 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinnish Parliament ASR corpus - Analysis, benchmarks and statistics
Paper and Code
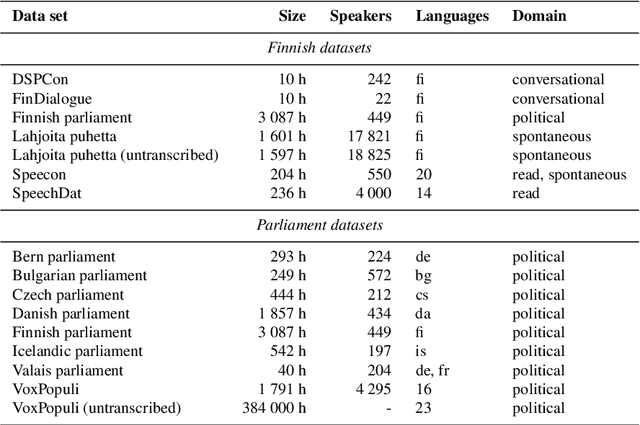
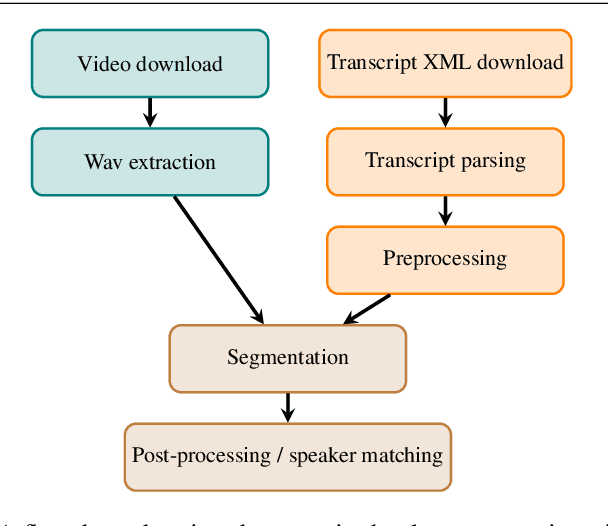
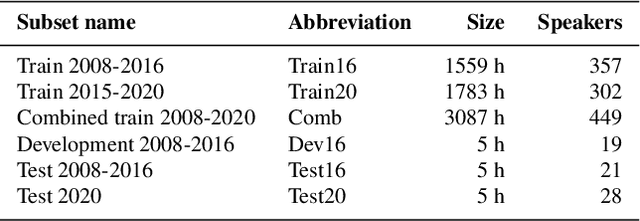
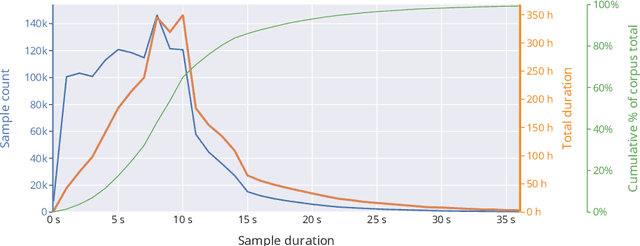
Public sources like parliament meeting recordings and transcripts provide ever-growing material for the training and evaluation of automatic speech recognition (ASR) systems. In this paper, we publish and analyse the Finnish parliament ASR corpus, the largest publicly available collection of manually transcribed speech data for Finnish with over 3000 hours of speech and 449 speakers for which it provides rich demographic metadata. This corpus builds on earlier initial work, and as a result the corpus has a natural split into two training subsets from two periods of time. Similarly, there are two official, corrected test sets covering different times, setting an ASR task with longitudinal distribution-shift characteristics. An official development set is also provided. We develop a complete Kaldi-based data preparation pipeline, and hidden Markov model (HMM), hybrid deep neural network (HMM-DNN) and attention-based encoder-decoder (AED) ASR recipes. We set benchmarks on the official test sets, as well as multiple other recently used test sets. Both temporal corpus subsets are already large, and we observe that beyond their scale, ASR performance on the official test sets plateaus, whereas other domains benefit from added data. The HMM-DNN and AED approaches are compared in a carefully matched equal data setting, with the HMM-DNN system consistently performing better. Finally, the variation of the ASR accuracy is compared between the speaker categories available in the parliament metadata to detect potential biases based on factors such as gender, age, and education.