 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Whisper to Grade Them All
Jul 23, 2025We present an efficient end-to-end approach for holistic Automatic Speaking Assessment (ASA) of multi-part second-language tests, developed for the 2025 Speak & Improve Challenge. Our system's main novelty is the ability to process all four spoken responses with a single Whisper-small encoder, combine all information via a lightweight aggregator, and predict the final score. This architecture removes the need for transcription and per-part models, cuts inference time, and makes ASA practical for large-scale Computer-Assisted Language Learning systems. Our system achieved a Root Mean Squared Error (RMSE) of 0.384, outperforming the text-based baseline (0.44) while using at most 168M parameters (about 70% of Whisper-small). Furthermore, we propose a data sampling strategy, allowing the model to train on only 44.8% of the speakers in the corpus and still reach 0.383 RMSE, demonstrating improved performance on imbalanced classes and strong data efficiency.
Principal Components for Neural Network Initialization
Jan 31, 2025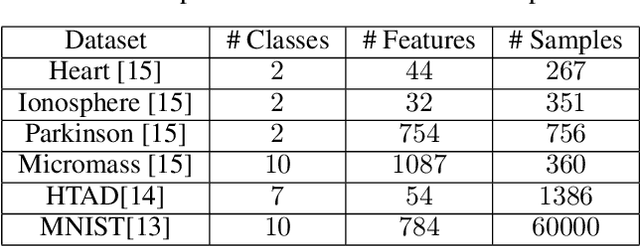
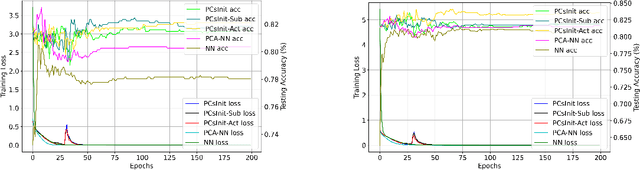
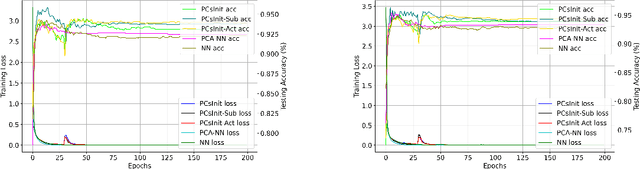
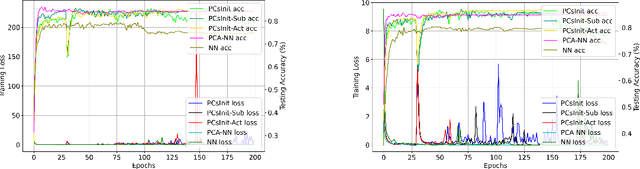
Principal Component Analysis (PCA) is a commonly used tool for dimension reduction and denoising. Therefore, it is also widely used on the data prior to training a neural network. However, this approach can complicate the explanation of explainable AI (XAI) methods for the decision of the model. In this work, we analyze the potential issues with this approach and propose Principal Components-based Initialization (PCsInit), a strategy to incorporate PCA into the first layer of a neural network via initialization of the first layer in the network with the principal components, and its two variants PCsInit-Act and PCsInit-Sub. Explanations using these strategies are as direct and straightforward as for neural networks and are simpler than using PCA prior to training a neural network on the principal components. Moreover, as will be illustrated in the experiments, such training strategies can also allow further improvement of training via backpropagation.
Conditional expectation for missing data imputation
Feb 02, 2023



Missing data is common in datasets retrieved in various areas, such as medicine, sports, and finance. In many cases, to enable proper and reliable analyses of such data, the missing values are often imputed, and it is necessary that the method used has a low root mean square error (RMSE) between the imputed and the true values. In addition, for some critical applications, it is also often a requirement that the logic behind the imputation is explainable, which is especially difficult for complex methods that are for example, based on deep learning. This motivates us to introduce a conditional Distribution based Imputation of Missing Values (DIMV) algorithm. This approach works based on finding the conditional distribution of a feature with missing entries based on the fully observed features. As will be illustrated in the paper, DIMV (i) gives a low RMSE for the imputed values compared to state-of-the-art methods under comparison; (ii) is explainable; (iii) can provide an approximated confidence region for the missing values in a given sample; (iv) works for both small and large scale data; (v) in many scenarios, does not require a huge number of parameters as deep learning approaches and therefore can be used for mobile devices or web browsers; and (vi) is robust to the normally distributed assumption that its theoretical grounds rely on. In addition to DIMV, we also introduce the DPER* algorithm improving the speed of DPER for estimating the mean and covariance matrix from the data, and we confirm the speed-up via experiments.
