 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability of Complex AI Models with Correlation Impact Ratio
Jan 10, 2026Complex AI systems make better predictions but often lack transparency, limiting trustworthiness, interpretability, and safe deployment. Common post hoc AI explainers, such as LIME, SHAP, HSIC, and SAGE, are model agnostic but are too restricted in one significant regard: they tend to misrank correlated features and require costly perturbations, which do not scale to high dimensional data. We introduce ExCIR (Explainability through Correlation Impact Ratio), a theoretically grounded, simple, and reliable metric for explaining the contribution of input features to model outputs, which remains stable and consistent under noise and sampling variations. We demonstrate that ExCIR captures dependencies arising from correlated features through a lightweight single pass formulation. Experimental evaluations on diverse datasets, including EEG, synthetic vehicular data, Digits, and Cats-Dogs, validate the effectiveness and stability of ExCIR across domains, achieving more interpretable feature explanations than existing methods while remaining computationally efficient. To this end, we further extend ExCIR with an information theoretic foundation that unifies the correlation ratio with Canonical Correlation Analysis under mutual information bounds, enabling multi output and class conditioned explainability at scale.
DREAMS: A python framework to train deep learning models with model card reporting for medical and health applications
Sep 26, 2024



Electroencephalography (EEG) data provides a non-invasive method for researchers and clinicians to observe brain activity in real time. The integration of deep learning techniques with EEG data has significantly improved the ability to identify meaningful patterns, leading to valuable insights for both clinical and research purposes. However, most of the frameworks so far, designed for EEG data analysis, are either too focused on pre-processing or in deep learning methods per, making their use for both clinician and developer communities problematic. Moreover, critical issues such as ethical considerations, biases, uncertainties, and the limitations inherent in AI models for EEG data analysis are frequently overlooked, posing challenges to the responsible implementation of these technologies. In this paper, we introduce a comprehensive deep learning framework tailored for EEG data processing, model training and report generation. While constructed in way to be adapted and developed further by AI developers, it enables to report, through model cards, the outcome and specific information of use for both developers and clinicians. In this way, we discuss how this framework can, in the future, provide clinical researchers and developers with the tools needed to create transparent and accountable AI models for EEG data analysis and diagnosis.
Combining datasets to increase the number of samples and improve model fitting
Oct 11, 2022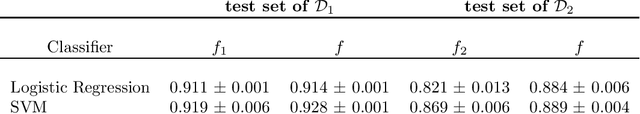

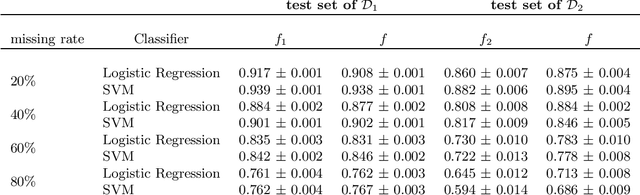
For many use cases, combining information from different datasets can be of interest to improve a machine learning model's performance, especially when the number of samples from at least one of the datasets is small. However, a potential challenge in such cases is that the features from these datasets are not identical, even though there are some commonly shared features among the datasets. To tackle this challenge, we propose a novel framework called Combine datasets based on Imputation (ComImp). In addition, we propose a variant of ComImp that uses Principle Component Analysis (PCA), PCA-ComImp in order to reduce dimension before combining datasets. This is useful when the datasets have a large number of features that are not shared between them. Furthermore, our framework can also be utilized for data preprocessing by imputing missing data, i.e., filling in the missing entries while combining different datasets. To illustrate the power of the proposed methods and their potential usages, we conduct experiments for various tasks: regression, classification, and for different data types: tabular data, time series data, when the datasets to be combined have missing data. We also investigate how the devised methods can be used with transfer learning to provide even further model training improvement. Our results indicate that the proposed methods are somewhat similar to transfer learning in that the merge can significantly improve the accuracy of a prediction model on smaller datasets. In addition, the methods can boost performance by a significant margin when combining small datasets together and can provide extra improvement when being used with transfer learning.