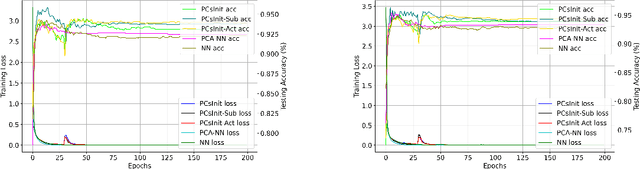
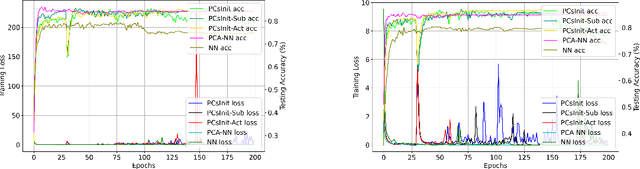
Principal Component Analysis (PCA) is a commonly used tool for dimension reduction and denoising. Therefore, it is also widely used on the data prior to training a neural network. However, this approach can complicate the explanation of explainable AI (XAI) methods for the decision of the model. In this work, we analyze the potential issues with this approach and propose Principal Components-based Initialization (PCsInit), a strategy to incorporate PCA into the first layer of a neural network via initialization of the first layer in the network with the principal components, and its two variants PCsInit-Act and PCsInit-Sub. Explanations using these strategies are as direct and straightforward as for neural networks and are simpler than using PCA prior to training a neural network on the principal components. Moreover, as will be illustrated in the experiments, such training strategies can also allow further improvement of training via backpropagation.
DPERC: Direct Parameter Estimation for Mixed Data
Jan 17, 2025

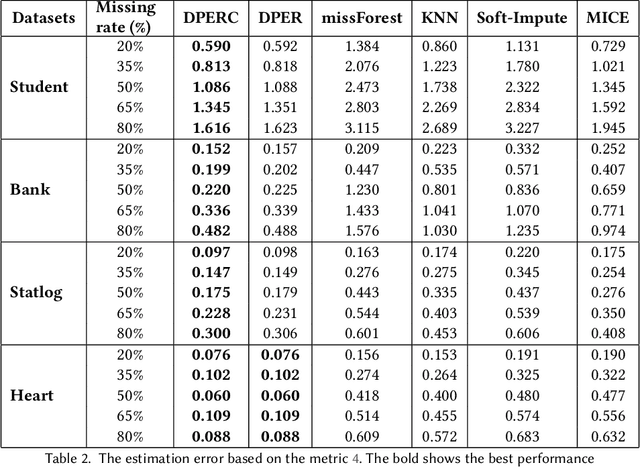
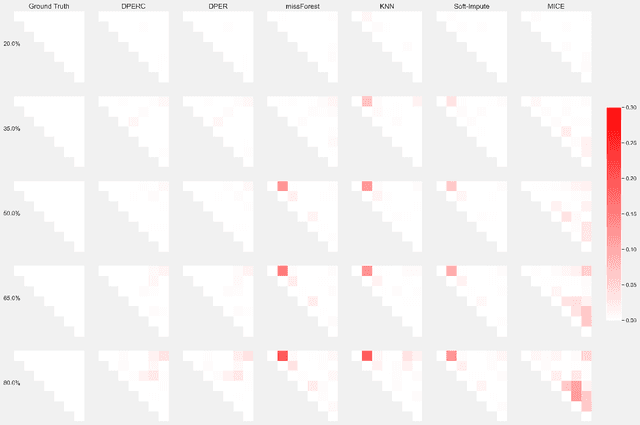
The covariance matrix is a foundation in numerous statistical and machine-learning applications such as Principle Component Analysis, Correlation Heatmap, etc. However, missing values within datasets present a formidable obstacle to accurately estimating this matrix. While imputation methods offer one avenue for addressing this challenge, they often entail a trade-off between computational efficiency and estimation accuracy. Consequently, attention has shifted towards direct parameter estimation, given its precision and reduced computational burden. In this paper, we propose Direct Parameter Estimation for Randomly Missing Data with Categorical Features (DPERC), an efficient approach for direct parameter estimation tailored to mixed data that contains missing values within continuous features. Our method is motivated by leveraging information from categorical features, which can significantly enhance covariance matrix estimation for continuous features. Our approach effectively harnesses the information embedded within mixed data structures. Through comprehensive evaluations of diverse datasets, we demonstrate the competitive performance of DPERC compared to various contemporary techniques. In addition, we also show by experiments that DPERC is a valuable tool for visualizing the correlation heatmap.
Missing data imputation for noisy time-series data and applications in healthcare
Dec 15, 2024