Combining datasets to increase the number of samples and improve model fitting
Oct 11, 2022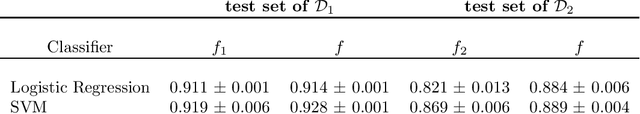

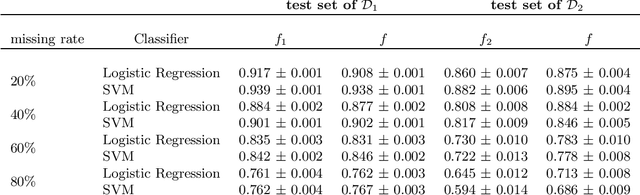
For many use cases, combining information from different datasets can be of interest to improve a machine learning model's performance, especially when the number of samples from at least one of the datasets is small. However, a potential challenge in such cases is that the features from these datasets are not identical, even though there are some commonly shared features among the datasets. To tackle this challenge, we propose a novel framework called Combine datasets based on Imputation (ComImp). In addition, we propose a variant of ComImp that uses Principle Component Analysis (PCA), PCA-ComImp in order to reduce dimension before combining datasets. This is useful when the datasets have a large number of features that are not shared between them. Furthermore, our framework can also be utilized for data preprocessing by imputing missing data, i.e., filling in the missing entries while combining different datasets. To illustrate the power of the proposed methods and their potential usages, we conduct experiments for various tasks: regression, classification, and for different data types: tabular data, time series data, when the datasets to be combined have missing data. We also investigate how the devised methods can be used with transfer learning to provide even further model training improvement. Our results indicate that the proposed methods are somewhat similar to transfer learning in that the merge can significantly improve the accuracy of a prediction model on smaller datasets. In addition, the methods can boost performance by a significant margin when combining small datasets together and can provide extra improvement when being used with transfer learning.
Finnish Parliament ASR corpus - Analysis, benchmarks and statistics
Mar 28, 2022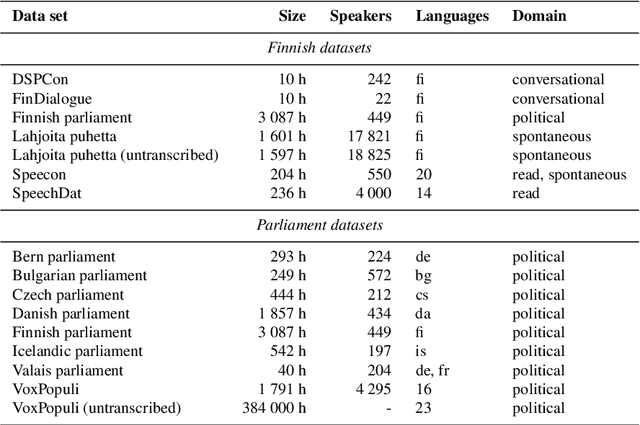
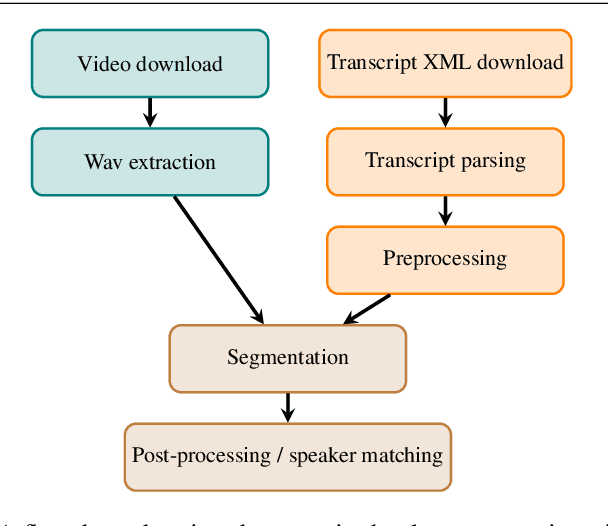
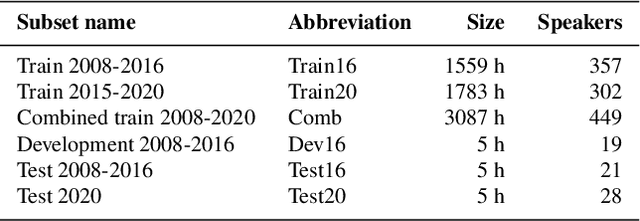
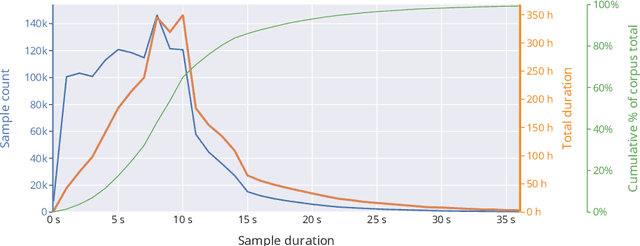
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.