 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlurry-Consistency Segmentation Framework with Selective Stacking on Differential Interference Contrast 3D Breast Cancer Spheroid
Jun 08, 2024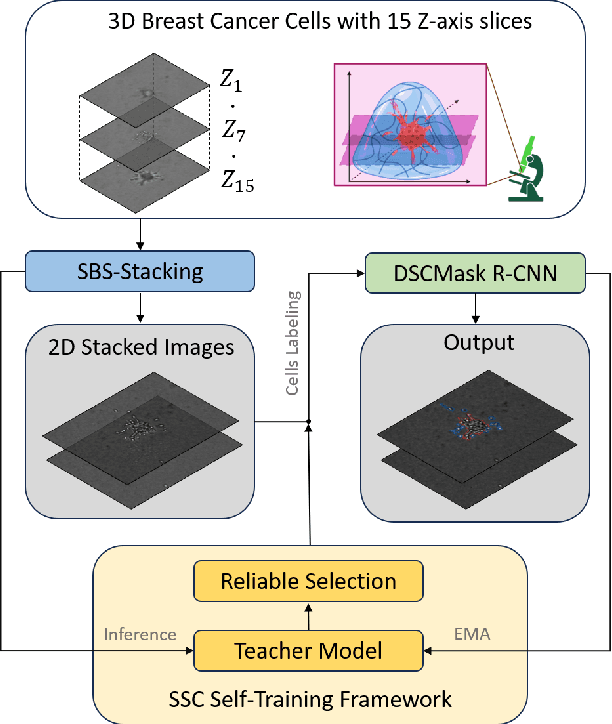
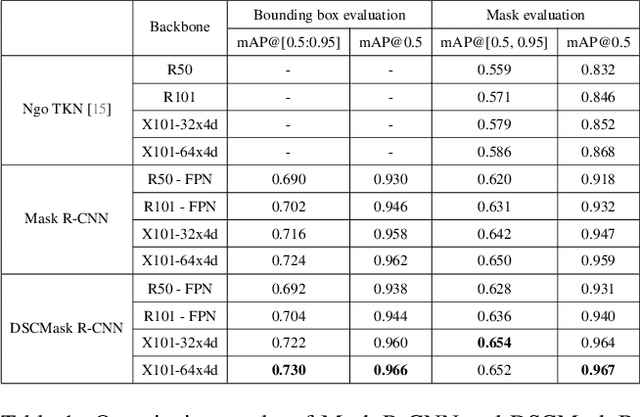
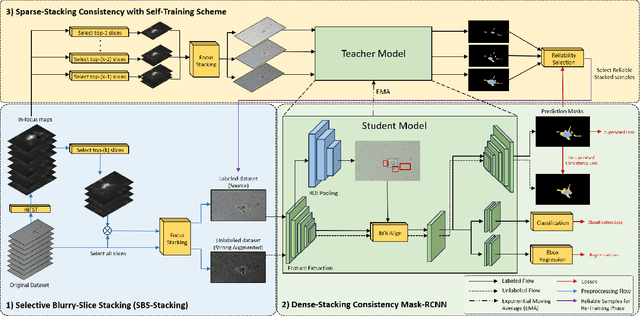

The ability of three-dimensional (3D) spheroid modeling to study the invasive behavior of breast cancer cells has drawn increased attention. The deep learning-based image processing framework is very effective at speeding up the cell morphological analysis process. Out-of-focus photos taken while capturing 3D cells under several z-slices, however, could negatively impact the deep learning model. In this work, we created a new algorithm to handle blurry images while preserving the stacked image quality. Furthermore, we proposed a unique training architecture that leverages consistency training to help reduce the bias of the model when dense-slice stacking is applied. Additionally, the model's stability is increased under the sparse-slice stacking effect by utilizing the self-training approach. The new blurring stacking technique and training flow are combined with the suggested architecture and self-training mechanism to provide an innovative yet easy-to-use framework. Our methods produced noteworthy experimental outcomes in terms of both quantitative and qualitative aspects.
Correlation visualization under missing values: a comparison between imputation and direct parameter estimation methods
May 10, 2023