Healthcare time series data is vital for monitoring patient activity but often contains noise and missing values due to various reasons such as sensor errors or data interruptions. Imputation, i.e., filling in the missing values, is a common way to deal with this issue. In this study, we compare imputation methods, including Multiple Imputation with Random Forest (MICE-RF) and advanced deep learning approaches (SAITS, BRITS, Transformer) for noisy, missing time series data in terms of MAE, F1-score, AUC, and MCC, across missing data rates (10 % - 80 %). Our results show that MICE-RF can effectively impute missing data compared to deep learning methods and the improvement in classification of data imputed indicates that imputation can have denoising effects. Therefore, using an imputation algorithm on time series with missing data can, at the same time, offer denoising effects.
Weighted Missing Linear Discriminant Analysis: An Explainable Approach for Classification with Missing Data
Jun 30, 2024



As Artificial Intelligence (AI) models are gradually being adopted in real-life applications, the explainability of the model used is critical, especially in high-stakes areas such as medicine, finance, etc. Among the commonly used models, Linear Discriminant Analysis (LDA) is a widely used classification tool that is also explainable thanks to its ability to model class distributions and maximize class separation through linear feature combinations. Nevertheless, real-world data is frequently incomplete, presenting significant challenges for classification tasks and model explanations. In this paper, we propose a novel approach to LDA under missing data, termed \textbf{\textit{Weighted missing Linear Discriminant Analysis (WLDA)}}, to directly classify observations in data that contains missing values without imputation effectively by estimating the parameters directly on missing data and use a weight matrix for missing values to penalize missing entries during classification. Furthermore, we also analyze the theoretical properties and examine the explainability of the proposed technique in a comprehensive manner. Experimental results demonstrate that WLDA outperforms conventional methods by a significant margin, particularly in scenarios where missing values are present in both training and test sets.
Explainability of Machine Learning Models under Missing Data
Jun 29, 2024



Missing data is a prevalent issue that can significantly impair model performance and interpretability. This paper briefly summarizes the development of the field of missing data with respect to Explainable Artificial Intelligence and experimentally investigates the effects of various imputation methods on the calculation of Shapley values, a popular technique for interpreting complex machine learning models. We compare different imputation strategies and assess their impact on feature importance and interaction as determined by Shapley values. Moreover, we also theoretically analyze the effects of missing values on Shapley values. Importantly, our findings reveal that the choice of imputation method can introduce biases that could lead to changes in the Shapley values, thereby affecting the interpretability of the model. Moreover, and that a lower test prediction mean square error (MSE) may not imply a lower MSE in Shapley values and vice versa. Also, while Xgboost is a method that could handle missing data directly, using Xgboost directly on missing data can seriously affect interpretability compared to imputing the data before training Xgboost. This study provides a comprehensive evaluation of imputation methods in the context of model interpretation, offering practical guidance for selecting appropriate techniques based on dataset characteristics and analysis objectives. The results underscore the importance of considering imputation effects to ensure robust and reliable insights from machine learning models.
How Human-Centered Explainable AI Interface Are Designed and Evaluated: A Systematic Survey
Mar 21, 2024



Despite its technological breakthroughs, eXplainable Artificial Intelligence (XAI) research has limited success in producing the {\em effective explanations} needed by users. In order to improve XAI systems' usability, practical interpretability, and efficacy for real users, the emerging area of {\em Explainable Interfaces} (EIs) focuses on the user interface and user experience design aspects of XAI. This paper presents a systematic survey of 53 publications to identify current trends in human-XAI interaction and promising directions for EI design and development. This is among the first systematic survey of EI research.
Imputation using training labels and classification via label imputation
Nov 28, 2023



Missing data is a common problem in practical settings. Various imputation methods have been developed to deal with missing data. However, even though the label is usually available in the training data, the common practice of imputation usually only relies on the input and ignores the label. In this work, we illustrate how stacking the label into the input can significantly improve the imputation of the input. In addition, we propose a classification strategy that initializes the predicted test label with missing values and stacks the label with the input for imputation. This allows imputing the label and the input at the same time. Also, the technique is capable of handling data training with missing labels without any prior imputation and is applicable to continuous, categorical, or mixed-type data. Experiments show promising results in terms of accuracy.
Correlation visualization under missing values: a comparison between imputation and direct parameter estimation methods
May 10, 2023



Correlation matrix visualization is essential for understanding the relationships between variables in a dataset, but missing data can pose a significant challenge in estimating correlation coefficients. In this paper, we compare the effects of various missing data methods on the correlation plot, focusing on two common missing patterns: random and monotone. We aim to provide practical strategies and recommendations for researchers and practitioners in creating and analyzing the correlation plot. Our experimental results suggest that while imputation is commonly used for missing data, using imputed data for plotting the correlation matrix may lead to a significantly misleading inference of the relation between the features. We recommend using DPER, a direct parameter estimation approach, for plotting the correlation matrix based on its performance in the experiments.
Blockwise Principal Component Analysis for monotone missing data imputation and dimensionality reduction
May 10, 2023

Monotone missing data is a common problem in data analysis. However, imputation combined with dimensionality reduction can be computationally expensive, especially with the increasing size of datasets. To address this issue, we propose a Blockwise principal component analysis Imputation (BPI) framework for dimensionality reduction and imputation of monotone missing data. The framework conducts Principal Component Analysis (PCA) on the observed part of each monotone block of the data and then imputes on merging the obtained principal components using a chosen imputation technique. BPI can work with various imputation techniques and can significantly reduce imputation time compared to conducting dimensionality reduction after imputation. This makes it a practical and efficient approach for large datasets with monotone missing data. Our experiments validate the improvement in speed. In addition, our experiments also show that while applying MICE imputation directly on missing data may not yield convergence, applying BPI with MICE for the data may lead to convergence.
Conditional expectation for missing data imputation
Feb 02, 2023



Missing data is common in datasets retrieved in various areas, such as medicine, sports, and finance. In many cases, to enable proper and reliable analyses of such data, the missing values are often imputed, and it is necessary that the method used has a low root mean square error (RMSE) between the imputed and the true values. In addition, for some critical applications, it is also often a requirement that the logic behind the imputation is explainable, which is especially difficult for complex methods that are for example, based on deep learning. This motivates us to introduce a conditional Distribution based Imputation of Missing Values (DIMV) algorithm. This approach works based on finding the conditional distribution of a feature with missing entries based on the fully observed features. As will be illustrated in the paper, DIMV (i) gives a low RMSE for the imputed values compared to state-of-the-art methods under comparison; (ii) is explainable; (iii) can provide an approximated confidence region for the missing values in a given sample; (iv) works for both small and large scale data; (v) in many scenarios, does not require a huge number of parameters as deep learning approaches and therefore can be used for mobile devices or web browsers; and (vi) is robust to the normally distributed assumption that its theoretical grounds rely on. In addition to DIMV, we also introduce the DPER* algorithm improving the speed of DPER for estimating the mean and covariance matrix from the data, and we confirm the speed-up via experiments.