Correlation matrix visualization is essential for understanding the relationships between variables in a dataset, but missing data can pose a significant challenge in estimating correlation coefficients. In this paper, we compare the effects of various missing data methods on the correlation plot, focusing on two common missing patterns: random and monotone. We aim to provide practical strategies and recommendations for researchers and practitioners in creating and analyzing the correlation plot. Our experimental results suggest that while imputation is commonly used for missing data, using imputed data for plotting the correlation matrix may lead to a significantly misleading inference of the relation between the features. We recommend using DPER, a direct parameter estimation approach, for plotting the correlation matrix based on its performance in the experiments.
Blockwise Principal Component Analysis for monotone missing data imputation and dimensionality reduction
May 10, 2023

Monotone missing data is a common problem in data analysis. However, imputation combined with dimensionality reduction can be computationally expensive, especially with the increasing size of datasets. To address this issue, we propose a Blockwise principal component analysis Imputation (BPI) framework for dimensionality reduction and imputation of monotone missing data. The framework conducts Principal Component Analysis (PCA) on the observed part of each monotone block of the data and then imputes on merging the obtained principal components using a chosen imputation technique. BPI can work with various imputation techniques and can significantly reduce imputation time compared to conducting dimensionality reduction after imputation. This makes it a practical and efficient approach for large datasets with monotone missing data. Our experiments validate the improvement in speed. In addition, our experiments also show that while applying MICE imputation directly on missing data may not yield convergence, applying BPI with MICE for the data may lead to convergence.
Conditional expectation for missing data imputation
Feb 02, 2023



Missing data is common in datasets retrieved in various areas, such as medicine, sports, and finance. In many cases, to enable proper and reliable analyses of such data, the missing values are often imputed, and it is necessary that the method used has a low root mean square error (RMSE) between the imputed and the true values. In addition, for some critical applications, it is also often a requirement that the logic behind the imputation is explainable, which is especially difficult for complex methods that are for example, based on deep learning. This motivates us to introduce a conditional Distribution based Imputation of Missing Values (DIMV) algorithm. This approach works based on finding the conditional distribution of a feature with missing entries based on the fully observed features. As will be illustrated in the paper, DIMV (i) gives a low RMSE for the imputed values compared to state-of-the-art methods under comparison; (ii) is explainable; (iii) can provide an approximated confidence region for the missing values in a given sample; (iv) works for both small and large scale data; (v) in many scenarios, does not require a huge number of parameters as deep learning approaches and therefore can be used for mobile devices or web browsers; and (vi) is robust to the normally distributed assumption that its theoretical grounds rely on. In addition to DIMV, we also introduce the DPER* algorithm improving the speed of DPER for estimating the mean and covariance matrix from the data, and we confirm the speed-up via experiments.
Traffic Density Estimation using a Convolutional Neural Network
Sep 05, 2018

The goal of this project is to introduce and present a machine learning application that aims to improve the quality of life of people in Singapore. In particular, we investigate the use of machine learning solutions to tackle the problem of traffic congestion in Singapore. In layman's terms, we seek to make Singapore (or any other city) a smoother place. To accomplish this aim, we present an end-to-end system comprising of 1. A traffic density estimation algorithm at traffic lights/junctions and 2. a suitable traffic signal control algorithms that make use of the density information for better traffic control. Traffic density estimation can be obtained from traffic junction images using various machine learning techniques (combined with CV tools). After research into various advanced machine learning methods, we decided on convolutional neural networks (CNNs). We conducted experiments on our algorithms, using the publicly available traffic camera dataset published by the Land Transport Authority (LTA) to demonstrate the feasibility of this approach. With these traffic density estimates, different traffic algorithms can be applied to minimize congestion at traffic junctions in general.